- 张量 tensor
- 创建操作
- torch.eye()
- torch.Tensor()
- torch.tensor()
- torch.from_numpy()
- torch.linspace()
- torch.logspace()
- torch.ones()
- torch.ones_like()
- torch.rand()
- torch.randn()
- torch.randperm()
- torch.arange()
- torch.range()
- torch.zeros()
- torch.zeros_like()
torch.empty()- torch.empty_like()
- torch.as_strided() 🧡🧡🧡
torch.empty_strided()- torch.full()
- torch.full_like()
- torch.sparse_coo_tensor()
- torch.as_tensor()
- 索引,切片,连接,换位
- 随机抽样 Random sampling
- 序列化 Serialization
- 并行化 Parallelism
- 数学操作 Math operations
- Pointwise Ops
- torch.abs()
- torch.acos()
- torch.add()
- torch.addcdiv()
- torch.addcmul()
- torch.asin()
- torch.atan()
- torch.atan2()
- torch.ceil()
- torch.clamp()
- torch.cos()
- torch.cosh()
- torch.div()
- torch.exp()
- torch.floor()
- torch.fmod()
- torch.frac()
- torch.lerp()
- torch.log()
- torch.log1p()
- torch.mul()
- torch.neg()
- torch.pow()
- torch.reciprocal()
- torch.remainder()
- torch.round()
- torch.rsqrt()
- torch.sigmoid()
- torch.sign()
- torch.sin()
- torch.sinh()
- torch.sqrt()
- torch.tan()
- torch.tanh()
- torch.trunc()
- Reduction Ops
- 比较操作 Comparison Ops
- 其它操作 Other Operations
- BLAS and LAPACK Operations
- Pointwise Ops
- Other
- 参考链接
张量 tensor
torch.is_tensor()
如果obj是一个tensor,则返回True。
torch.is_tensor(obj)
torch.is_storage()
如果obj是一个storage对象,则返回True
torch.is_storage(obj)
那么什么是Storage?Storage类型是pytorch中的一个类型,它与tensor是对应的。tensor分为**头信息区(Tensor)和存储区**(Storage)。
- 信息区主要存储tensor的形状、步长、数据类型等信息,其真正的数据保存为连续数组,存储在存储区中。
- 一般来说pytorch中tensor的数据很大,可能是成千上万的,所以我们信息区一般来说占用的内存比较少,主要内存的占用取决于tensor中元素的数目,也就是存储区的大小。
其实说的通俗一点就是,我们的Tensor相当于一组描述符,可以类比为操作系统中的PCB,而Storage是我们真正的进程数据存放的位置。
一般来说,一个tensor对应一个storage,storage是在data之上封装的接口,便于我们进行使用。不同的tensor的头部信息一般是不同的,但是它们使用的Storage可能相同(也就是共享内存)。
举个例子:
>>> a = torch.rand(3, 5)>>> atensor([[0.4575, 0.4711, 0.7367, 0.3744, 0.2197],[0.3335, 0.5182, 0.4853, 0.5433, 0.9604],[0.5801, 0.3798, 0.5403, 0.0130, 0.3634]])>>> a.storage()0.457485735416412350.47114318609237670.73667693138122560.374391496181488040.219701766967773440.33351576328277590.51817280054092410.48526805639266970.54334509372711180.9604399204254150.5800781250.37978738546371460.5403155684471130.0130047202110290530.36340975761413574[torch.FloatStorage of size 15]
可以看到Storge只是一连串的数据,并没有别的信息。而上面是tensor,至于为什么print(a)会显示数据,而不是显示头部信息,这是因为pytorch为了方便查看进行的操作,使得显示的时候会显示数据,不然查看一个变量会很麻烦。
如果加上一句a.requires_grad = True,即如下代码:
>>> a = torch.rand(3, 5)>>> a.requires_grad = True>>> atensor([[0.4575, 0.4711, 0.7367, 0.3744, 0.2197],[0.3335, 0.5182, 0.4853, 0.5433, 0.9604],[0.5801, 0.3798, 0.5403, 0.0130, 0.3634]], requires_grad=True)>>> a.storage()0.457485735416412350.47114318609237670.73667693138122560.374391496181488040.219701766967773440.33351576328277590.51817280054092410.48526805639266970.54334509372711180.9604399204254150.5800781250.37978738546371460.5403155684471130.0130047202110290530.36340975761413574[torch.FloatStorage of size 15]
可以发现Storage并没有改变,它只有数据,没有别的东西。只是我们的Tensor中增加了描述符,描述了我们这个tensor是有梯度的。
torch.numel()
返回input张量中的元素个数。其实就是tensor.size()乘起来。
torch.numel(input)
这个函数在统计模型中所含参数个数时比较有用。
创建操作
torch.eye()
返回一个2维张量,对角线为1,其它位置为0。
- n (int) 行数
- m (int, optional) 列数,如果为None,则默认为n
- out (Tensor, optional)
torch.eye(n, m=None, out=None)
torch.Tensor()
首先明确一点,这是python类,是默认张量类型torch.FloatTensor()的别名,我们每次调用torch.Tensor([1, 2, 3, 4, 5])来构造一个tensor的时候,会调用Tensor类的构造函数,生成一个单精度浮点类型的张量。
>>> a = torch.Tensor([1, 2, 3, 4, 5])>>> print(a.dtype)torch.float32>>> print(a.type())torch.FloatTensor
它不能指定数据类型,除非转成一个已知数据类型的张量,使用type_as(tesnor)将张量转换为给定类型的张量
torch.tensor()
torch.tensor()仅仅是python的函数,函数原型为:
torch.tensor(data, dtype=None, device=None, requires_grad=False)
其中data可以是:list,tuple,NumPy,ndarray等其他类型,torch.tensor会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor,torch.FloatTensor和torch.DoubleTensor。
>>> a = torch.tensor([0, 1, 2, 3, 4])>>> b = torch.tensor([0., 1., 2., 3., 4.])>>> a.type()'torch.LongTensor'>>> b.type()'torch.FloatTensor'
此外根据函数定义,可以生成指定dtype的tensor。
>>> torch.tensor([0, 1, 2, 3, 4], dtype=torch.long)tensor([0, 1, 2, 3, 4])>>> torch.tensor([0., 1., 2., 3., 4.], dtype=torch.double)tensor([0., 1., 2., 3., 4.], dtype=torch.float64)
torch.from_numpy()
将numpy.ndarray转换为Tensor。返回的张量tensor和ndarray共享同一内存空间,修改一个会导致另一个也被修改,返回的张量不能改变大小。
torch.from_numpy(ndarray)
例子:
>>> a = np.array([1, 2, 3])>>> t = torch.from_numpy(a)>>> t[0] = -1>>> aarray([-1, 2, 3])>>> ttensor([-1, 2, 3], dtype=torch.int32)
可以看到a和t都变了,这一点在使用中一定要注意!
