- 1.Dubbo运行流程
- 2.Dubbo的六大核心功能:
- 3.Dubbo配置-超时、重试、灰度发布、启动检查等
- 4、Dubbo高可用
- 5、Dubbo负载均衡有几种,默认是什么
- 6、Dubbo服务熔断降级有如何实现,容错机制有几种
- 服务降级?(不常用,有sentinel Alibaba系的)">1.什么是服务降级?(不常用,有sentinel Alibaba系的)
- 2. 集群容错(默认是failover失败自动切换)
- 7、SpringCloud 和 Dubbo 区别(面试题)
- 8、Eureka和Nacos区别(面试题)
- false为永久实例,true表示临时实例开启,注册为临时实例
spring.cloud.nacos.discovery.ephemeral=true
1
2
连接方式
nacs使用的是netty和服务直接进行连接,属于长连接
eureka是使用定时发送和服务进行联系,属于短连接
操作实例方式
nacos:提供了nacos console可视化控制话界面,可以对实例列表进行监听,对实例进行上下线,权重的配置,并且config server提供了对服务实例提供配置中心,且可以对配置进行CRUD,版本管理
今日任务:笔记提交到文档
1、掌握Dubbo运行流程
2、掌握Dubbo配置-超时、重试、灰度发布、启动检查等
3、Dubbo负载均衡有几种,默认是什么
4、Dubbo服务熔断降级有如何实现,容错机制有几种
5、SpringCloud 和 Dubbo 区别(面试题)
6、Eureka和Nacos区别
7、学会读官网文档:https://dubbo.apache.org/zh/docsv2.7/user/preface/
