1.官方文档(自己看)
- 官方网站:官网
- 文档地址:链接
2. 在考虑分库分表前,需要做的事情:真的要采用分库分表?
需要注意的是,分库分表会为数据库维护和业务逻辑带来一系列复杂性和性能损耗,除非预估的业务量大到万不得已,切莫过度设计、过早优化。 规划期内的数据量和性能问题
尝试能否用下列方式解决:
在业务量不大时,单库单表即可支撑。 当数据量过大存储不下、或者并发量过大负荷不起时,就要考虑分库分表
●当前数据量:如果没有达到几百万,通常无需分库分表;
●数据量问题:增加磁盘、增加分库(不同的业务功能表,整表拆分至不同的数据库);
●性能问题:升级CPU/内存、读写分离、优化数据库系统配置、优化数据表/索引、优化 SQL、分区、数据表的垂直切分;
●如果仍未能奏效,才考虑最复杂的方案:数据表的水平切分。
3. Sharding-JDBC的简介:(解决了什么问题:)
●磁盘IO的开销问题,单库情况下无法承载过多的访问
●所有的用户数据都存放在同一个表中,mysql单表可以存储 2^32条,但查询的时候效率比较低,单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表
●业务的边界不清晰,专库专用
虽然我们对应用系统做了大量的微服务处理,提升了系统在应用体系上的吞吐量,但是随着业务的越来越多,我们的数据库势必有不堪重负的一天,那么我们是怎么处理数据层的问题呢?这里就需要采用分库分表的策略来处理:
Sharding-jdbc是ShardingSphere的其中一个模块,定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
4. 分库分表方式
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
1、垂直分表
名词解释:将一个表按照字段分成多表,每个表存储其中一部分字段
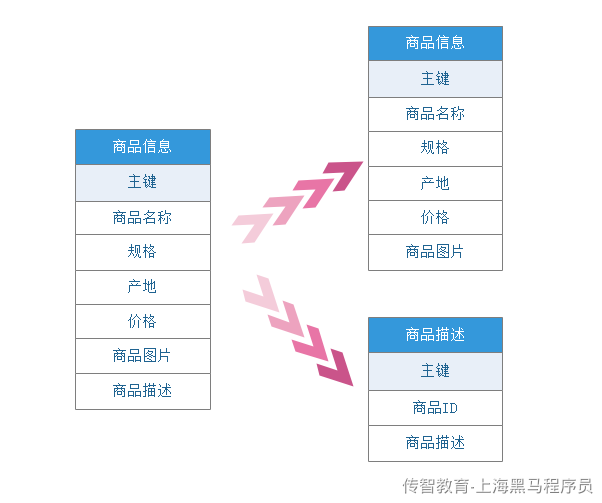
它带来的提升是:
●为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
●充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
●改变了数据库的表结构,对数据存储的行数没有影响
垂直拆分原则:
1把不常用的字段单独放在一张表;
2把text,blob等大字段拆分出来放在附表中;
3经常组合查询的列放在一张表中;
2、垂直分库
名词解释:垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,它的核心理念 是专库专用。
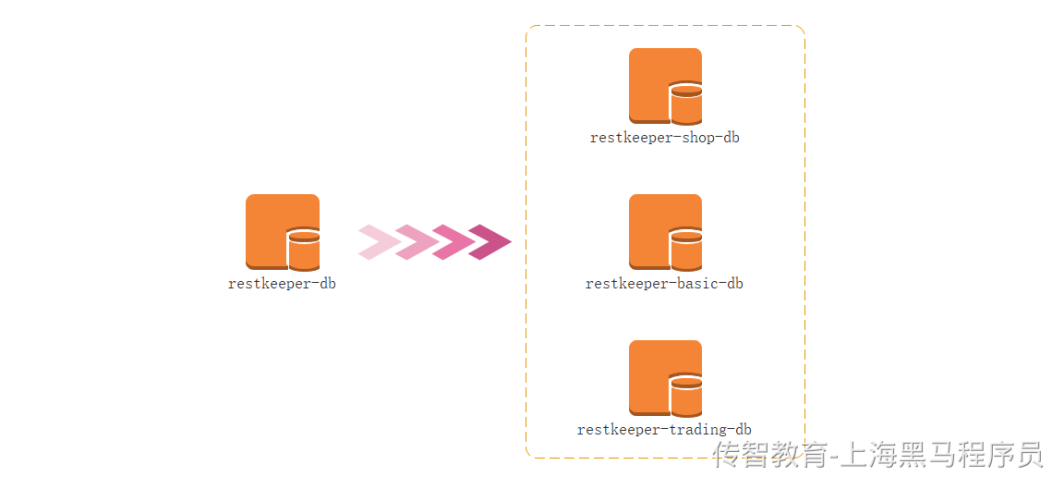
它带来的提升是:
●解决业务层面的耦合,业务清晰
●能对不同业务的数据进行分级管理、维护、监控、扩展等
●高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
3、水平分库
名词解释:是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,单库存储数据已经超出预估。
以电商网站为例:有8w店铺,每个店铺平均150个不同规格的商品,再算上增长,那商品数量得往1500w+上预估,并且商品库属于访问非常频繁的资源,单台服务器已经无法支撑。此时该如何优化?