torch.linspace()
返回一个1维张量,包含在start和end上均匀间隔的steps个点。
- start (float) -序列起点
- end (float) - 序列终点
- steps (int) - 在start与end间生成的样本数
- out (Tensor, optional) - 结果张量
例子:torch.linspace(start, end, steps=100, out=None)
>>> a = torch.linspace(0, 10, 2)tensor([0.0000, 2.0000, 4.0000, 6.0000, 8.0000, 10.0000])
torch.logspace()
创建对数均分的1维张量。返回一个1维张量,包含在区间 和
和 上以对数刻度均匀间隔的
上以对数刻度均匀间隔的steps个点。
注意事项:长度为steps,底为base
- start: 数列起始值
- end: 数列结束值
- steps: 数列长度
- base: 对数函数的底,默认为10
官方例子:torch.logspace(start, end, steps=100, base=10.0, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
>>> torch.logspace(start=-10, end=10, steps=5)tensor([ 1.0000e-10, 1.0000e-05, 1.0000e+00, 1.0000e+05, 1.0000e+10])>>> torch.logspace(start=0.1, end=1.0, steps=5)tensor([ 1.2589, 2.1135, 3.5481, 5.9566, 10.0000])>>> torch.logspace(start=0.1, end=1.0, steps=1)tensor([1.2589])>>> torch.logspace(start=2, end=2, steps=1, base=2)tensor([4.0])
torch.ones()
返回一个全为1的张量,形状由可变参数sizes定义。
torch.ones(*sizes, out=None)
torch.ones_like()
返回一个填充了标量值1的张量,其大小与input相同 。torch.ones_like(input)相当于:
torch.ones(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)
torch.rand()
返回一个张量,包含了从区间(0, 1)的均匀分布中抽取的一组随机数,形状由可变参数sizes定义。
torch.rand(*sizes, out=None)
torch.randn()
返回一个张量,包含了从标准正态分布(mean=0, std=1)中抽取一组随机数,形状由可变参数sizes定义。
torch.randn(*sizes, out=None)
torch.randperm()
给定参数n,返回一个从0到n-1的随机整数排列。
- n (int) - 上边界(不包含)
官方例子:torch.randperm(n, out=None)
>>> torch.randperm(4)tensor([2, 1, 0, 3])
torch.arange()
返回一个1维张量,长度为floor((end-start)/step),以step为步长的一组序列值。
- start (float) - 起点
- end (float) - 终点
- step (float) - 相邻点的间隔大小
- out (Tensor, optional)
注意:不包含end。
torch.arange(start, end, step=1, out=None)
例子:
>>> torch.arange(5)tensor([ 0, 1, 2, 3, 4])
torch.range()
和torch.arange()大致一样。但是torch.range()的结果包含end。
torch.range(start, end, step=1, out=None)
PS:推荐使用torch.arange(),因为torch.arange()兼容更多种类的参数。
torch.zeros()
返回一个全为标量0的张量,形状由可变参数sizes定义。
torch.zeros(*sizes, out=None)
torch.zeros_like()
根据给定张量,生成与其形状相同的全0张量。与torch.ones_like()类似。
torch.empty()
用来返回一个没有初始化的tensor。
>>> torch.empty(2,3)tensor([[1.1692e-19, 1.5637e-01, 5.0783e+31],[4.2964e+24, 2.6908e+20, 2.7490e+20]])
torch.empty_like()
创建一个与input形状一样的使用未初始化的tensor。与torch.ones_like()类似。相当于:
torch.empty(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)
torch.as_strided() 🧡🧡🧡
此方法根据现有tensor以及给定的步长来创建一个视图(类型仍然为tensor)。
torch.as_strided(input, size, stride, storage_offset=0)—>Tensor
视图是指创建一个方便查看的东西,与原数据共享内存,它并不占用内存,也不存储数据,只是将原有的数据进行整理,显示其中部分内容或者进行重排序后显示出来等等。来看一个例子:
>>> torch.manual_seed(0) # 设定随机种子>>> a = torch.rand(4, 4)>>> b = torch.as_strided(a, (3, 3), (1, 1))>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> btensor([[0.4963, 0.7682, 0.0885],[0.7682, 0.0885, 0.1320],[0.0885, 0.1320, 0.3074]])
这样创建出来的b就是a的一个视图,可以发现,b中的元素都是a中的元素,所以其实**b**中并不存储数据,它只是显示**a**中的数据,如果改变a中的数据的话,b中的数据也会改变,反之亦然。
torch.as_strided()参数:
input:此参数指定了在哪个数据上创建视图,input需为tensor。size:指定了生成的视图的大小,需要为一个矩阵(当然此矩阵大小可以大于原矩阵,但是也有限制),可以是tensor或者list等等。stride:输出tensor的步长,根据原矩阵和步长生成了新矩阵。storage_offset:输出张量的基础存储中的偏移量。
继续使用上面的例子,将步长改为(0, 0):
>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> b = torch.as_strided(a, (3, 3), (0, 0))>>> btensor([[0.4963, 0.4963, 0.4963],[0.4963, 0.4963, 0.4963],[0.4963, 0.4963, 0.4963]])
可以看到在没有偏移的情况下,b的数据都是a中的第一个数据,说明了(0, 0)不进行偏移,这很好理解。现在将(0, 0)改为(0, 1):
>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> b = torch.as_strided(a, (3, 3), (0, 1))>>> btensor([[0.4963, 0.7682, 0.0885],[0.4963, 0.7682, 0.0885],[0.4963, 0.7682, 0.0885]])
第一行与第二行的元素相等,而每列的元素不同,并且在tensor上从0,1,2开始一次增加一个,这说明第二个元素控制列,而改为(1, 0)得到如下结果:
>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> b = torch.as_strided(a, (3, 3), (1, 0))>>> btensor([[0.4963, 0.4963, 0.4963],[0.7682, 0.7682, 0.7682],[0.0885, 0.0885, 0.0885]])
这次是每列元素相等,而行不等,说明第一个参数控制行。这就可以理解了,第一个元素控制行,数字代表每次向后走时的跨度,而第二个控制列,如果改成(1, 1):
>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> b = torch.as_strided(a, (3, 3), (1, 1))>>> btensor([[0.4963, 0.7682, 0.0885],[0.7682, 0.0885, 0.1320],[0.0885, 0.1320, 0.3074]])
