Socket用法
Python 提供了两个基本的 socket 模块。
- 第一个是 Socket,它提供了标准的 BSD Sockets API。
- 第二个是 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
下面讲的是Socket模块功能
1、Socket 类型
套接字格式:
socket(family,type[,protocal]) 使用给定的地址族、套接字类型、协议编号(默认为0)来创建套接字。
| socket类型 | 描述 |
|---|---|
socket.AF_UNIX |
只能够用于单一的Unix系统进程间通信 |
socket.AF_INET |
服务器之间网络通信 |
socket.AF_INET6 |
IPv6 |
socket.SOCK_STREAM |
流式socket , for TCP |
socket.SOCK_DGRAM |
数据报式socket , for UDP |
socket.SOCK_RAW |
原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。 |
socket.SOCK_SEQPACKET |
可靠的连续数据包服务 |
| 创建TCP Socket: | s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) |
| 创建UDP Socket: | s=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) |
2、Socket 函数
注意点:
- TCP发送数据时,已建立好TCP连接,所以不需要指定地址。UDP是面向无连接的,每次发送要指定是发给谁。
- 服务端与客户端不能直接发送列表,元组,字典。需要字符串化
repr(data)。
服务端socket函数:
| socket函数 | 描述 |
|---|---|
s.bind(address) |
将套接字绑定到地址, 在AF_INET下,以元组(host,port)的形式表示地址. |
s.listen(backlog) |
开始监听TCP传入连接。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 |
s.accept() |
接受TCP连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。 |
客户端socket函数:
| socket函数 | 描述 |
|---|---|
s.connect(address) |
连接到address处的套接字。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 |
s.connect_ex(adddress) |
功能与connect(address)相同,但是成功返回0,失败返回error的值。 |
公共socket函数:
| socket函数 | 描述 |
|---|---|
s.recv(bufsize[,flag]) |
接受TCP套接字的数据。数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 |
s.send(string[,flag]) |
发送TCP数据。将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 |
s.sendall(string[,flag]) |
完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 |
s.recvfrom(bufsize[.flag]) |
接受UDP套接字的数据。与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 |
s.sendto(string[,flag],address) |
发送UDP数据。将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 |
s.close() |
关闭套接字。 |
s.getpeername() |
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 |
s.getsockname() |
返回套接字自己的地址。通常是一个元组(ipaddr,port) |
s.setsockopt(level,optname,value) |
设置给定套接字选项的值。 |
s.getsockopt(level,optname[.buflen]) |
返回套接字选项的值。 |
s.settimeout(timeout) |
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) |
s.gettimeout() |
返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 |
s.fileno() |
返回套接字的文件描述符。 |
s.setblocking(flag) |
如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常。 |
s.makefile() |
创建一个与该套接字相关连的文件 |
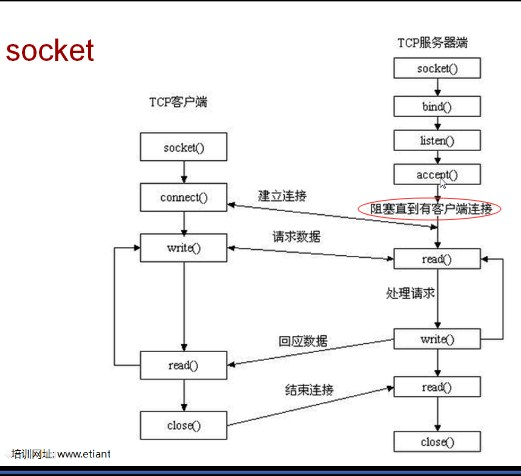
3、socket编程思路
TCP服务端:
- 创建套接字,绑定套接字到本地IP与端口
# socket.socket(socket.AF_INET,socket.SOCK_STREAM) , s.bind() - 开始监听连接 #s.listen()
- 进入循环,不断接受客户端的连接请求 #s.accept()