再次分库?但是从业务角度分析,目前情况已经无法再次垂直分库。
水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构。
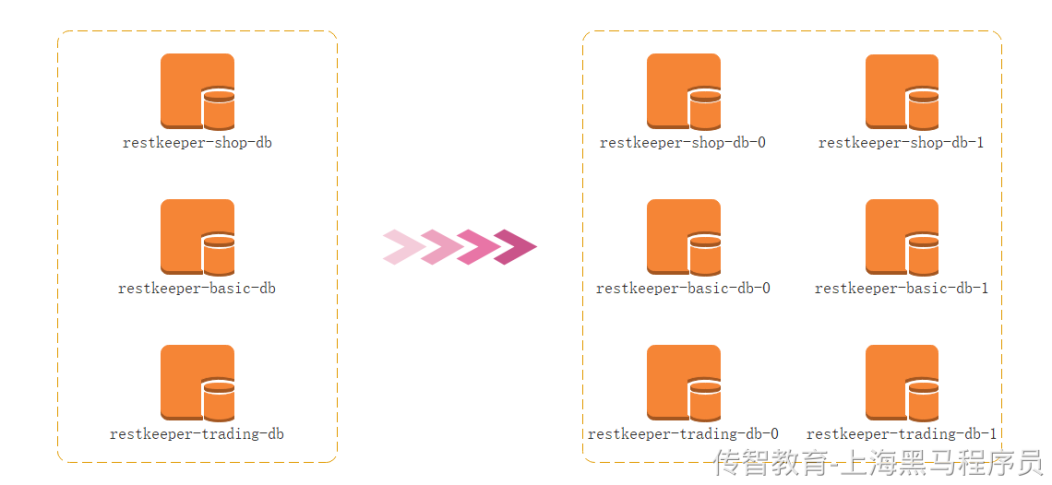
思考:如何存储和访问数据库呢?
它带来的提升是:
●解决了单库单表大数据,高并发的性能瓶颈。
●提高了系统的稳定性及可用性
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
4、水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
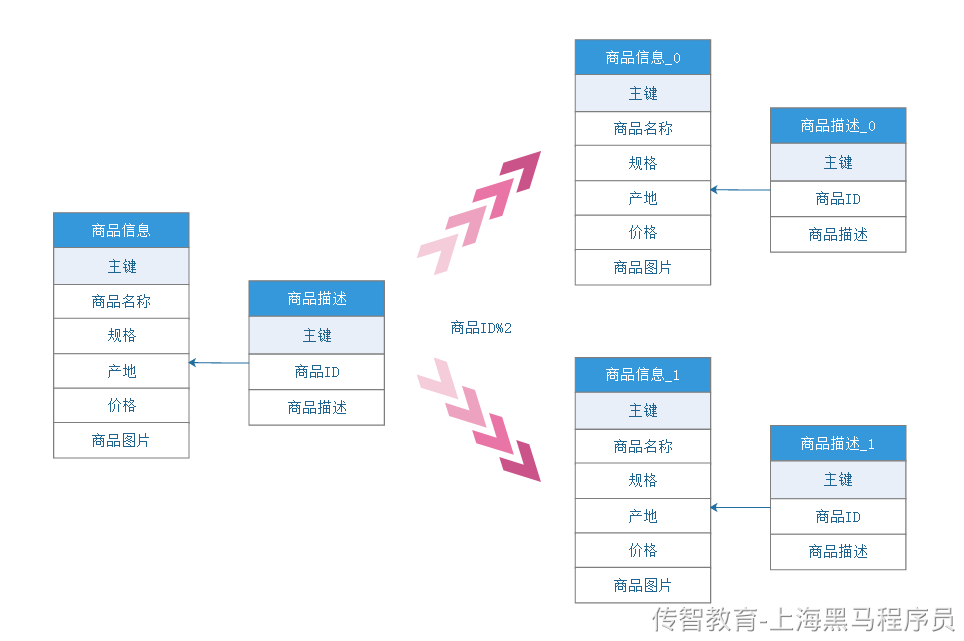
思考:如何存储和访问数据库中的表呢?