可以发现第二个参数控制的列,每次的开始值不是从原tensor的第0的数开始的,而是从生成视图中每行的第一个数据开始的。然后开始增加, 改为(1, 2)后:
>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> b = torch.as_strided(a, (3, 3), (1, 2))>>> btensor([[0.4963, 0.0885, 0.3074],[0.7682, 0.1320, 0.6341],[0.0885, 0.3074, 0.4901]])
这说明了,stride增加是将整个tensor排成一维数据一直增加的,如果此行数字不够会从下一行继续寻找。
总结:stride是指定步长,其中行从原数据第0个数据开始,而列从视图中行的第0个数据开始。将整个数组整合为1维数组后按步长进行寻找。
注意:由于创建出来的是视图,所以更改其中任何一个都会更改另一个,可能会产生意想不到的效果。例如:
>>> a = torch.rand(4, 4)>>> b = torch.as_strided(a, (3, 3), (1, 1))>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> btensor([[0.4963, 0.7682, 0.0885],[0.7682, 0.0885, 0.1320],[0.0885, 0.1320, 0.3074]])# ------------------------------------------------------------------------>>> a[0, 1] = 0>>> atensor([[0.4963, 0.0000, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> btensor([[0.4963, 0.0000, 0.0885],[0.0000, 0.0885, 0.1320],[0.0885, 0.1320, 0.3074]])
更改a[0, 1]=0,由于b[0, 1]和b[1, 0]都来自a[0, 1]。所以这俩也都会改变,反之亦然,有对应关系的都会改变,因为它们来自同一数据区,所以更改数据可能会出现一些意想不到的结果,不建议更改数据,尤其是视图数据。如果你实在需要更改的话,考虑将其克隆,使用Tensor.clone(),这样的话原数据和创建数据就不共享存储区了。
第四个参数 storage_offset比较简单,这里地列是从视图的每行第0个元素开始的,storage_offset这个参数用来控制从行的第几个参数开始,默认为0,指定后行从第storage_offset个元素开始。
>>> a = torch.rand(4, 4)>>> atensor([[0.4963, 0.7682, 0.0885, 0.1320],[0.3074, 0.6341, 0.4901, 0.8964],[0.4556, 0.6323, 0.3489, 0.4017],[0.0223, 0.1689, 0.2939, 0.5185]])>>> b = torch.as_strided(a, (3, 3), (1, 1), 1)>>> btensor([[0.7682, 0.0885, 0.1320],[0.0885, 0.1320, 0.3074],[0.1320, 0.3074, 0.6341]])
许多torch函数都可以返回视图,并且在此函数的内部实现,这些方法,例如torch.Tensor.expand更容易阅读,所以更推荐使用这些方法。
torch.empty_strided()
创建一个使用未初始化值填满的tensor,然后返回创建tensor的视图。
torch.empty_strided(size, stride, *, dtype=None, layout=None, device=None, requires_grad=False, pin_memory=False) → Tensor
注意:返回的是视图,所以对其直接进行修改会造成意想不到的效果,会修改原有的值,这样的会造成视图上可能很多值发生改变。不建议这样操作,建议先将其clone后进行修改。
此方法相当于torch.empty(size).as_strided(size, stride),也就是包含了两个方法,先创建empty的tensor,再创建在此tensor上的视图。[
](https://blog.csdn.net/Fluid_ray/article/details/109801981)
torch.full()
给定一个值fill_value和一个size,创建一个矩阵元素全为fill_value的大小为size的tensor。
torch.full(size, fill_value, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
例子:
>>> a = torch.full((3, 4), 5)>>> atensor([[5, 5, 5, 5],[5, 5, 5, 5],[5, 5, 5, 5]])>>> b = torch.full((3, 5), 10)>>> btensor([[10, 10, 10, 10, 10],[10, 10, 10, 10, 10],[10, 10, 10, 10, 10]])
torch.full_like()
将input的形状作为返回结果tensor的形状,其他形如torch.full()。
torch.full_like(input, fill_value, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, memory_format=torch.preserve_format) → Tensor
torch.sparse_coo_tensor()
创建一个Coordinate(COO) 格式的稀疏矩阵,返回值是一个tensor。
torch.sparse_coo_tensor(indices, values, size=None, dtype=None, device=None, requires_grad=False)
稀疏矩阵指矩阵中的大多数元素的值都为0,由于其中非常多的元素都是0,使用常规方法进行存储非常的浪费空间,所以采用另外的方法存储稀疏矩阵。
首先,要知道的是COO 格式的矩阵可以通过一个三元组表示,如下图右侧所示,从上到下依次为:
- 矩阵非零元素所在的行;
- 矩阵非零元素所在的列(与行位置匹配);
- 矩阵非零元素对应的值。
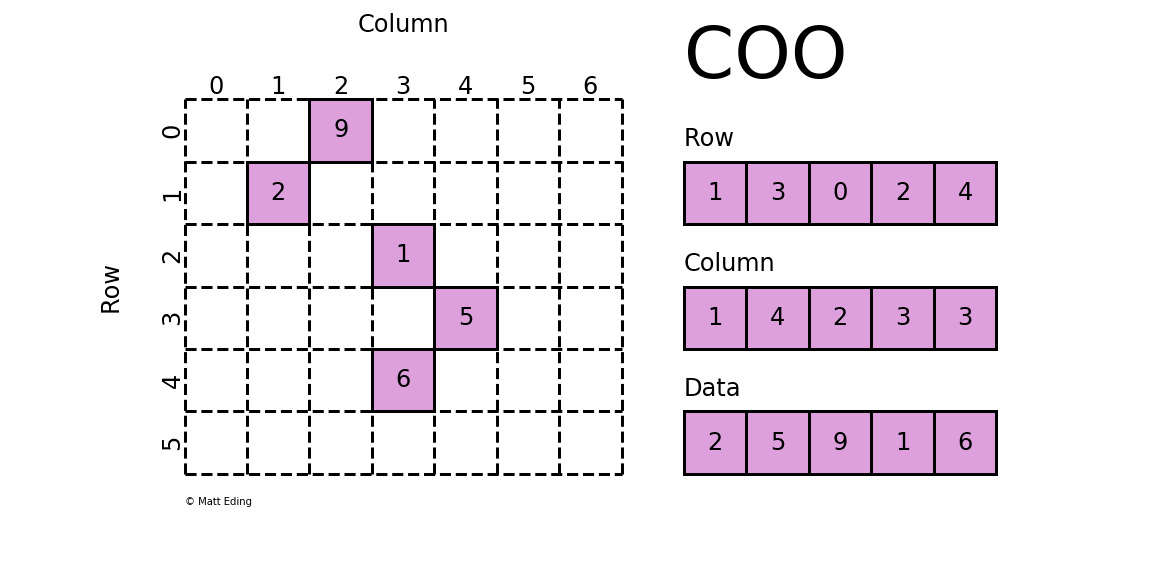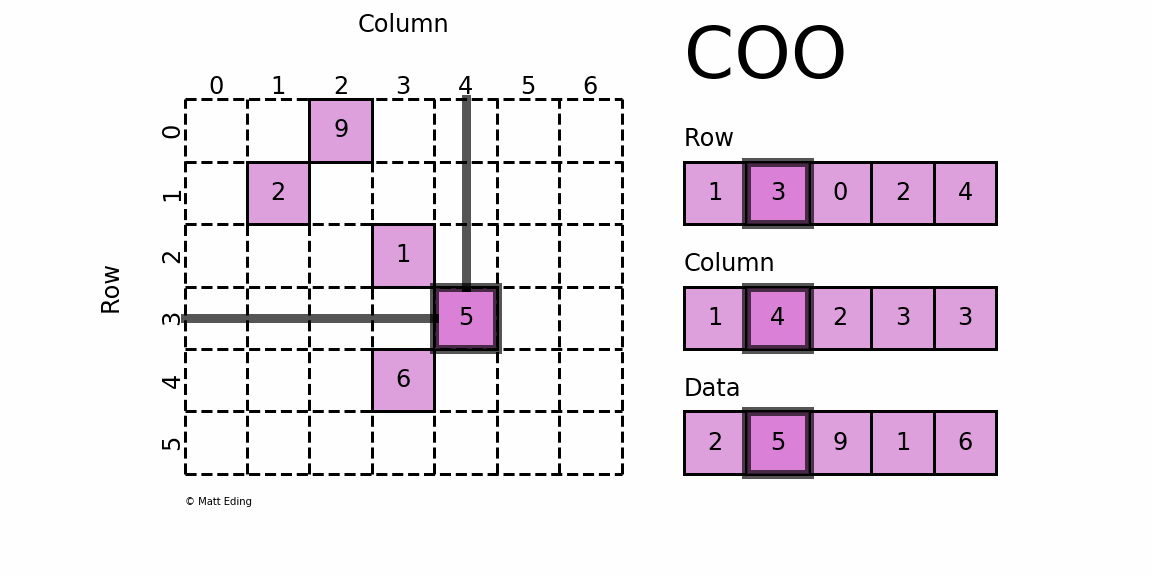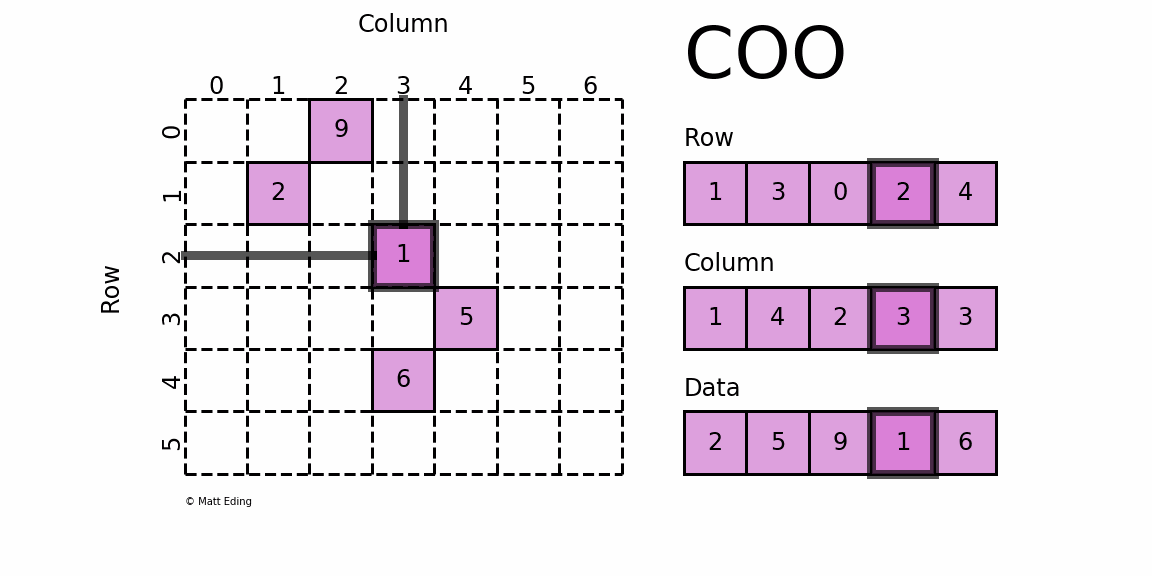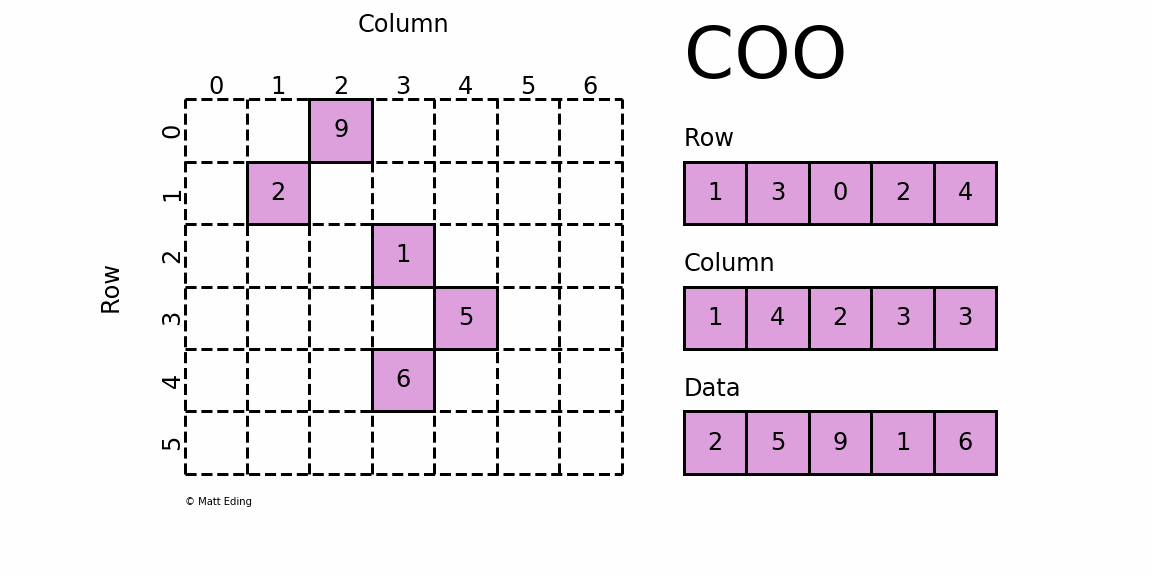
构造这样个矩阵需要知道所有非零数所在的行、所在的列、非零元素的值和矩阵的大小这四个值,所以此方法的参数就大概是这几个。
indices:此参数是指定非零元素所在的位置,也就是行和列,所以此参数应该是一个二维的数组,当然它可以是很多格式(list, tuple, NumPy ndarray, scalar, and other types )第一维指定了所有非零数所在的行数,第二维指定了所有非零元素所在的列数。例如indices=[[1, 4, 6], [3, 6, 7]]表示我们稀疏矩阵中(1, 3),(4, 6),(6, 7)几个位置是非零的数所在的位置。values:此参数指定了非零元素的值,所以此矩阵长度应该和上面的indices一样长也可以是很多格式(list, tuple, NumPy ndarray, scalar, and other types)。例如values=[1, 4, 5]表示上面的三个位置非零数分别为1, 4, 5。size:指定了稀疏矩阵的大小,例如size=[10, 10]表示矩阵大小为 ,此大小最小应该足以覆盖上面非零元素所在的位置,如果不给定此值,那么默认是生成足以覆盖所有非零值的最小矩阵大小。
,此大小最小应该足以覆盖上面非零元素所在的位置,如果不给定此值,那么默认是生成足以覆盖所有非零值的最小矩阵大小。dtype:指定返回tensor中数据的类型,如果不指定,那么采取values中数据的类型。device:指定创建的tensor在cpu还是cuda上。requires_grad:指定创建的tensor需不需要梯度信息,默认为False。
例子:
>>> indice = torch.tensor([[0, 1, 1], [2, 0, 2]])>>> values = torch.tensor([3, 4, 5], dtype=torch.float32)>>> torch.sparse_coo_tensor(indice, values, [2, 4])tensor(indices=tensor([[0, 1, 1],[2, 0, 2]]),values=tensor([3., 4., 5.]),size=(2, 4), nnz=3, layout=torch.sparse_coo)# ------------------------------------------------------------------------------>>> torch.sparse_coo_tensor(indice, values) # inferred as the minimum sizetensor(indices=tensor([[0, 1, 1],[2, 0, 2]]),values=tensor([3., 4., 5.]),size=(2, 3), nnz=3, layout=torch.sparse_coo)# ------------------------------------------------------------------------------>>> torch.sparse_coo_tensor(indice, values, [2, 4], dtype=torch.float64)tensor(indices=tensor([[0, 1, 1],[2, 0, 2]]),values=tensor([3., 4., 5.]),size=(2, 4), nnz=3, dtype=torch.float64, layout=torch.sparse_coo)
其中,nnz表示平均数非零元素。
torch.as_tensor()
将数据转化为tensor,这些数据可以是(list, tuple, NumPy ndarray, scalar, and other types)等等。
参数:
data:tensor的初始化数据。可以是 list, tuple, NumPy ndarray, scalar, and other types。dtype:tensor中数据的类型,如果不指定则使用data中的数据类型。device:指定了返回tensor所在的位置(cpu或者cuda),如果没有指定则使用当前默认设备,一般是cpu,当然也可以使用前面讲过的torch.set_default_tensor_type()来更改默认设置。
[
](https://blog.csdn.net/Fluid_ray/article/details/109648310)
注意:如果data已经是一个tensor并且与返回的tensor具有相同的类型和相同的设备,那么不会发生复制,返回的tensor就是data,否则是会进行复制的并且一个新的tensor会被返回且具有requires_grad=True,并保留计算图。相似的,如果data是一个相应dtype的ndarray,并且设备是cpu(numpy中的ndarray只能存在于cpu中),那么也不会进行任何复制,但是返回的是tensor,只是使用的内存相同。
>>> a = np.array([1, 2, 3])>>> t = torch.as_tensor(a)>>> ttensor([1, 2, 3], dtype=torch.int32)>>> t[0] = -1>>> aarray([-1, 2, 3])
由于a与t使用的是相同的内存区域,所以更改一个中的数据值,另一个也会更改。
>>> a = np.array([1, 2, 3])>>> t = torch.as_tensor(a, dtype=torch.float32) # 改变了类型>>> ttensor([1., 2., 3.])>>> t[0] = -1>>> aarray([1, 2, 3])>>> ttensor([-1., 2., 3.])
由于是进行值的复制,所以改变t不会改变a。
索引,切片,连接,换位
torch.cat()
在给定维度上对输入的张量序列seq进行连接操作。
- 第一个参数tensors是你想要连接的若干个张量,按你所传入的顺序进行连接,注意每一个张量需要形状相同,或者更准确的说,进行行连接的张量要求列数相同,进行列连接的张量要求行数相同。
- 第二个参数dim表示维度,dim=0则表示按行连接,dim=1表示按列连接
官方例子:torch.cat(inputs, dimension=0)
>>> x = torch.randn(2, 3)>>> xtensor([[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497]])>>> torch.cat((x, x, x), 0)tensor([[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497],[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497],[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497]])>>> torch.cat((x, x, x), 1)tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,-1.0969, -0.4614],[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,-0.5790, 0.1497]])
torch.chunk()
把一个tensor均匀分割成若干个小tensor,在给定维度上将输入张量进行分块。
- tensors(Tensors) 待分块的输入张量
- chunks (int) 分块的个数,如果该tensor在你要进行分割的维度上的
size不能被chunks整除,则最后一份会略小(也可能为空) - dim (int) 分割维度,
dim=0按行分割,dim=1表示按列分割
官方例子:torch.chunk(tensor, chunks, dim=0)
>>> torch.arange(11).chunk(6)(tensor([0, 1]),tensor([2, 3]),tensor([4, 5]),tensor([6, 7]),tensor([8, 9]),tensor([10]))>>> torch.arange(12).chunk(6)(tensor([0, 1]),tensor([2, 3]),tensor([4, 5]),tensor([6, 7]),tensor([8, 9]),tensor([10, 11]))>>> torch.arange(13).chunk(6)(tensor([0, 1, 2]),tensor([3, 4, 5]),tensor([6, 7, 8]),tensor([ 9, 10, 11]),tensor([12]))
torch.gather() 🧡🧡🧡
沿给定轴dim,将输入索引张量index指定位置的值进行聚合。(沿着给定的维度dim收集值)
- input(Tensor) - 源张量
- dim(int) - 索引的轴
- index(LongTensor) - 聚合元素的下标
- out - 目标张量
注意:index的维度要和input中dim所指的维度相同
torch.gather(input, dim, index, out=None)
在多分类中,torch.gather()常用来取出标签所对应的概率。
例子1:按照dim = 0, 取一个2*2 tensor的对角线上的数值
>>> a = torch.Tensor([[2, 5], [4, 7]])>>> index = torch.LongTensor([[0, 1]])>>> b = torch.gather(a, dim = 0, index=index)>>> atensor([[2., 5.],[4., 7.]])>>> btensor([[2., 7.]])
可以看到**dim=0**,即行方向的维度和index的维度是匹配的,就是说a和index由行方向从左往右看,有2列,即有2个样本,行方向是匹配的。另外,函数输出的**tensor**和**index**大小相同。上面代码的操作逻辑是:在a中,由行从左往右看,有两个样本,索引分别为0和1;每个样本有两个特征,每个特征中从上往下索引分别为0和1;依据index中的索引值,取第0样本的第0个特征2,再取第1个样本的第1个特征7。
例子2:按照dim = 1, 取一个2*2 tensor的对角线上的数值
>>> a = torch.Tensor([[2, 5], [4, 7]])>>> index = torch.LongTensor([[0], [1]])>>> c = torch.gather(a, dim = 1, index=index)>>> atensor([[2., 5.],[4., 7.]])>>> ctensor([[2.],[7.]])
