2014年Kubernetes横空出世,与Docker公司经过近4年的纷争后,最终确立了容器编排管理领域的领导地位。同时,伴随着云原生技术的落地与普及,Kubernetes逐渐成为众多企业青睐的对象。
在生产中使用Kubernetes管理应用,无论应用的部署规模如何,企业都需要知道集群中有多少可用资源,也需要了解部署应用和容器的健康状态。虽然Kubernetes社区已经提供了以 Prometheus为核心的一套统一监控方案,但企业仍不可避免地要面对集群监控管理带来的各种挑战。
面临监控数据来源多样,数据指标关联复杂、集群全局状态可视程度低等问题,企业在构建有效的监控体系前,首要考虑的就是:采集哪些数据进行监控?如何选取有价值的指标以建立全局视角的监控大屏。
What采集什么数据?
在以Prometheus为核心的监控体系下,Kubernetes集群的大部分指标都可以被采集,按照数据的来源不同,可以将监控数据分为以下3类:
- 宿主机数据:监控运行着Kubelet的Kubernetes主机的性能情况。
- Kubernetes进程数据:即Kubelet指标,监控有关Kubernetes节点及其运行工作的详细信息。
- 集群核心资源数据:包括Kubernetes集群级别和容器级别两方面的信息。

Why指标选取有什么依据?
从成千上万个指标中挑出最重要几个,不是件容易的事。这依赖我们对系统的理解和掌握程度。在充分了解Kubernetes的基础上,借助基本原则和方法可以指导我们确定要监控的指标,以快速定位问题。Google SRE运维解密一书中提出了监控系统的4个“黄金指标”—如果只能监控用户可见系统的4个指标,那么就应该监控以下4个。
显然,在复杂的Kubernetes系统中,4个黄金指标远远不够。上一步我们从数据来源对指标的采集进行了纵向分类,从监控汇总的角度看,可以将采集的指标按照服务提供和资源提供进行横向划分,以行业通用的USE方法和RED方法为指导原则,规划监控指标。
USE方法(Utilization Saturation and Errors Method)是Brendan Gregg总结出来的一套分析系统性能和资源瓶颈的方法。可以简单地描述为:检查所有资源的利用率,饱和度,和错误信息。
RED方法(Rate Errors and Duration Method)是Weave Cloud根据4个黄金指标指导思想,结合Prometheus以及Kubernetes容器实践,细化和总结出来的方法论。适合针对云原生应用的监控和度量。
将服务与资源指标结合,合理的使用监控指标,基本能够满足大部分监控场景需求,而如何对相关指标进行关联和呈现往往更能体现监控系统的价值。