它带来的提升是:
●优化单一表数据量过大而产生的性能问题
●避免IO争抢并减少锁表的几率
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
注意:水平分库和水平分表的字段不能使用同一个
5、分库分表带来的问题
分库分表能有效的缓解了单机和单库带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来了一些问题。
●事务一致性问题
●跨节点关联查询
●跨节点分页、排序函数
●主键避重
●公共表
6、小结
分库分表方式:垂直分表、垂直分库、水平分库和水平分表
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
最佳实践:
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
7. sharding-jdbc-集成并处理分布式事务
官网参考:https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction
1.1、XA事务使用sharding-jdbc
以 model-shop-applet 项目为例
我们使用sharding-jdbc的时候只需要依赖: framework-sharding-jdbc 模块
1、排除druid-spring-boot-starter和sharding-transaction-base-seata-at的jar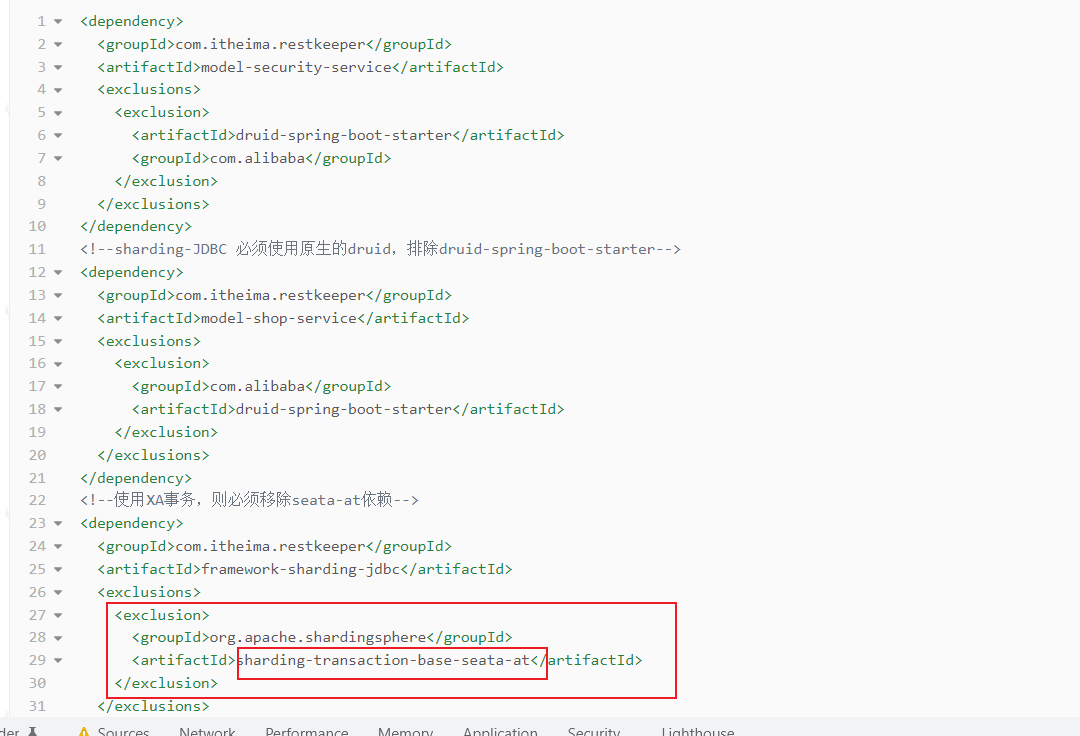
排除数据源原因:将数据源创建交由Sharding-JDBC管理,参考官网
2、然后在model-shop-applet的application.yml中添加sharding-jdbc配置即可==【如果使用nacos配置中心,需要在配置中心中添加配置: model-shop-applet-prod.yml】==:
3、在 resources 文件夹下添加jta.properties


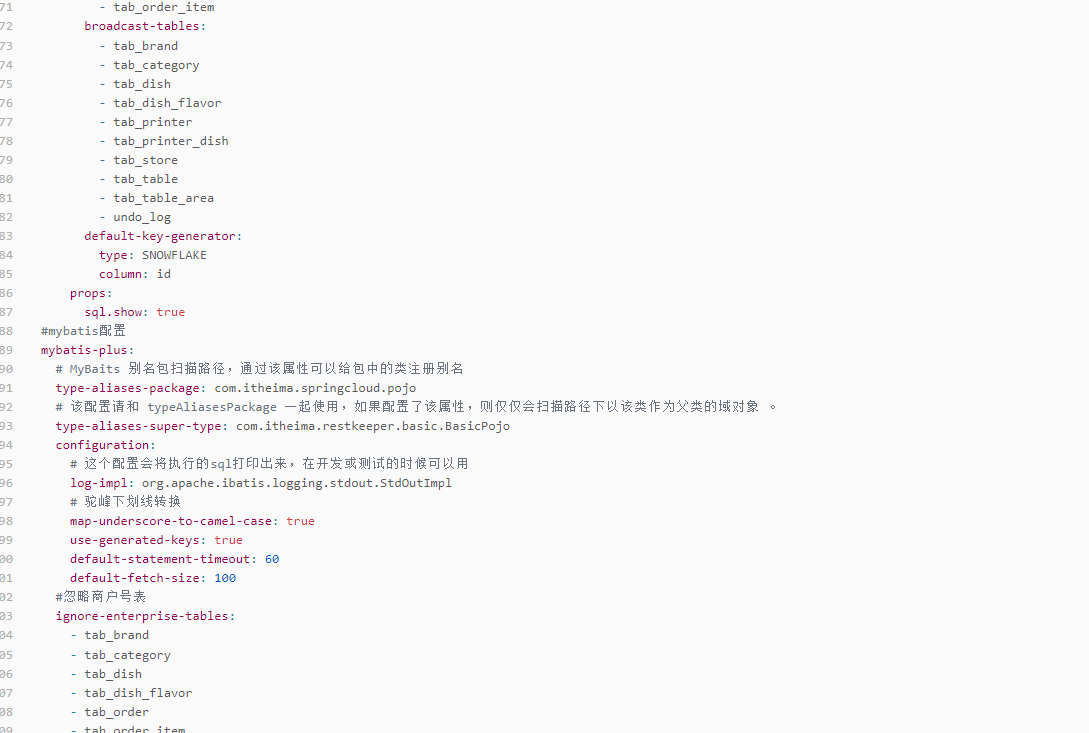
4、指定事务分类刚性事务:@ShardingTransactionType(TransactionType.XA)
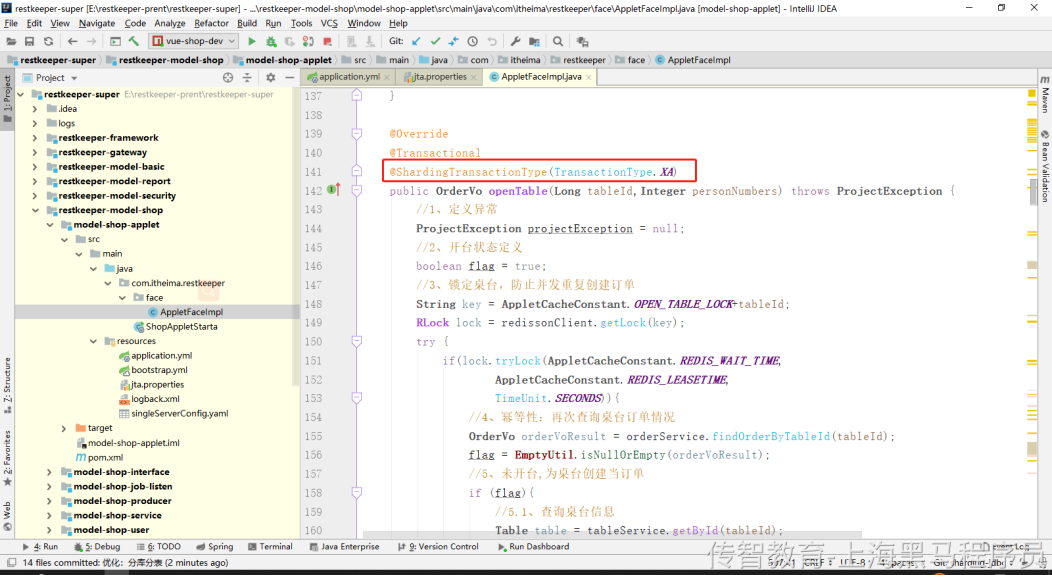
5、启动服务测试,观察数据库数据添加情况,和控制台日志打印情况:
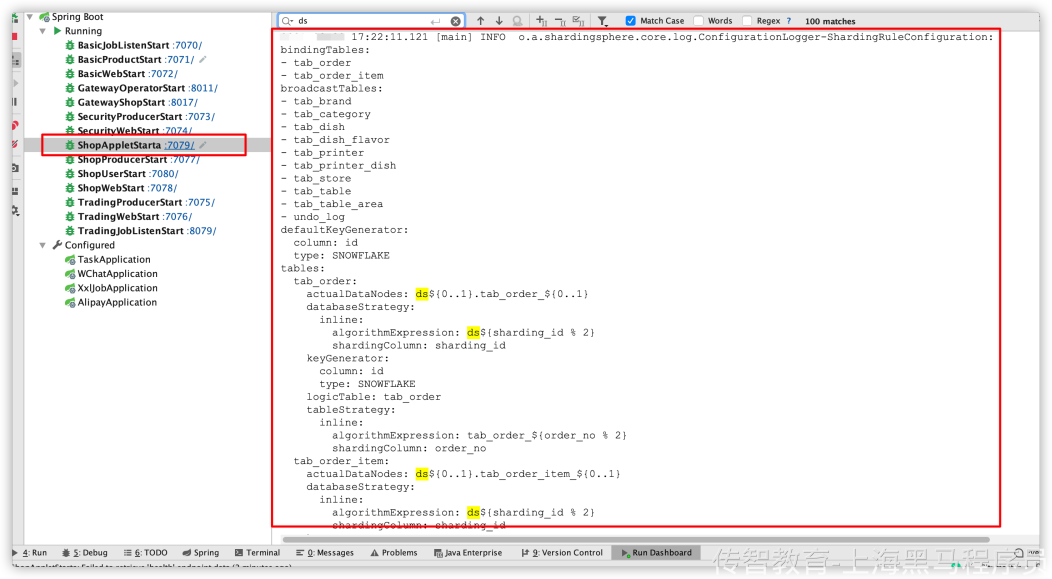
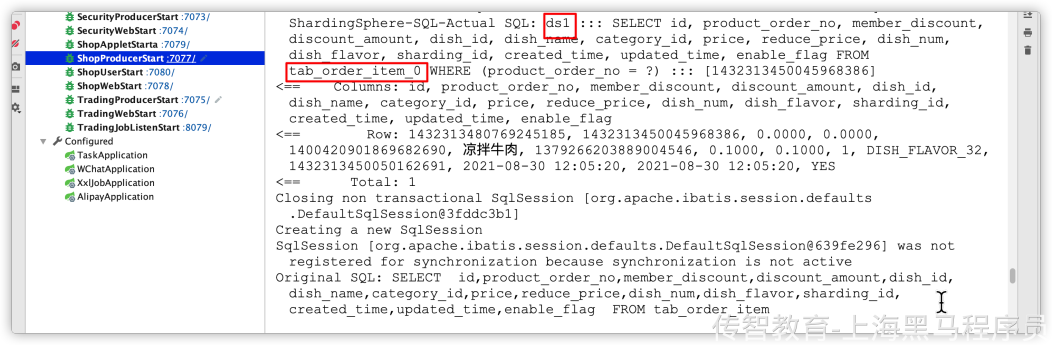
保存到数据库记录:
1.2、seata-at使用sharding-jdbc
以 model-shop-producer 项目为例