可以看到dim=1,即列方向的维度和index的维度是匹配的,就是说a和index由列方向从上往下看,有2行,即有2个样本,列方向是匹配的。另外,函数输出的tensor和**index**大小相同。上面代码的操作逻辑是:在a中,由列从上往下看,有两个样本,索引分别为0和1;每个样本有两个特征,每个特征中从左往右索引分别为0和1;依据index中的索引值,取第0样本的第0个特征2,再取第1个样本的第1个特征7。
例子3:
>>> a = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])>>> index = torch.LongTensor([0, 2]).view(-1, 1)>>> indextensor([[0],[2]])>>> a.gather(1, index)tensor([[0.1000],[0.5000]])
torch.index_select()
沿指定维度对输入进行切片,取index中指定的相应项,然后返回一个新的张量,返回的张量与原始张量有相同的维度(在指定轴上),返回的张量与原始张量不共享内存空间。
- input(Tensor) - 输入张量
- dim(int) - 索引的轴
- index(LongTensor) - 包含索引下标的一维张量
- out - 目标张量
例子:torch.index_select(input, dim, index, out=None)
>>> x = torch.rand(3, 4)>>> xtensor([[0.6977, 0.8000, 0.1610, 0.2823],[0.6816, 0.9152, 0.3971, 0.8742],[0.4194, 0.5529, 0.9527, 0.0362]])>>> indices = torch.tensor([0, 2])>>> a = torch.index_select(x, 0, indices)>>> b = torch.index_select(x, 1, indices)>>> atensor([[0.6977, 0.8000, 0.1610, 0.2823],[0.4194, 0.5529, 0.9527, 0.0362]])>>> btensor([[0.6977, 0.1610],[0.6816, 0.3971],[0.4194, 0.9527]])
torch.masked_select()
根据掩码张量mask中的二元值,取输入张量中的指定项,将取值返回到一个新的1D张量。
张量mask须跟input张量有相同的元素数目,但形状或维度不需要相同。
注意:返回的张量不与原始张量共享内存空间
- input(Tensor) - 输入张量
- mask(BoolTensor) - 掩码张量,包含了二元索引值
- out - 目标张量
官方例子:torch.masked_select(input, mask, out=None)
例子2:>>> x = torch.randn(3, 4)tensor([[-1.0712, 0.1227, -0.5663, 0.3731],[-0.8920, -1.5091, 0.3704, 1.4565],[ 0.9398, 0.7748, 0.1919, 1.2638]])>>> mask = x.ge(0.5) # 大于等于0.5,返回一个bool类型的tensor>>> torch.masked_select(x, mask)tensor([1.4565, 0.9398, 0.7748, 1.2638])
>>> x = torch.randn(3,4)tensor([[-1.0712, 0.1227, -0.5663, 0.3731],[-0.8920, -1.5091, 0.3704, 1.4565],[ 0.9398, 0.7748, 0.1919, 1.2638]])>>> mask = torch.BoolTensor(x > 0)>>> torch.masked_select(x, mask)tensor([0.1227, 0.3731, 0.3704, 1.4565, 0.9398, 0.7748, 0.1919, 1.2638])
torch.nonzero()
返回一个包含输入input中非零元素索引的张量,输出张量中的每行包含输入中非零元素的索引。若输入input有n维,则输出的索引张量output形状为z * n, 这里z是输入张量input中所有非零元素的个数。
- input(Tensor) - 输入张量
- out - 包含索引值的结果张量
例子:torch.nonzero(input, out=None)
>>> torch.nonzero(torch.Tensor([1, 1, 1, 0, 1]))tensor([[0],[1],[2],[4]])>>> torch.nonzero(torch.Tensor([[0.6, 0.0, 0.0, 0.0],[0.0, 0.4, 0.8, 0.0],[0.0, 0.0, 1.2, 0.0],[0.0, 0.0, 0.0, -0.4]]))tensor([[0, 0],[1, 1],[1, 2],[2, 2],[3, 3]])
torch.split()
将输入张量分割成相等形状的chunks(如果可分)。如果沿指定维的张量形状大小不能被split_size整分,则最后一个分块会小于其它分块。
- tensor(Tensor) - 待分割张量
- split_size(int) - 单个分块的形状大小
- dim(int) - 沿着此维进行分割
官方例子:torch.split(tensor, split_size, dim=0)
>>> a = torch.arange(10).reshape(5, 2)>>> torch.split(a, 2)(tensor([[0, 1],[2, 3]]),tensor([[4, 5],[6, 7]]),tensor([[8, 9]]))>>> torch.split(a, [1, 4])(tensor([[0, 1]]),tensor([[2, 3],[4, 5],[6, 7],[8, 9]]))
torch.squeeze()
将输入张量形状中的1去除并返回。如果输入是形如 ,那么输出形状就为:
,那么输出形状就为: 。
。
当给定dim时,则只在给定维度上进行挤压,如输入形状为 ,
,squeeze(input, 0),将会保持张量不变,只有用squeeze(input, 1),形状会变成 。
。
注意:输入张量与返回张量共享内存。
- input(Tensor) - 输入张量
- dim(int, optional) - 如果给定,则只在给定维度挤压
- out(Tensor, optional) - 输出张量
torch.squeeze(input, dim=None, out=None)
torch.unsequeeze()
用于矩阵维度的扩充。返回一个新的张量,对输入的指定位置插入维度1。
注意:返回张量与输入张量共享内存。
- tensor(Tensor) - 输入张量
- dim(int) - 插入维度的索引
- out(Tensor, optional) - 结果张量
torch.unsequeeze(input, dim, out=None)
torch.stack()
沿着一个新维度对输入张量进行连接,序列中所有张量都应该为相同的形状。
浅显地说,也就是把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…以此类推,也就是在增加新的维度进行堆叠。
- sequence(Sequence) - 待连接的张量序列。函数中的输入
inputs只允许是序列;且序列内部的张量元素,必须shape相等 - dim(int) - 新的维度,必须在0到
len(outputs)之间。len(outputs)是生成数据的维度大小,也就是outputs的维度值。
torch.stack(sequence, dim=0)
例子:
>>> T1 = torch.tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])>>> T2 = torch.tensor([[10, 20, 30],[40, 50, 60],[70, 80, 90]])>>> torch.stack((T1, T2), dim=0).shapetorch.Size([2, 3, 3])>>> torch.stack((T1, T2), dim=1).shapetorch.Size([3, 2, 3])
在自然语言处理和卷及神经网络中, 通常为了保留序列信息和张量的矩阵信息才会使用stack函数。
torch.t()
输入一个矩阵(2维张量),并转置0,1维,可以被视为transpose(input, 0, 1)的简写函数
- input(Tensor) - 输入张量
- out(Tensor, optional) - 结果张量
注意:该函数要求输入的tensor结构维度 2D。当input维度为0D或者1D时,不做改变输出本身,维度为2D时,输出维度的转置。
2D。当input维度为0D或者1D时,不做改变输出本身,维度为2D时,输出维度的转置。
torch.t(input, out=None)
官方例子:
>>> x = torch.randn(())>>> xtensor(0.1995)>>> torch.t(x)tensor(0.1995)>>> x = torch.randn(3)>>> xtensor([ 2.4320, -0.4608, 0.7702])>>> torch.t(x)tensor([ 2.4320, -0.4608, 0.7702])>>> x = torch.randn(2, 3)>>> xtensor([[ 0.4875, 0.9158, -0.5872],[ 0.3938, -0.6929, 0.6932]])>>> torch.t(x)tensor([[ 0.4875, 0.3938],[ 0.9158, -0.6929],[-0.5872, 0.6932]])
torch.transpose()
返回输入矩阵input的转置,交换维度dim0和dim1。
- input(Tensor) - 输入张量
- dim0(int) - 转置的第一维
- dim1(int) - 转置的第二维
输入张量与输出张量共享内存。
torch.transpose(input, dim0, dim1, out=None)
官方例子:
>>> x = torch.randn(2, 3)>>> xtensor([[ 1.0028, -0.9893, 0.5809],[-0.1669, 0.7299, 0.4942]])>>> torch.transpose(x, 0, 1)tensor([[ 1.0028, -0.1669],[-0.9893, 0.7299],[ 0.5809, 0.4942]])
torch.unbind()
移除指定维度后,返回一个元组,包含了沿着指定维切片后的各个切片。
- tensor(Tensor) - 输入张量
- dim(int) - 删除的维度
注意:不改变原来的tensor的torch.unbind(tensor, dim=0)
shape,只是返回展开后的切片。
官方例子:
>>> torch.unbind(torch.tensor([[1, 2, 3],>>> [4, 5, 6],>>> [7, 8, 9]]))(tensor([1, 2, 3]), tensor([4, 5, 6]), tensor([7, 8, 9]))
torch.where()
按照一定的规则合并两个tensor类型。
condition是条件,x 和 y 是同shape的矩阵,针对矩阵中的某个位置的元素,满足条件就返回x,不满足就返回y。
torch.where(condition, x, y)
例子:
>>> a = torch.rand(3, 2)>>> b = torch.ones(3, 2)>>> c = torch.where(a > 0.5, b, a) # 让a中所有大于0.5的数为1.0>>> atensor([[0.6984, 0.5675],[0.8352, 0.2056],[0.5932, 0.1123]])>>> ctensor([[1.0000, 1.0000],[1.0000, 0.2056],[1.0000, 0.1123]])
torch.where()的用法其实很简单。但是如果现在的condition条件改为判断是否在一个范围里呢?比如现在让a中的所有数只要在0.4-0.6之间,就强行置为1,怎样实现?很容易想到:
a = torch.rand(3, 2)b = torch.ones(3, 2)c = torch.where(0.4 < a < 0.6, b, a)