8 http工作网络7层模型的 应用层, rpc工作网络层
课下:搜网络7层模型 (记忆)
优先级:
1、代码敲完
2、整理笔记,上传到文档
3、sql语句: 2-5道,https://www.jianshu.com/p/476b52ee4f1b
当天的知识点细节:
Dubbo的调用实体类一定要实现序列化。
1.Dubbo运行流程
图集: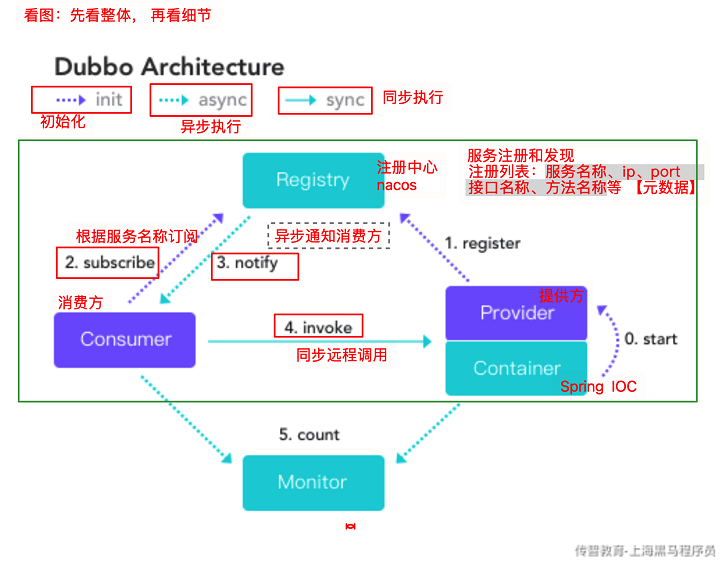
1.提供方注册到nacos上;
2.消费方根据服务名称去订阅
3.通过异步通知消费方
4.同步远程调用
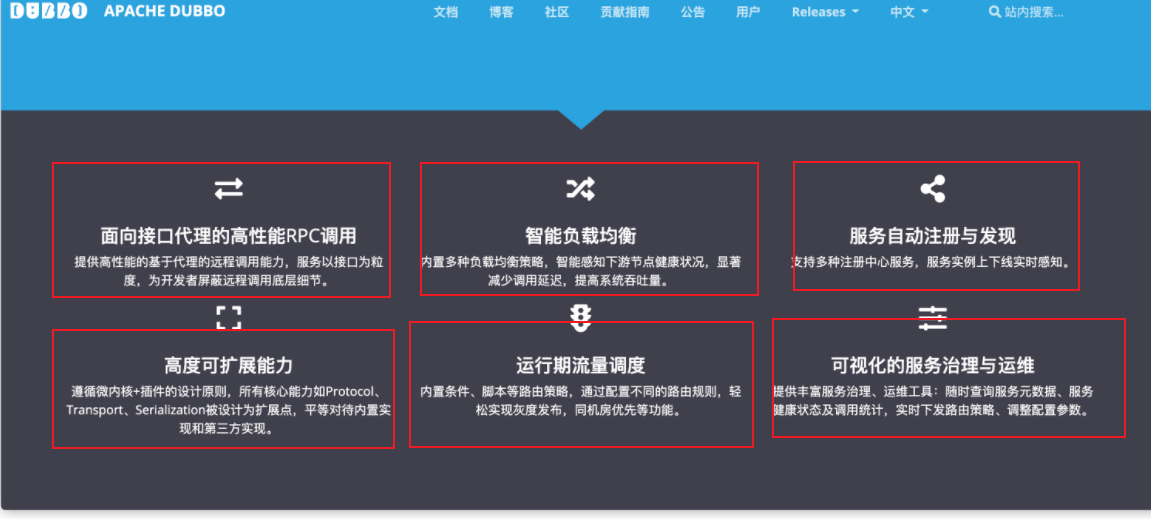
2.Dubbo的六大核心功能:
3.Dubbo配置-超时、重试、灰度发布、启动检查等
3.1超时时间:
由于网络或服务端不可靠,会导致调用出现一种不确定的中间状态(超时)。为了避免超时导致客户端资源(线程)挂起耗尽,必须设置超时时间。默认调用的时间是 1s。
同一个级别下,消费者>提供者
不同的级别下,方法>接口>通用配置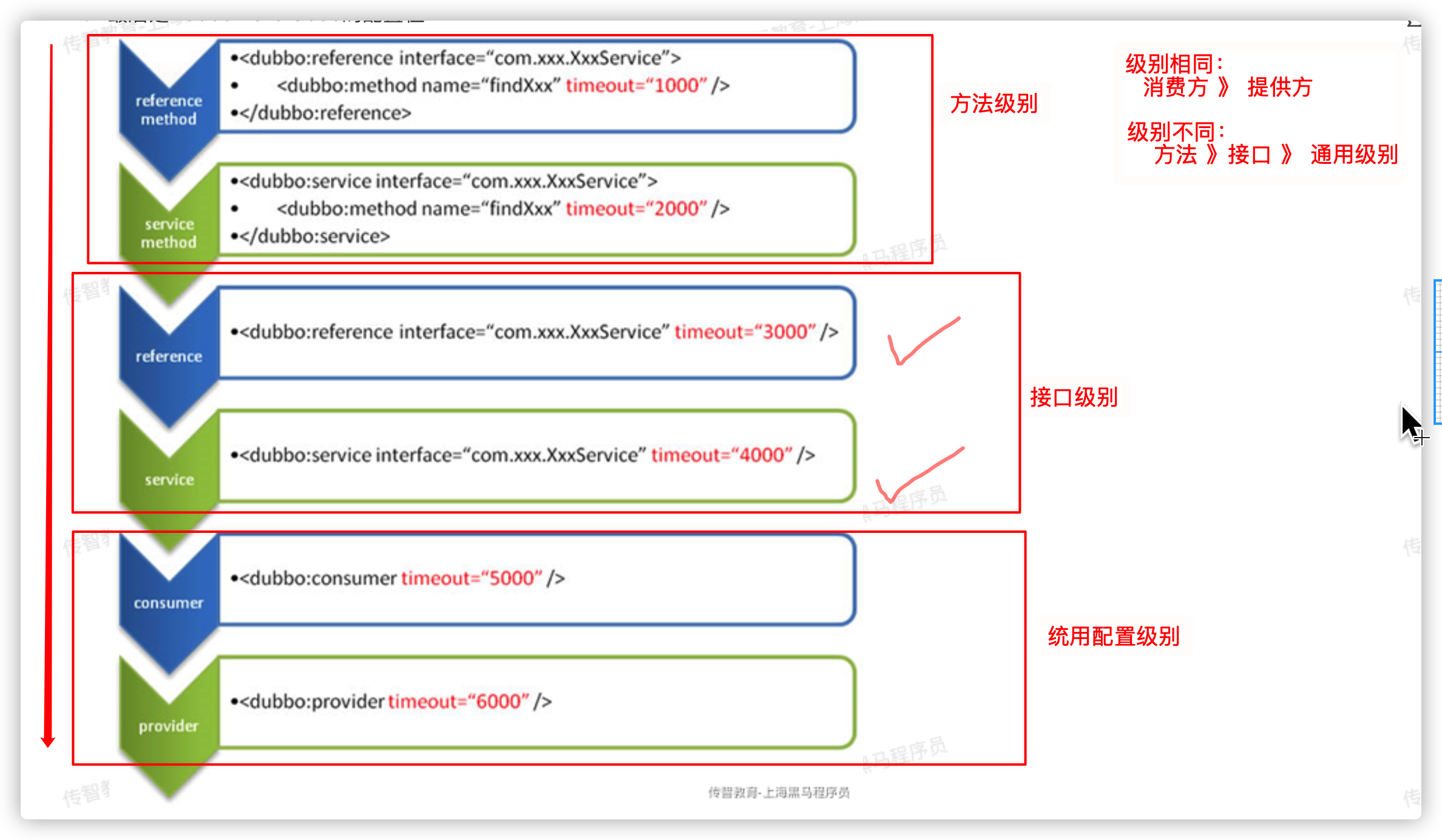
为什么要使用这么多的配置呢?
(作为提供者而言更了解本身的一个情况,而消费者可以依靠需求去改变,多以可以有很多的地方去配置,优先级也各有不同)
1、作服务的提供者,比服务使用方更清楚服务性能参数,如调用的超时时间,合理的重试次数,等等
2、在Provider配置后,Consumer不配置则会使用Provider的配置值,即Provider配置可以作为Consumer的缺省值。否则,Consumer会使用Consumer端的全局设置,这对于Provider不可控的,并且往往是不合理的