- 然后接收传来的数据,并发送给对方数据 #s.recv() , s.sendall()
- 传输完毕后,关闭套接字 #s.close()
TCP客户端:
- 创建套接字,连接远端地址
# socket.socket(socket.AF_INET,socket.SOCK_STREAM) , s.connect() - 连接后发送数据和接收数据 # s.sendall(), s.recv()
- 传输完毕后,关闭套接字 #s.close()
4、Socket编程之服务端代码:
import socket #socket模块import commands #执行系统命令模块HOST='10.0.0.245'PORT=50007s= socket.socket(socket.AF_INET,socket.SOCK_STREAM) #定义socket类型,网络通信,TCPs.bind((HOST,PORT)) #套接字绑定的IP与端口s.listen(1) #开始TCP监听,监听1个请求while 1:conn,addr=s.accept() #接受TCP连接,并返回新的套接字与IP地址print'Connected by',addr #输出客户端的IP地址while 1:data=conn.recv(1024) #把接收的数据实例化cmd_status,cmd_result=commands.getstatusoutput(data)#commands.getstatusoutput执行系统命令(即shell命令),返回两个结果,#第一个是状态,成功则为0,第二个是执行成功或失败的输出信息if len(cmd_result.strip()) ==0:#如果输出结果长度为0,则告诉客户端完成。此用法针对于创建文件或目录,创建成功不会有输出信息conn.sendall('Done.')else:conn.sendall(cmd_result) #否则就把结果发给对端(即客户端)conn.close() #关闭连接
5、Socket编程之客户端代码:
import socketHOST='10.0.0.245'PORT=50007s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #定义socket类型,网络通信,TCPs.connect((HOST,PORT)) #要连接的IP与端口while 1:cmd=raw_input("Please input cmd:") #与人交互,输入命令s.sendall(cmd) #把命令发送给对端data=s.recv(1024) #把接收的数据定义为变量print data #输出变量s.close() #关闭连接
使用struct处理二进制(pack和unpack用法)
python有时需要处理二进制数据,例如存取文件,socket操作时可以使用python的struct模块来完成。可以用struct来处理c语言中的结构体。
struct模块中最重要的三个函数是pack(), unpack(), calcsize
- 按照给定的格式(fmt),把数据封装成字符串(实际上是类似于c结构体的字节流)
pack(fmt, v1, v2, ...) - 按照给定的格式(fmt)解析字节流string,返回解析出来的tuple
unpack(fmt,string) - 计算给定的格式(fmt)占用多少字节的内存
calcsize(fmt)| FORMAT | C TYPE | PYTHON TYPE | STANDARD SIZE | | —- | —- | —- | —- | | x | pad byte | no value | | | c | char | string of length | 1 | | b | signed char | integer | 1 | | B | unsigned char | integer | 1 | | ? | _Bool | bool | 1 | | h | short | integer | 2 | | H | unsigned short | integer | 2 | | i | int | integer | 4 | | I | unsigned int | integer | 4 | | l | long | integer | 4 | | L | unsigned long | integer | 4 | | q | long long | integer | 8 | | Q | unsigned long long | integer | 8 | | f | float | float | 4 | | d | double | float | 8 | | s | char[] | string | | | p | char[] | string | | | P | void * | integer | |
注意:
- q和Q只在机器支持64位操作系统有意义
- 每个格式前可以有一个数字,表示个数
- s格式表示一定长度的字符串,4s表示长度为4的字符串,但是p表示的是pascal字符串
- P用来转换一个指针,其长度和机器字长相关
- 最后一个可以用来表示指针类型的,占4个字节
为了同c中的结构体交换数据,还要考虑有的c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换。可以用格式中的第一个字符来改变对齐方式。定义如下:
| CHARACTER | BYTE ORDER | SIZE | ALIGNMENT |
|---|---|---|---|
| @ | native | native | native |
| = | native | standard | none |
| < | little-endian | standard | none |
| > | big-endian | standard | none |