很遗憾,这样会报错,错误如下:
什么意思呢?其实错误就在0.4 < a < 0.6这里。这个错误的具体含义是具有多个值的张量的布尔值是不明确的。怎么解决?可以拆分成a > 0.4和a < 0.6来看。这两个结果都是bool值,那么可以对这两个结果做运算,就可以得到我们想要的结果了。
比如,因为拆分后的两个结果都是bool值,我们可以对bool值做乘法,使得同时满足两个条件的bool值乘起来之后为True。
>>> a = torch.rand(3, 2)>>> atensor([[0.7745, 0.4369],[0.5191, 0.6159],[0.8102, 0.9801]])>>> b = torch.ones(3, 2)>>> c = torch.where((a > 0.4) * (a < 0.6), b, a)>>> ctensor([[0.7745, 1.0000],[1.0000, 0.6159],[0.8102, 0.9801]])
随机抽样 Random sampling
torch.manual_seed()
设定生成随机数的种子,并返回一个torch._C.Generator对象
- CPU生成随机数的种子。取值范围为
[-0x8000000000000000, 0xffffffffffffffff],十进制是[-9223372036854775808, 18446744073709551615],超出该范围将触发RuntimeError报错。torch.manual_seed(seed)
torch.manual_seed()一般和torch.rand()、torch.randn()等函数搭配使用。通过指定seed值,可以令每次生成的随机数相同。如果不指定seed值,则每次生成的随机数会因时间的差异而有所不同
需注意,不是执行一次torch.manual_seed()语句后,所有随机函数的生成结果就都相同了;而是每次执行设有相同seed值的torch.manual_seed()语句后,各随机函数生成的结果都能和上一次执行torch.manual_seed()语句后生成的结果相同。
设置随机种子后,是每次运行
.py文件的输出结果都一样,而不是每次随机函数生成的结果一样。
>>> torch.manual_seed(0)>>> print(torch.randn(1, 2))tensor([[ 1.5410, -0.2934]])>>> print(torch.randn(1, 2))tensor([[-2.1788, 0.5684]])>>> torch.manual_seed(0)>>> print(torch.randn(1, 2))tensor([[ 1.5410, -0.2934]])>>> print(torch.randn(1, 2))tensor([[-2.1788, 0.5684]])
需注意,必须使用相同的生成随机数函数才能保证每次执行 torch.manual_seed()语句后生成相同随机数,否则无效。
>>> torch.manual_seed(0)>>> print(torch.rand(1, 2))tensor([[0.4963, 0.7682]])>>> torch.manual_seed(0)>>> print(torch.randn(1, 2))tensor([[ 1.5410, -0.2934]])
torch.manual_seed()为CPU设置随机数种子,torch.cuda.manual_seed()为GPU设置随机数种子,torch.cuda.manual_seed_all()为所有的GPU设置随机数种子,random.seed()为random模块的随机数种子。
torch.initial_seed()
返回生成随机数的原始种子值
torch.initial_seed()
例子:
>>> torch.manual_seed(4)torch._C.Generator object at 0x0000019684586350>>>> torch.initial_seed()4
torch.get_rng_state()
返回随机生成器状态(ByteTensor)
torch.rng_state()
例子:
>>> torch.initial_seed()4>>> torch.get_rng_state()tensor([4, 0, 0, ..., 0, 0, 0], dtype=torch.uint8)
torch.set_rng_state()
设定随机生成器状态参数:
- new_state(torch.ByteTensor) - 期望的状态
torch.set_rng_state(new_state)
torch.default_generator
默认的随机生成器。等于<torch._C.Generator object>。
torch.bernoulli()
从伯努利分布中抽取二元随机数(0或者1),输入张量包含用于抽取二元值的概率。因此,输入中所有值必须在[0, 1]区间。输出张量的第i个元素值,将以输入张量的第i个概率值等于1。
返回值将会是与输入相同大小的张量,每个值为0或1。
- input(Tensor) - 输入为伯努利分布的概率值
- out(Tensor, optional)
例子:torch.bernoulli(input, out=None)
>>> a = torch.Tensor(3, 3).uniform_(0, 1)>>> atensor([[0.5596, 0.5591, 0.0915],[0.2100, 0.0072, 0.0390],[0.9929, 0.9131, 0.6186]])>>> torch.bernoulli(a)tensor([[0., 1., 0.],[0., 0., 0.],[1., 1., 1.]])
torch.multinomial()
返回一个张量,每行包含从input相应行中定义的多项式分布中抽取的num_samples个样本。要求输入input每行的值不需要总和为1,但是必须非负且总和不能为0。
当抽取样本时,依次从左到右排列(第一个样本对应第一列)。如果输入input是一个向量,输出out也是一个相同长度num_samples的向量。如果输入input是m行的矩阵,输出out是形如 的矩阵。并且如果参数
的矩阵。并且如果参数replacement为True,则样本抽取可以重复。否则,一个样本在每行不能被重复。
- input(Tensor) - 包含概率值的张量
- num_samples(int) - 抽取的样本数
- replacement(bool, optional) - 布尔值,决定是否能重复抽取
- out(Tensor, optional)
例子:torch.multinomial(input, num_samples, replacement=False, out=None)
>>> weights = torch.Tensor([0, 10, 3, 0])>>> weightstensor([ 0., 10., 3., 0.])>>> torch.multinomial(weights, 4, replacement=True)tensor([1, 1, 1, 1])
torch.normal()
返回一个张量,包含从给定means,std的离散正态分布中抽取随机数。均值means是一个张量,包含每个输出元素相关的正态分布的均值。std是一个张量。包含每个输出元素相关的正态分布的标准差。
注意:均值和标准差的形状不须匹配,但每个张量的元素个数须相同。
- means(Tensor) - 均值
- std(Tensor) - 标准差
- out(Tensor, optional)
例子:torch.normal(means, std, out=None)
>>> n_data = torch.ones(5, 2)>>> n_datatensor([[1., 1.],[1., 1.],[1., 1.],[1., 1.],[1., 1.]])>>> x0 = torch.normal(2 * n_data, 1)>>> x0tensor([[1.6544, 0.9805],[2.1114, 2.7113],[1.0646, 1.9675],[2.7652, 3.2138],[1.1204, 2.0293]])
torch.rand()
返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。详情见上文:torch.rand()
torch.rand(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)→ Tensor
torch.rand_like()
功能和torch.rand()完全相同,只是输出的shape和input.shape相同。
torch.rand_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor
torch.randint()
返回一个填充了随机整数的张量,这些整数在low(inclusive) 和high(exclusive) 之间均匀生成。张量的shape由变量参数size定义。
注意:左闭右开。
torch.randint(low=0, high, size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
当生成一个维或一个数值时,需要注意: np.random.randint()可以省略size,直接生成一个数; 但是torch.randint不可以省略,而且需要加上逗号,否则无法生成。
>>> np.random.randint(low=0, high=10, dtype=int)8>>> torch.randint(low=0, high=10, size=(1,), dtype=int)tensor([3])
torch.randint_like()
功能和torch.randint()完全相同,只是输出的shape和input.shape相同。
torch.randint_like(input, low=0, high, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
torch.randn()
返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。详情见上文:torch.randn()
torch.randn(*sizes, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)→ Tensor
torch.randn_like()
功能和torch.randn()完全相同,只是输出的shape和input.shape相同。
torch.randn_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor
torch.randperm()
返回 0 到n-1之间,所有数字的一个随机排列。详情见上文:torch.randperm()。
torch.randperm(n, out=None, dtype=torch.int64, layout=torch.strided, device=None, requires_grad=False) → LongTensor
序列化 Serialization
torch.save()
保存一个对象到一个硬盘文件上。
- obj - 保存对象
- f - 类文件对象
- pickle_module - 用于pickling元数据和对象的模块
- pickle_protocol - 指定pickle protocal可以覆盖默认参数
torch.save(obj, f, pickle_module, pickle_protocol=2)
保存数据:
>>> x = torch.tensor([0, 1, 2, 3, 4])>>> torch.save(x, 'tensor.pt')
保存模型:保存模型主要分为两类:保存整个模型和只保存模型参数。
保存加载整个模型(不推荐):保存整个网络模型,网络结构+权重参数
torch.save(model,'net.pth')
加载网络模型,可能比较耗时。
只保存加载模型参数(推荐)保存模型的权重参数(速度快,占内存少)
torch.save(model.state_dict(),'net_params.pth')
上面“保存加载整个模型”加载的net.pt其实是一个字典,通常包含以下内容:
- 网络结构:输入尺寸,输出尺寸以及隐藏层的信息,以便能够在加载时重建模型。
- 模型的权重参数:包含各网络层训练后的可学习参数,可以在模型实例上调用state_dict()方法来获取,比如只保存模型权重参数时用到的model.state_dict().
