copy.copy 与copy.deepcopy
copy.copy相当于是按元素的赋值,与赋值的区别在于,对于集合类型,如list,赋值操作只是对新变量添加了一个绑定,所以改变原list指向的空间的任何元素,也会同步修改新变量。
例如:
>>> a = [1, 2, [3,4]]>>> b = a>>> a[0] = 5>>> b[5, 2, [3, 4]]
那假如你不想让a的每一个元素改变,b都跟着变呢,就需要用到copy.copy了。
>>> a = [1, 2, [3,4]]>>> b = copy.copy(a)>>> a[0] = 11>>> a[11, 2, [3, 4]]>>> b[1, 2, [3, 4]] # 这里说明了copy.copy就是按元素的赋值,对于1,2等元素,赋值两边并不会影响,就像a = 1, b = a,改变a,并不会改变b>>> a[2] = [5]>>> a[11, 2, [5]]>>> b[1, 2, [3, 4]] # 这里说明了copy.copy就是按元素的赋值,对于list也是一样,对a[2]的赋值相当于改变了原list的指向,对b[2]无影响>>> a = [1, 2, [3,4]]>>> b = copy.copy(a)>>> a[2][1] = 5>>> a[1, 2, [3, 5]]>>> b[1, 2, [3, 5]] # 从这里就看出确实是赋值操作,所以对a[2]内部的改变,影响了b[2]的内部
对list而言,copy.copy可以简写为copied_list = original_list[:],对dict而言,copy.copy,可以写为dict.copy()。
future
filter
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
ps:Pyhton2.7 返回列表,Python3.x 返回迭代器对象
from collections import Iterablenum = [1, 2, 3, 4, 5, 6]res = filter(lambda x: x < 4, num)print('filter函数的输出结果是', res)print('filter函数的结果是否可迭代?', isinstance(res, Iterable))print(list(res))
filter函数的输出结果是 <filter object at 0x7f549d8b6ef0>filter函数的结果是否可迭代? True[1, 2, 3]
any和all
- any(x):有1个True,结果即为True。判断x对象是否不为空对象,如果不都为空、0、false,则返回true;如果都为空、0、false,则返回false,
- all(x):所有都为True,结果才为True。判断x对象是否不为空对象,如果all(x)参数x对象的所有元素不为0、’’、False或者x为空对象,则返回True,否则返回False
```python
any(‘123’) True any([0,1]) True any([0,’0’,’’]) True any([0,’’]) False any([0,’’,’false’]) True any([0,’’,bool(‘false’)]) True any([0,’’,False]) False any((‘a’,’b’,’c’)) True any((‘a’,’b’,’’)) True any((0,False,’’)) False any([]) False any(()) False
all([‘a’, ‘b’, ‘c’, ‘d’]) #列表list, True all([‘a’, ‘b’, ‘c’, ‘d’]) #列表list,元素都不为空或0 True all([‘a’, ‘b’, ‘’, ‘d’]) #列表list,存在一个为空的元素 False all([0, 1,2, 3]) #列表list,存在一个为0的元素 False all((‘a’, ‘b’, ‘c’, ‘d’)) #元组tuple,元素都不为空或0 True all((‘a’, ‘b’, ‘’, ‘d’)) #元组tuple,存在一个为空的元素 False all((0, 1,2, 3)) #元组tuple,存在一个为0的元素 False all([]) # 空列表 True all(()) # 空元组 True
注意:空元组、空列表返回值为True,这里要特别注意
all((‘’, ‘’, ‘’, ‘’)) #元组tuple,全部为空的元素 False all(‘’) True
如果all(x)参数x对象的所有元素不为0、’’、False或者x为空对象,则返回True,否则返回False
例如,在transformers代码里有这么一段,其中bert_param_optimizer是一个map,目的是实现,如果bert_param_optimizer的key中不包含no_decay中的任一元素,则获取该key对应的value:```pythonno_decay = ["bias", "LayerNorm.weight"]res = [p for n, p in bert_param_optimizer if not any(nd in n for nd in no_decay)]# 这段等价于res = []flag = Truefor n, p in bert_param_optimizer:for nd in no_decay:if nd in n:flag = Falseif flag:res.append(p)高性能容器 - collections