| ! | network (= big-endian) | standard | none |
使用方法是放在fmt的第一个位置,就像@5s6sif
示例一:
比如有一个结构体
struct Header{unsigned short id;char[4] tag;unsigned int version;unsigned int count;}
通过socket.recv接收到了一个上面的结构体数据,存在字符串s中,现在需要把它解析出来,可以使用unpack()函数。
import structid, tag, version, count = struct.unpack("!H4s2I", s)
上面的格式字符串中,!表示我们要使用网络字节顺序解析,因为我们的数据是从网络中接收到的,在网络上传送的时候它是网络字节顺序的。后面的H表示 一个unsigned short的id,4s表示4字节长的字符串,2I表示有两个unsigned int类型的数据。就通过一个unpack,现在id, tag, version, count里已经保存好我们的信息了。
同样,也可以很方便的把本地数据再pack成struct格式。
ss = struct.pack("!H4s2I", id, tag, version, count);
pack函数就把id, tag, version, count按照指定的格式转换成了结构体Header,ss现在是一个字符串(实际上是类似于c结构体的字节流),可以通过 socket.send(ss)把这个字符串发送出去。
示例二:
import structa=12.34#将a变为二进制bytes=struct.pack('i',a)
此时bytes就是一个string字符串,字符串按字节同a的二进制存储内容相同。
再进行反操作,现有二进制数据bytes,(其实就是字符串),将它反过来转换成python的数据类型:
a,=struct.unpack('i',bytes)
注意,unpack返回的是tuple,所以如果只有一个变量的话:
bytes=struct.pack('i',a)
那么,解码的时候需要这样
a,=struct.unpack('i',bytes) 或者 (a,)=struct.unpack('i',bytes)
如果直接用a=struct.unpack('i',bytes),那么 a=(12.34,) ,是一个tuple而不是原来的浮点数了。
如果是由多个数据构成的,可以这样:
a='hello'b='world!'c=2d=45.123bytes=struct.pack('5s6sif',a,b,c,d)
此时的bytes就是二进制形式的数据了,可以直接写入文件比如 binfile.write(bytes)
然后,当我们需要时可以再读出来,bytes=binfile.read(),再通过struct.unpack()解码成python变量
a,b,c,d=struct.unpack('5s6sif',bytes)
利用buffer,使用pack_into和unpack_from方法
使用二进制打包数据的场景大部分都是对性能要求比较高的使用环境。而在上面提到的pack方法都是对输入数据进行操作后重新创建了一个内存空间用于返回,也就是说我们每次pack都会在内存中分配出相应的内存资源,这有时是一种很大的性能浪费。struct模块还提供了pack_into() 和 unpack_from()的方法用来解决这样的问题,也就是对一个已经提前分配好的buffer进行字节的填充,而不会每次都产生一个新对象对字节进行存储。
import structimport binasciiimport ctypesvalues = ( 1 , 'abc' , 2.7 )s = struct.Struct( 'I3sf' )prebuffer = ctypes.create_string_buffer(s.size)print 'Before :' ,binascii.hexlify(prebuffer)s.pack_into(prebuffer, 0 , * values)print 'After pack:' ,binascii.hexlify(prebuffer)unpacked = s.unpack_from(prebuffer, 0 )print 'After unpack:' ,unpacked
对比使用pack方法打包,pack_into 方法一直是在对prebuffer对象进行操作,没有产生多余的内存浪费。另外需要注意的一点是,pack_into和unpack_from方法均是对string buffer对象进行操作,并提供了offset参数,用户可以通过指定相应的offset,使相应的处理变得更加灵活。例如,我们可以把多个对象pack到一个buffer里面,然后通过指定不同的offset进行unpack:
import structimport binasciiimport ctypesvalues1 = ( 1 , 'abc' , 2.7 )values2 = ( 'defg' , 101 )s1 = struct.Struct( 'I3sf' )s2 = struct.Struct( '4sI' )prebuffer = ctypes.create_string_buffer(s1.size + s2.size)print 'Before :' ,binascii.hexlify(prebuffer)s1.pack_into(prebuffer, 0 , * values1)s2.pack_into(prebuffer,s1.size, * values2)print 'After pack:' ,binascii.hexlify(prebuffer)print s1.unpack_from(prebuffer, 0 )print s2.unpack_from(prebuffer,s1.size)

若有收获,就点个赞吧
0 人点赞