- 优化器参数:有时保存模型的参数需要稍后接着训练,那么就必须保存优化器的状态和其所使用的超参数,也是在优化器实例上调用state_dict()方法来获取这些参数。
- 其他信息:有时我们需要保存一些其他的信息,比如epoch, batch_size等超参数
[
](https://blog.csdn.net/weixin_38145317/article/details/111152491)
所以其实我们可以自定义需要保存的内容
checkpoint={'modle':ClassNet(),'model_state_dict':model.state_dict(),'optimize_state_dict':optimizer.state_dict(),'epoch':epoch}torch.save(checkpoint,'checkpoint.pkl')
上面的checkpoint是个字典,里面有4各键值对,分别表示网络模型的不同信息。
保存多个模型到一个文件:
torch.save({'modelA_state_dict': modelA.state_dict(),'modelB_state_dict': modelB.state_dict(),'optimizerA_state_dict': optimizerA.state_dict(),'optimizerB_state_dict': optimizerB.state_dict(),...}, PATH)
torch.load()
从磁盘文件中读取一个通过torch.save()保存的对象,可通过参数map_location动态地进行内存重映射。
- f - 类文件对象
- map_location - 一个函数或字典规定如何remap存储位置
- pickle_module - 用于unpickling元数据和对象的模块
torch.load(f, map_location=None, pickle_module=2)
如果加载模型只是为了进行推理测试,则将每一层的requires_grad置为False,即固定这些权重参数,还需要调用model.eval()将模型置为测试模式,主要是将dropout和batch normalization层进行固定,否则模型的预测结果每次都会不同。如果需要继续训练,则调用model.train(),以确保网络模型处于训练模式。
在CPU上加载在GPU上训练并保存的模型(save on GPU, load on CPU)
device=torch.device('cpu')model=TheModelClass()#load all tensors onto the CPU devicemodel.load_state_dict(torch.load('net_params.pkl',map_location=device))
令torch.load()函数的map_location参数等于torch.device('cpu')即可,这里令map_location参数等于cpu也同样可以。
从一个文件加载多个模型:
modelA = TheModelAClass(*args, **kwargs)modelB = TheModelBClass(*args, **kwargs)optimizerA = TheOptimizerAClass(*args, **kwargs)optimizerB = TheOptimizerBClass(*args, **kwargs)checkpoint = torch.load(PATH)modelA.load_state_dict(checkpoint['modelA_state_dict'])modelB.load_state_dict(checkpoint['modelB_state_dict'])optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])modelA.eval() # or modelA.train()modelB.eval() # or modelB.train()
并行化 Parallelism
torch.get_num_threads()
获得用于并行化CPU操作的OpenMP线程数
torch.get_num_threads() → int
torch.set_num_threads()
设定用于并行化CPU操作的OpenMP线程数
torch.set_num_threads(int)
数学操作 Math operations
Pointwise Ops
torch.abs()
计算输入张量的每个元素绝对值。
- input(Tensor) - 输入张量
- out(Tensor, optional) - 结果张量
官方例子:torch.abs(input, out=None)
>>> torch.abs(torch.tensor([-1, -2, 3]))tensor([ 1, 2, 3])
torch.acos()
返回一个新张量,包含输入张量每个元素的反余弦。
- input(Tensor) - 输入张量
- out(Tensor, optional)
官方例子:torch.acos(input, out=None)
>>> a = torch.randn(4)>>> atensor([ 0.3348, -0.5889, 0.2005, -0.1584])>>> torch.acos(a)tensor([ 1.2294, 2.2004, 1.3690, 1.7298])
torch.add()
对输入张量input逐元素加上标量值value,并返回结果到一个新的张量。
- input(Tensor) - 输入张量
- value(Number) - 添加到输入每个元素的数
- out(Tensor, optional)
官方例子:torch.add(input, value, out=None)
>>> a = torch.randn(4)>>> atensor([ 0.0202, 1.0985, 1.3506, -0.6056])>>> torch.add(a, 20)tensor([ 20.0202, 21.0985, 21.3506, 19.3944])
torch.addcdiv()
用tensor2对tensor1逐元素相除,然后乘以标量值value并加到tensor上。
- tensor(Tensor) - 张量
- value(Number, optional) - 标量
- tensor1(Tensor) - 张量,作为分子
- tensor2(Tensor) - 张量,作为分母
- out(Tensor, optional)
张量的形状不需要匹配,但元素数量必须一致。如果输入是FloatTensor或DoubleTensor类型,则value必须为实数,否则须为整数。
torch.addcdiv(tensor, value=1, tensor1, tensor2, out=None)
官方例子:
>>> t = torch.randn(1, 3)>>> t1 = torch.randn(3, 1)>>> t2 = torch.randn(1, 3)>>> torch.addcdiv(t, 0.1, t1, t2)tensor([[-0.2312, -3.6496, 0.1312],[-1.0428, 3.4292, -0.1030],[-0.5369, -0.9829, 0.0430]])
torch.addcmul()
用tensor2对tensor1逐元素相乘,并对结果乘以标量值value然后加到tensor,张量形状不需要匹配,但元素数量必须一致。
- tensor(Tensor) - 张量
- value(Number, optional) - 标量
- tensor1(Tensor) - 张量,乘子1
- tensor2(Tensor) - 张量,乘子2
- out(Tensor, optional)
官方例子:torch.addcmul(tensor, value=1, tensor1, tensor2, out=None)
>>> t = torch.randn(1, 3)>>> t1 = torch.randn(3, 1)>>> t2 = torch.randn(1, 3)>>> torch.addcmul(t, 0.1, t1, t2)tensor([[-0.8635, -0.6391, 1.6174],[-0.7617, -0.5879, 1.7388],[-0.8353, -0.6249, 1.6511]])
torch.asin()
返回一个新张量,包含输入input张量每个元素的反正弦函数
- input(Tensor) - 输入张量
- out(Tensor, optional)
官方例子:torch.asin(input, out=None)
>>> a = torch.randn(4)>>> atensor([-0.5962, 1.4985, -0.4396, 1.4525])>>> torch.asin(a)tensor([-0.6387, nan, -0.4552, nan])
torch.atan()
返回一个新张量,包含输入input张量每个元素的反正切函数
- input(Tensor)
- out(Tensor, optional)
官方例子:torch.atan(input, out=None)
>>> a = torch.randn(4)>>> atensor([ 0.2341, 0.2539, -0.6256, -0.6448])>>> torch.atan(a)tensor([ 0.2299, 0.2487, -0.5591, -0.5727])
torch.atan2()
返回一个新张量,包含两个输入张量input1和input2的反正切函数
- input1(Tensor) - 第一个输入张量
- input2(Tensor) - 第二个输入张量
- out(Tensor, optional)
官方例子:torch.atan2(input1, input2, out=None)
>>> a = torch.randn(4)>>> atensor([ 0.9041, 0.0196, -0.3108, -2.4423])>>> torch.atan2(a, torch.randn(4))tensor([ 0.9833, 0.0811, -1.9743, -1.4151])
torch.ceil()
对输入input张量每个元素向上取整,即取不小于每个元素的最小整数,并返回结果到输出
- input(Tensor) - 输入张量
- out(Tensor, optional)
官方例子:torch.ceil(input, out=None)
>>> a = torch.randn(4)>>> atensor([-0.6341, -1.4208, -1.0900, 0.5826])>>> torch.ceil(a)tensor([-0., -1., -1., 1.])
torch.clamp()
将输入input张量每个元素值约束到区间[min, max],并返回结果到一个新张量。也可以只设定**min**或只设定**max**。
- input(Tensor) - 输入张量
- min(Number) - 限制范围下限
- max(Number) - 限制范围上限
- out(Tensor, optional)
官方例子:torch.clamp(input, min, max, out=None)
>>> a = torch.randn(4)>>> atensor([-1.7120, 0.1734, -0.0478, -0.0922])>>> torch.clamp(a, min=-0.5, max=0.5)tensor([-0.5000, 0.1734, -0.0478, -0.0922])
torch.cos()
返回一个新张量,包含输入input张量每个元素的余弦。
- input(Tensor)
- out(Tensor, optional)
官方例子:torch.cos(input, out=None)
>>> a = torch.randn(4)>>> atensor([ 1.4309, 1.2706, -0.8562, 0.9796])>>> torch.cos(a)tensor([ 0.1395, 0.2957, 0.6553, 0.5574])
torch.cosh()
- input(Tensor)
- out(Tensor, optional)
官方例子:torch.cosh(input, out=None)
>>> a = torch.randn(4)>>> atensor([ 0.1632, 1.1835, -0.6979, -0.7325])>>> torch.cosh(a)tensor([ 1.0133, 1.7860, 1.2536, 1.2805])
torch.div()
将input逐元素除以拎一个张量other,并返回结果到输出张量out。
- input(Tensor) - 输入张量
- value(Number) - 除数
- out(Tensor, optional)
官方例子:torch.div(input, other, out=None) → Tensor
>>> a = torch.randn(4, 4)>>> atensor([[-0.3711, -1.9353, -0.4605, -0.2917],[ 0.1815, -1.0111, 0.9805, -1.5923],[ 0.1062, 1.4581, 0.7759, -1.2344],[-0.1830, -0.0313, 1.1908, -1.4757]])>>> b = torch.randn(4)>>> btensor([ 0.8032, 0.2930, -0.8113, -0.2308])>>> torch.div(a, b)tensor([[-0.4620, -6.6051, 0.5676, 1.2637],[ 0.2260, -3.4507, -1.2086, 6.8988],[ 0.1322, 4.9764, -0.9564, 5.3480],[-0.2278, -0.1068, -1.4678, 6.3936]])
torch.exp()
返回一个新张量,包含输入input张量每个元素的指数。
- input(Tensor)
- out(Tensor, optional)
官方例子:torch.exp(tensor, out=None)
>>> torch.exp(torch.tensor([0, math.log(2.)]))tensor([ 1., 2.])