==配置的覆盖规则:==
1) 方法级配置别优于接口级别,即小Scope优先
2) Consumer端配置 优于 Provider配置 优于 全局配置
3.2重试次数
失败自动切换,当出现失败,重试其它服务器,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数(不含第一次)。
retries=””:重试次数,不包含第一次调用,0代表不重试。
关于幂等性操作(设置重试次数)【查询、删除、修改】、非幂等(不能设置重试次数)【新增】
注意:
- 重试:只有我们远程调用失败异常时,触发重试次数
- Dubbo 默认的重试次数2次
- //幂等性: 相同的url 无论请求多少次,结果都是一致的(查询GET,删除DELETE,表单修改PUT)
- //非幂等:新增,修改(POST)
- 新增:重试情况下可能会出现多条记录的问题
- 重试次数不建议设置的过多,建议重试次数不大于2次
- 服务器会因为重试多大量的并发请求,服务器会宕机现象
3.3灰度发布
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。可以按照以下的步骤进行版本迁移:
(实际开发可以根据不同的业务需求可以改变)
步骤:
在低压力时间段,先升级一半提供者为新版本
再将所有消费者升级为新版本
然后将剩下的一半提供者升级为新版本
3.4上下文信息
RpcContext 是一个 ThreadLocal 的临时状态记录器,当接收到 RPC 请求,或发起 RPC 请求时,RpcContext 的状态都会变化。比如:A 调 B,B 再调 C,则 B 机器上,在 B 调 C 之前,RpcContext 记录的是 A 调 B 的信息,在 B 调 C 之后,RpcContext 记录的是 B 调 C 的信息。
A-B B-C RpcContext 的值会发生改变
小结:Dubbo上下文对象用于存储调用链路中的数据环境信息
3.5隐式传参
通过 Dubbo 中的 Attachment 在服务消费方和提供方之间隐式传递参数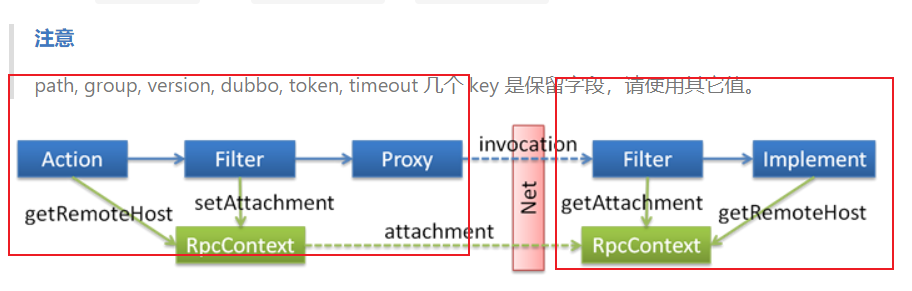
显性的是通过传参以及一些实体类传过去的,隐式是ThreadLocal的RpcContext;
4、Dubbo高可用
4.1面试题:
1.nacos如果宕机的话:dubbo还能调用成功吗?
现象:nacos注册中心宕机,还可以消费dubbo暴露的服务。
为什么?
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
2.Dubbo里面没有注册中心nacos可以吗?
可以的,可以通过dubbo 直连方式调用,绕过nacos注册中心实现:
直接在消费方调用的地方提供Dubbo的地址及端口号
(实际开发不用,用的话集群没办法使用了)
3.注册中心是否可以替换? 如果可以替换那么可以用什么来替换? 为什么?
支持替换:nacos,redis(发布/订阅),zookeeper(eraka不行,dubbo是一直在跟新,eraka已经被淘汰了)
mq不支持(应该可以,但是Dubbo不支持)
4.redis作为注册中心的原因是什么? 数据结构是什么内容是什么? 怎么实现?