How如何设计全局监控大屏?
据最新的Kubernetes采用情况调查报告显示,超过65%的受访者都表示:希望能够更直观地掌握生产环境Kubernetes集群运行状态,这一需求随着集群规模的扩大和集群数量的增多而越发强烈。
的确,通过运维大屏一眼了解集群的全局实时状态,是众多企业的诉求。当在全局大屏中发现异常时,再根据异常现象查看具体的细节仪表盘进行问题排查,极大的提升了集群故障管理和预防的便捷性和有效性。
以云掣Kubernetes监控大屏为例,对来源多样的Kubernetes监控数据进行筛选汇总后,按照USE方法和RED方法对资源和服务从多个维度综合呈现,满足集群运营管理者总览、直观、可追溯的需求。
- 直观:合理的使用图表做数据展示,一眼看出问题。
- 总览:掌握全局,有主题有层次,而非全部数据的混乱堆砌。
- 可追溯:可以查看指标的变化趋势,判断集群的实际运行情况,对集群的参数和服务进行优化,使其达到更佳的状态。
大屏整体按照数据域分为集群拓扑、集群概况、Master分析、Pod分析、Node分析5个模块。
主视图
将集群本身复杂的逻辑关系做了数字映射,以更立体的方式让管理人员感知。
将各Node基础资源(CPU、内存、磁盘)使用率做直观展示,同时,显示Node上运行的正常与异常的Pod数量。Master工作队列延迟、API接口调用次数、etcd节点总数情况。
每个Node模块支持下钻,可以查看运行Pod的详细监控情况,包括节点IP、响应时间、请求数情况、以及对应的容器列表。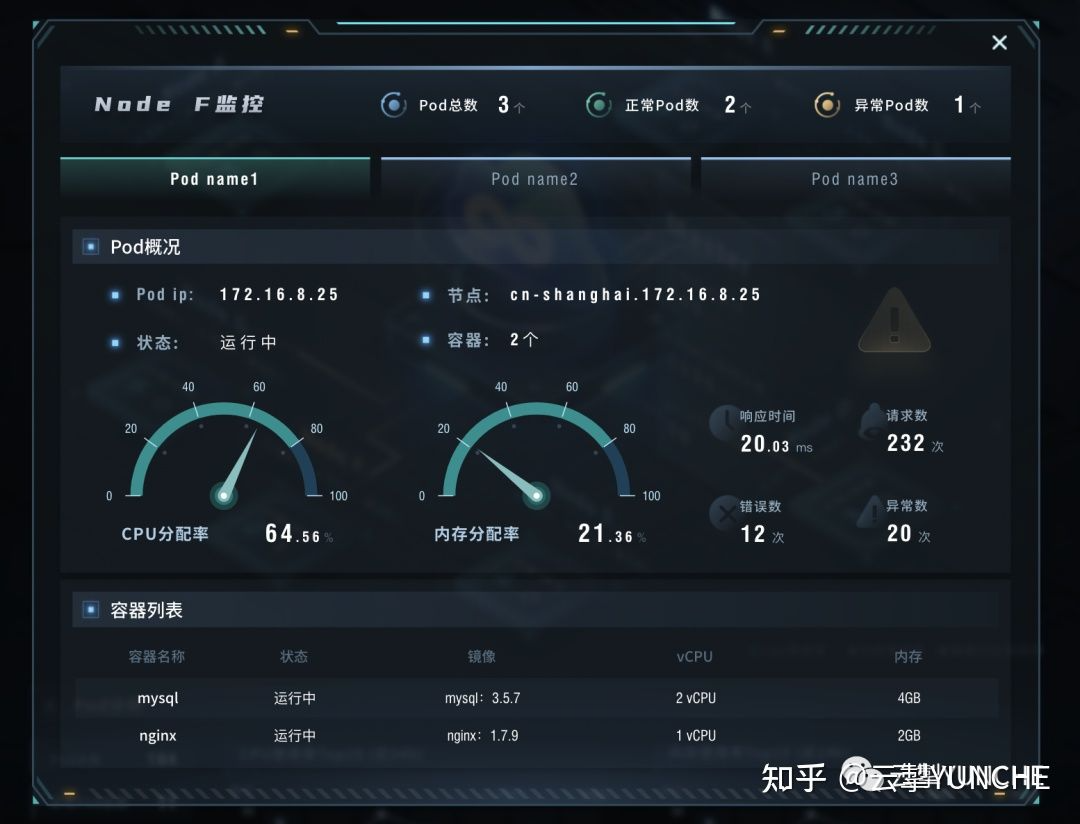
集群概况
翻牌器展示Deployment、DaemonSet、StatefulSet服务的总数量和异常数量。以仪表盘方式呈现cpu和内存实时水位。折线图展示网络流入流出流量趋势。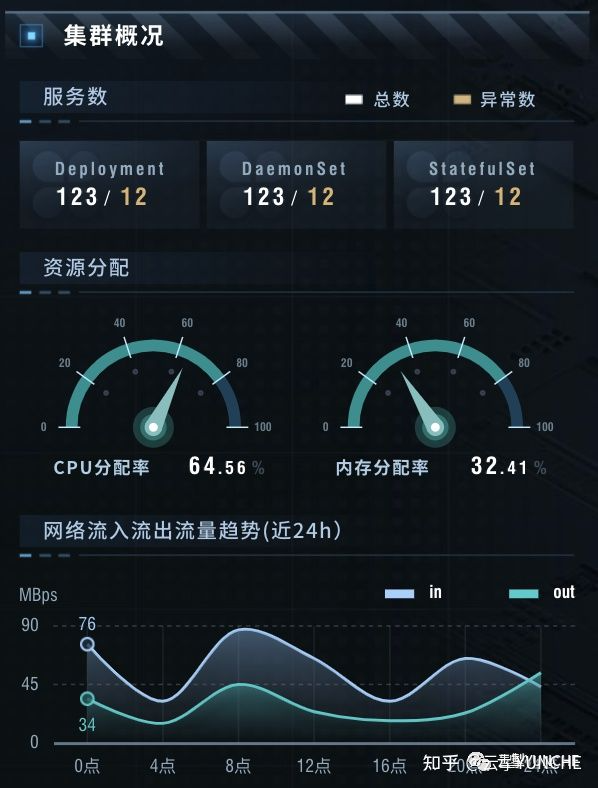
Master分析
主要展示Work Queue、API Server、ETCD 组件的信息,具体包括Controller 的工作队列延迟耗时、API Server请求QPS 和平均调用延迟、ETCD节点总数和异常数量。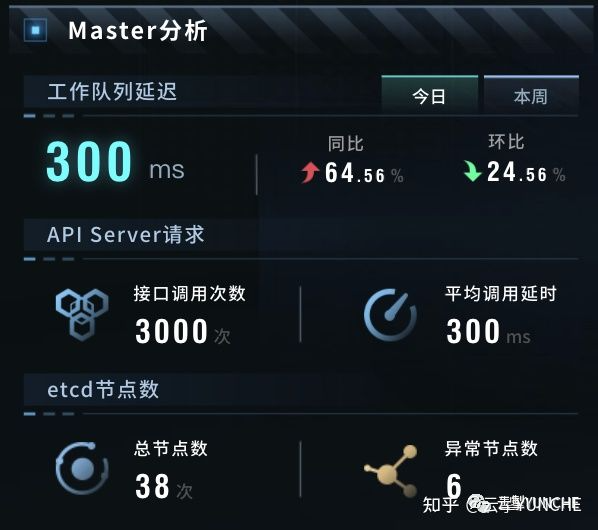
pod分析
主要展示Pod总数、异常Pod数、Pending数、Crash loop数、CPU、内存使用率趋势。
node分析
主要展示Pod总数、异常Node数、CPU、内存使用率趋势、分区空间使用率Top5

若有收获,就点个赞吧
0 人点赞