我们使用sharding-jdbc的时候只需要依赖: framework-sharding-jdbc 模块
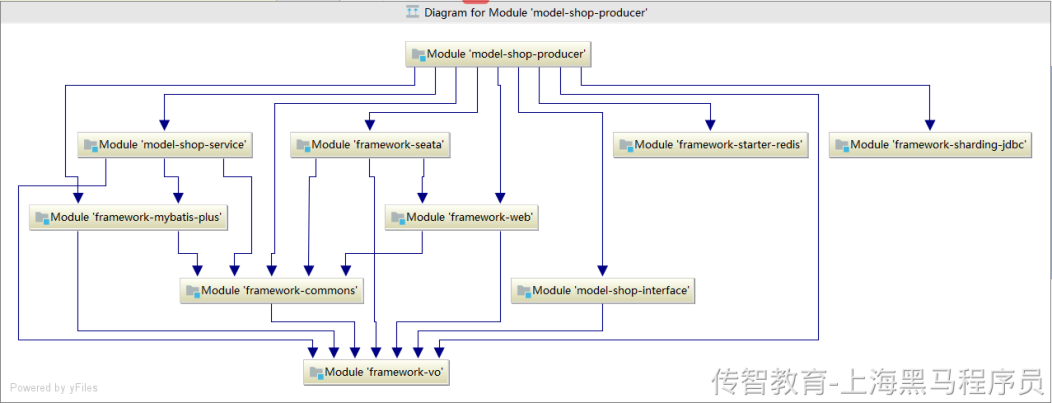
2、然后在model-shop-producer的application.yml中添加sharding-jdcb配置即可==【如果使用nacos配置中心,需要在配置中心中添加配置】==:
5、指定事务分类(柔性事务):@ShardingTransactionType(TransactionType.BASE)
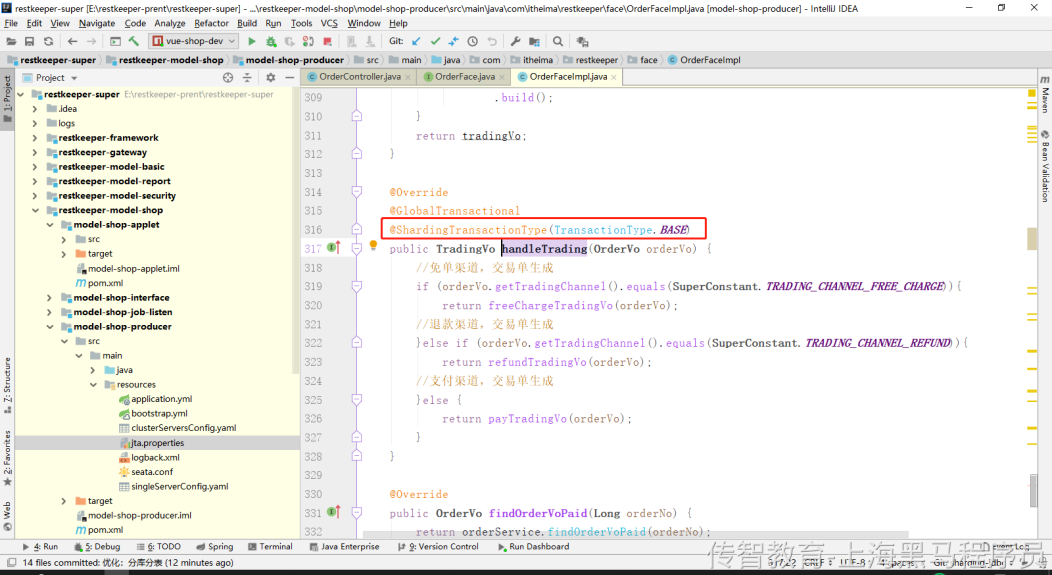
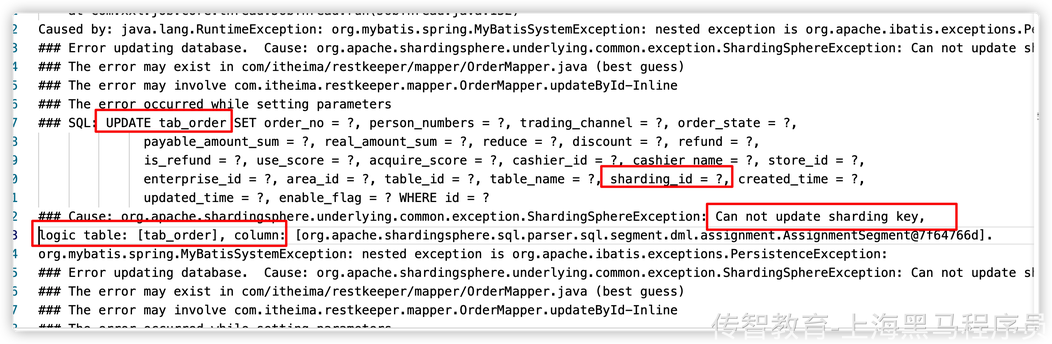
6、测试下单结算成功后,执行XXl-JOB任务查询订单结算状态出现以下bug:

若有收获,就点个赞吧
0 人点赞