Hash数据结构,主键+辅键 +value(过期时间)
主键:全限定类名+cusumer/priduster
辅健:服务的id 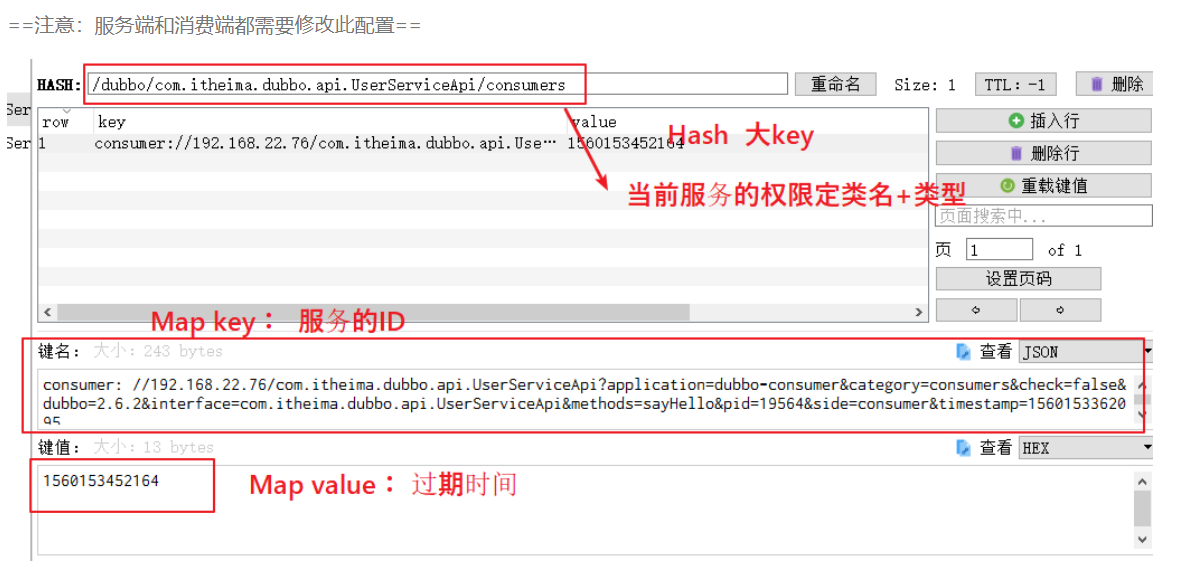 redis配置到服务中:
redis配置到服务中: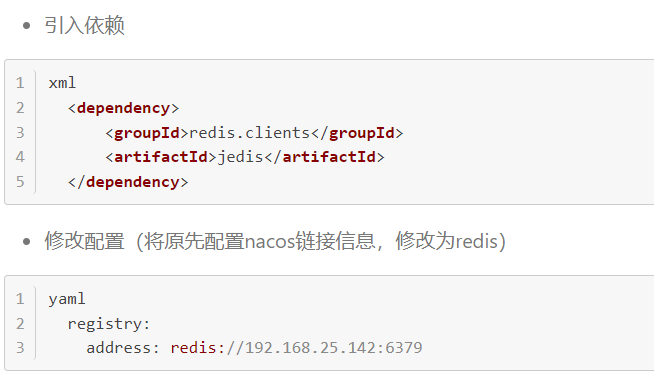
5、Dubbo负载均衡有几种,默认是什么
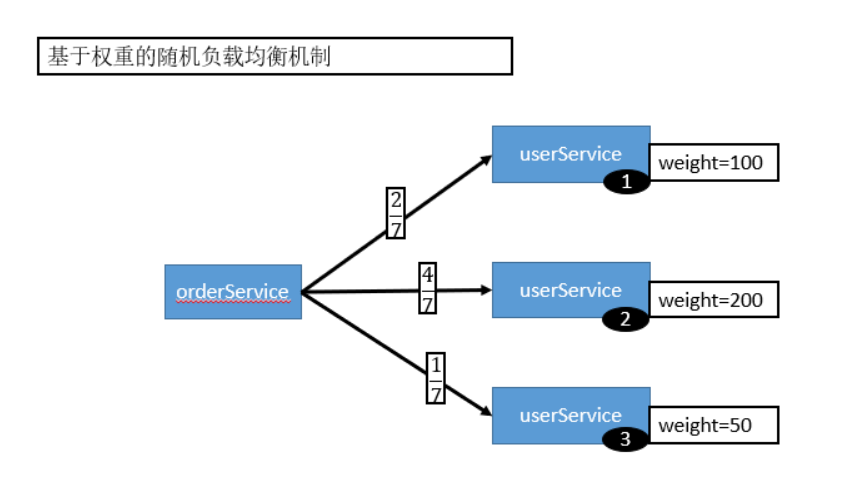
5.1.1 Random LoadBalance(默认的按照权重的随机)
5.1.2 RoundRobin LoadBalance
轮循,按公约后的权重设置轮循比率。存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。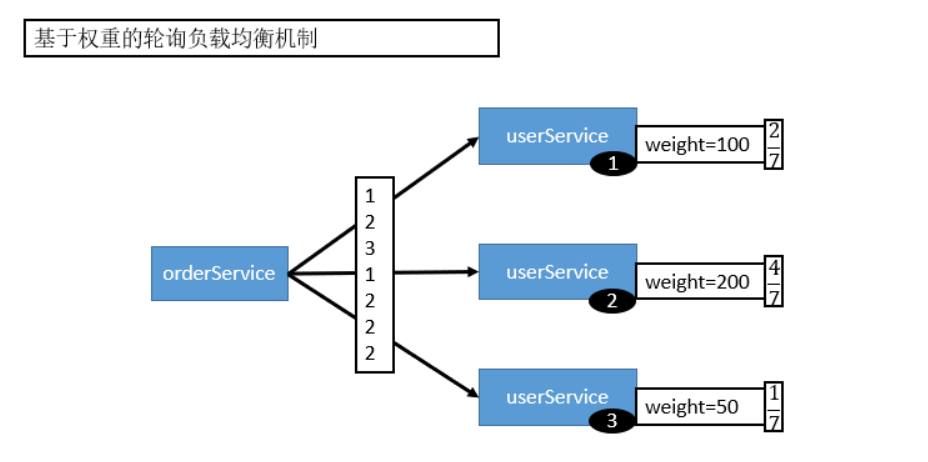
5.1.3 LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
数字是处理时间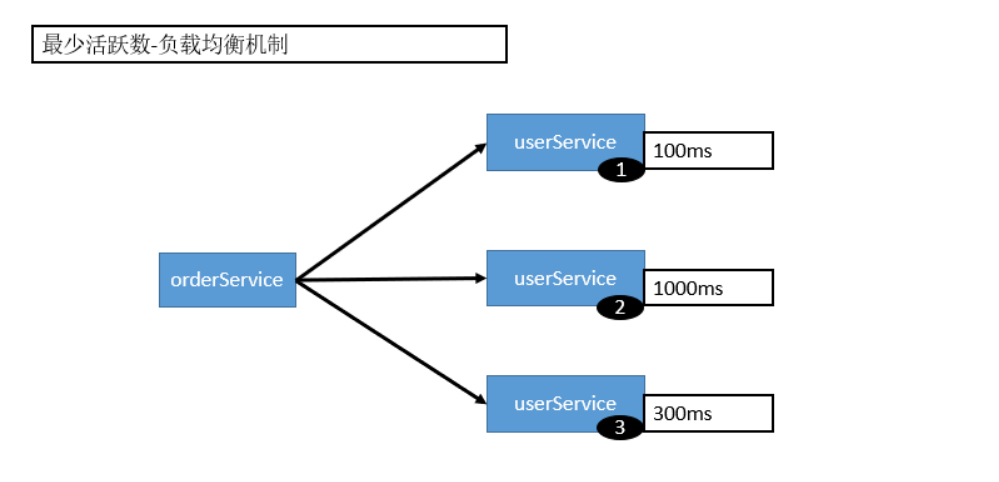
5.1.4 ConsistentHash LoadBalance
一致性 Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。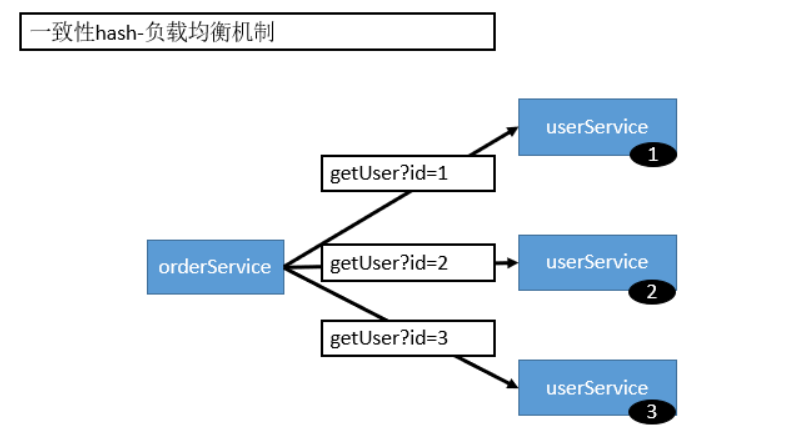
6、Dubbo服务熔断降级有如何实现,容错机制有几种
1.什么是服务降级?(不常用,有sentinel Alibaba系的)