- deque - 队列,可以从双端进行append和pop
- Counter - 计数器
- OrderDict - 有顺序的Dict
- defaultdict - 有默认值的dict
```python
nums = [1, 2, 3, 1, 2, 5]
import collections dict_nums = collections.Counter(nums) dict_nums Counter({1: 2, 2: 2, 3: 1, 5: 1}) print(dict(dict_nums)) {1: 2, 2: 2, 3: 1, 5: 1}
字符串构造Counter
collections.Counter(‘abc’) Counter({‘a’: 1, ‘b’: 1, ‘c’: 1})
dict构造Counter
collections.Counter({‘a’:1, ‘b’:2}) Counter({‘b’: 2, ‘a’: 1})
元组构造Counter
collections.Counter(a=1, b=2) Counter({‘b’: 2, ‘a’: 1})
dict_nums Counter({1: 2, 2: 2, 3: 1, 5: 1}) del dict_nums[1] dict_nums Counter({2: 2, 3: 1, 5: 1})
查找出现次数最多的2个dict
dict_nums.most_common(2) [(2, 2), (3, 1)]
Counter间的运算
a = collections.Counter(a=1,b=2) b = collections.Counter(a=2,c=3) a+b Counter({‘a’: 3, ‘c’: 3, ‘b’: 2})
a-b,小于0的会被删除
a-b Counter({‘b’: 2}) b-a Counter({‘c’: 3, ‘a’: 1})
交,相同取最小
a&b Counter({‘a’: 1})
并,集合取最大
a|b Counter({‘c’: 3, ‘a’: 2, ‘b’: 2}) ```
返回默认key的字典 defaultdict
defaultdict 超级好用,他无需判断某个key是否在字典里,当不在时,会自动加入,对应的value,在不同的类型时,有不同的默认值:
- int - 0
- list - []
- set - set()
- str - 空字符串
```python
from collections import defaultdict d1 = dict() d2 = defaultdict(list) print(d1[‘a’]) Traceback (most recent call last): File “
“, line 1, in KeyError: ‘a’
print(d2[‘a’]) []
d3 = defaultdict(int) d3[‘a’] 0 d2[‘a’].append(1) d2 defaultdict(
, {‘a’: [1]})
设置默认元素为-1
d3 = defaultdcit(lambda:-1)
<a name="ZK5o7"></a>### deque - 双端队列相比于list实现的队列,deque实现拥有更低的时间和空间复杂度。list实现在出队(pop)和插入(insert)时的空间复杂度大约为O(n),deque在出队(pop)和入队(append)时的时间复杂度是O(1)。<br />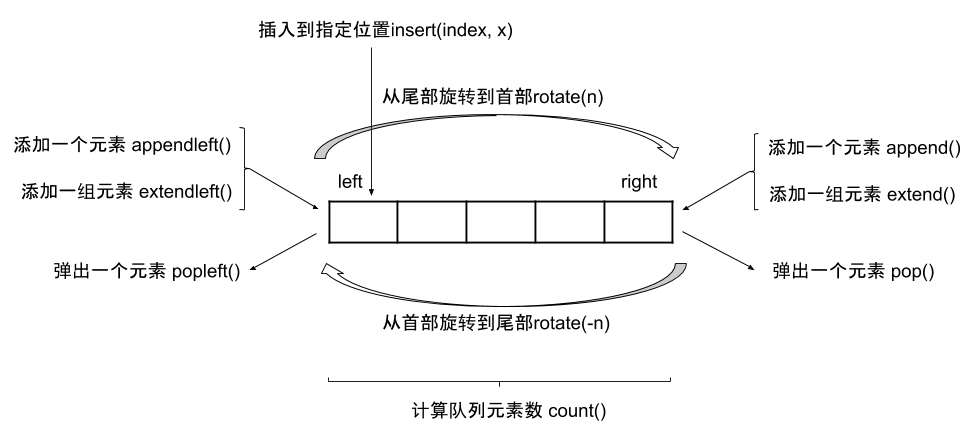```pythona = collections.deque([1,2,3,4])1 in aTrue# 元素右移a.rotate(2)adeque([3, 4, 1, 2])# 元素左移a.rotate(-2)adeque([1, 2, 3, 4])len(a)4a.append(5)adeque([1, 2, 3, 4, 5])a.appendleft(0)adeque([0, 1, 2, 3, 4, 5])a.extend([6])adeque([0, 1, 2, 3, 4, 5, 6])a.popleft()0a.popleft(2)Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: popleft() takes no arguments (1 given)a.pop()6functools.partial
偏函数,简而言之就是固定函数中的某些参数,实现参数简化。 ```python import functools
def func1(func2, args): print(“i am func1”) func2(args)
def func2(*args): print(“i am func2”) if len(args) > 0: print(args)
生成一个新的函数func,不会调用,新函数相当于def func(*args),实际内容还是func1的内容
func = functools.partial(func1, func2) func(“good”) # 相当于调用了func1(func2, “good”)
— 结果 i am func1 i am func2 (‘good’,)
<a name="VVLu1"></a>## 根据函数名打印源码```pythonimport inspectprint(inspect.getsource(fuction_name))

若有收获,就点个赞吧
0 人点赞