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
(sentinel)阿里巴巴的
其中:
- mock=force:return null 表示==消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。==用来屏蔽不重要服务不可用时对调用方的影响。
- 还可以改为 mock=fail:return null ==表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。==用来容忍不重要服务不稳定时对调用方的影响。
2. 集群容错(默认是failover失败自动切换)
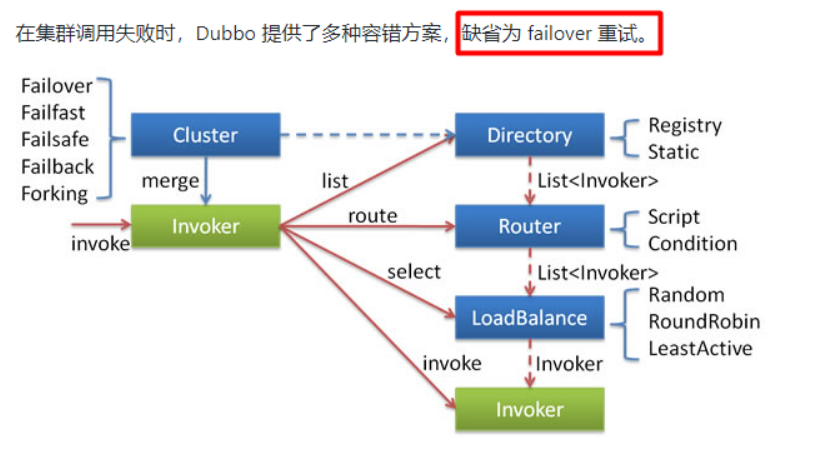
五种解决方案:
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。
7、SpringCloud 和 Dubbo 区别(面试题)
https://blog.csdn.net/djrm11/article/details/106431170/(对比太多了)
8、Eureka和Nacos区别(面试题)
CAP理论
C一致性,A高可用,P分区容错性
eureka只支持AP
nacos支持CP和AP两种
nacos是根据配置识别CP或AP模式,如果注册Nacos的client节点注册时是ephemeral=true即为临时节点,那么Naocs集群对这个client节点效果就是AP,反之则是CP,即不是临时节点
false为永久实例,true表示临时实例开启,注册为临时实例
spring.cloud.nacos.discovery.ephemeral=true
1
2
连接方式
nacs使用的是netty和服务直接进行连接,属于长连接
eureka是使用定时发送和服务进行联系,属于短连接
操作实例方式
nacos:提供了nacos console可视化控制话界面,可以对实例列表进行监听,对实例进行上下线,权重的配置,并且config server提供了对服务实例提供配置中心,且可以对配置进行CRUD,版本管理
eureka:仅提供了实例列表,实例的状态,错误信息,相比于nacos过于简单
自我保护机制
相同点:保护阈值都是个比例,0-1 范围,表示健康的 instance 占全部instance 的比例。
不同点:
1)保护方式不同
Eureka保护方式:当在短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下,Eureka Server不会剔除任何的微服务,等到正常后,再退出自我保护机制。自我保护开关(eureka.server.enable-self-preservation: false)
Nacos保护方式:当域名健康实例 (Instance) 占总服务实例(Instance) 的比例小于阈值时,无论实例 (Instance) 是否健康,都会将这个实例 (Instance) 返回给客户端。这样做虽然损失了一部分流量,但是保证了集群的剩余健康实例 (Instance) 能正常工作。
2)范围不同
Nacos 的阈值是针对某个具体 Service 的,而不是针对所有服务的。但 Eureka的自我保护阈值是针对所有服务的。

若有收获,就点个赞吧
0 人点赞