torch.floor()
返回一个新张量,包含输入input张量每个元素的floor,即不大于元素的最大整数。
- input(Tensor)
- out(Tensor, optional)
官方例子:torch.floor(input, out=None)
>>> a = torch.randn(4)>>> atensor([-0.8166, 1.5308, -0.2530, -0.2091])>>> torch.floor(a)tensor([-1., 1., -1., -1.])
torch.fmod()
计算除法余数,余数的正负与被除数相同
- input(Tensor)
- divisor(Tensor or float) - 除数
- out(Tensor, optional)
官方例子:torch.fmod(input, divisor, out=None)
>>> torch.fmod(torch.tensor([-3., -2, -1, 1, 2, 3]), 2)tensor([-1., -0., -1., 1., 0., 1.])>>> torch.fmod(torch.tensor([1., 2, 3, 4, 5]), 1.5)tensor([ 1.0000, 0.5000, 0.0000, 1.0000, 0.5000])
torch.frac()
返回每个元素的分数部分
torch.frac(tensor, out=None)
官方例子:
>>> torch.frac(torch.tensor([1, 2.5, -3.2]))tensor([ 0.0000, 0.5000, -0.2000])
torch.lerp()
对两个张量以start, end做线性插值,将结果返回到输出张量。
- start(Tensor) - 起始点张量
- end(Tensor) - 终止点张量
- weight(float) - 插值公式中的weight
- out(Tensor, optional)
官方例子:torch.lerp(start, end, weight, out=None)
>>> start = torch.arange(1., 5.)>>> end = torch.empty(4).fill_(10)>>> starttensor([ 1., 2., 3., 4.])>>> endtensor([ 10., 10., 10., 10.])>>> torch.lerp(start, end, 0.5)tensor([ 5.5000, 6.0000, 6.5000, 7.0000])>>> torch.lerp(start, end, torch.full_like(start, 0.5))tensor([ 5.5000, 6.0000, 6.5000, 7.0000])
torch.log()
计算input的自然对数
torch.log(input, out=None)
torch.log1p()
计算input + 1的自然对数 。对值比较小的输入,此函数比
。对值比较小的输入,此函数比**torch.log()**更准确。
- input(Tensor)
- out(Tensor, optional)
torch.log1p(input, out=None)
torch.mul()
两个张量input,other按元素相乘,并返回到输出张量,两个张量形状不须匹配,但总元素数须一致。当形状不匹配时,input的形状作为输出张量的形状
- input(Tensor) - 第一个张量
- other(Tensor) - 第二个张量
- out(Tensor, optional)
官方例子:torch.mul(input, other, out=None)
>>> a = torch.randn(4, 1)>>> atensor([[ 1.1207],[-0.3137],[ 0.0700],[ 0.8378]])>>> b = torch.randn(1, 4)>>> btensor([[ 0.5146, 0.1216, -0.5244, 2.2382]])>>> torch.mul(a, b)tensor([[ 0.5767, 0.1363, -0.5877, 2.5083],[-0.1614, -0.0382, 0.1645, -0.7021],[ 0.0360, 0.0085, -0.0367, 0.1567],[ 0.4312, 0.1019, -0.4394, 1.8753]])
torch.neg()
返回一个新张量,包含输入input张量按元素取负。
torch.neg(input, out=None)
torch.pow()
对输入input按元素求exponent次幂,并返回结果张量。幂可以为float数或与input相同元素数的张量
- input(Tensor) - 输入张量
- exponent(float or Tensor) - 幂值
- out(Tensor, optional)
如果torch.pow(input, exponent, out=None)
exponent是标量:
如果exponent是张量:
官方例子: ```pythona = torch.randn(4) a tensor([ 0.4331, 1.2475, 0.6834, -0.2791]) torch.pow(a, 2) tensor([ 0.1875, 1.5561, 0.4670, 0.0779]) exp = torch.arange(1., 5.)
a = torch.arange(1., 5.) a tensor([ 1., 2., 3., 4.]) exp tensor([ 1., 2., 3., 4.]) torch.pow(a, exp) tensor([ 1., 4., 27., 256.]) ```
- 如果
base为标量,input为张量。
官方例子:
>>> exp = torch.arange(1., 5.)>>> base = 2>>> torch.pow(base, exp)tensor([ 2., 4., 8., 16.])
torch.reciprocal()
返回一个新张量,包含输入input张量每个元素的倒数,即1.0/x
torch.reciprocal(input, out=None)
官方例子:
>>> a = torch.randn(4)>>> atensor([-0.4595, -2.1219, -1.4314, 0.7298])>>> torch.reciprocal(a)tensor([-2.1763, -0.4713, -0.6986, 1.3702])
torch.remainder()
返回一个新张量,包含输入input张量每个元素的除法余数,余数与除数有相同的符号。
- input(Tensor) - 被除数
- divisor(Tensor or float) - 除数
- out(Tensor, optional)
官方例子:torch.remainder(input, divisor, out=None)
>>> torch.remainder(torch.tensor([-3., -2, -1, 1, 2, 3]), 2)tensor([ 1., 0., 1., 1., 0., 1.])>>> torch.remainder(torch.tensor([1., 2, 3, 4, 5]), 1.5)tensor([ 1.0000, 0.5000, 0.0000, 1.0000, 0.5000])
torch.round()
返回一个新张量,将输入input张量每个元素四舍五入到最近的整数。
torch.round(input, out=None)
torch.rsqrt()
返回一个新张量,包含输入input张量每个元素的平方根倒数。
torch.rsqrt(input, out=None)
torch.sigmoid()
返回一个新张量,包含输入input张量每个元素的sigmoid值。
torch.sigmoid(input, out=None)
torch.sign()
符号函数:返回一个新张量,包含输入input张量每个元素的正负。
torch.sign(input, out=None)
torch.sin()
返回一个新张量,包含输入input张量每个元素的正弦。
torch.sin(input, out=None)
torch.sinh()
返回一个新张量,包含输入input张量每个元素的双曲正弦。
torch.sinh(input, out=None)
torch.sqrt()
返回一个新张量,包含输入input张量每个元素的平方根。
torch.sqrt(input, out=None)
torch.tan()
返回一个新张量,包含输入input张量每个元素的正切。
torch.tan(input, out=None)
torch.tanh()
返回一个新张量,包含输入input张量每个元素的双曲正切。
torch.tanh(input, out=None)
torch.trunc()
返回一个新张量,包含输入input张量每个元素的截断值,使更接近零。即有符号数的小数部分被舍弃。
torch.trunc(input, out=None)
Reduction Ops
torch.cumprod()
返回输入沿指定维度的累积积,如输入是一个 元向量,则结果也是一个
元向量,则结果也是一个 元向量,第
元向量,第i个输出元素值为
- input(Tensor) - 输入张量
- dim(int) - 累积乘积操作的维度
- out(Tensor, optional)
官方例子: ```pythontorch.cumprod(input, dim, out=None) -> Tensor
a = torch.randn(10) a tensor([ 0.6001, 0.2069, -0.1919, 0.9792, 0.6727, 1.0062, 0.4126,
-0.2129, -0.4206, 0.1968])
torch.cumprod(a, dim=0) tensor([ 0.6001, 0.1241, -0.0238, -0.0233, -0.0157, -0.0158, -0.0065,
0.0014, -0.0006, -0.0001])
a[5] = 0.0 torch.cumprod(a, dim=0) tensor([ 0.6001, 0.1241, -0.0238, -0.0233, -0.0157, -0.0000, -0.0000, 0.0000, -0.0000, -0.0000]) ```
torch.cumsum()
返回输入沿指定维度的累积和
torch.cumsum(input, dim, out=None) -> Tensor
官方例子:
>>> a = torch.randn(10)>>> atensor([-0.8286, -0.4890, 0.5155, 0.8443, 0.1865, -0.1752, -2.0595,0.1850, -1.1571, -0.4243])>>> torch.cumsum(a, dim=0)tensor([-0.8286, -1.3175, -0.8020, 0.0423, 0.2289, 0.0537, -2.0058,-1.8209, -2.9780, -3.4022])
torch.dist()
返回(input - other)的 范数
范数
- input(Tensor) - 输入张量
- other(Tensor) - 右侧输入张量
- p(float, optional) - 要计算的范数
- out(Tensor, optional)
官方例子:torch.dist(input, other, p=2, out=None) -> Tensor
>>> x = torch.randn(4)>>> xtensor([-1.5393, -0.8675, 0.5916, 1.6321])>>> y = torch.randn(4)>>> ytensor([ 0.0967, -1.0511, 0.6295, 0.8360])>>> torch.dist(x, y, 3.5)tensor(1.6727)>>> torch.dist(x, y, 3)tensor(1.6973)>>> torch.dist(x, y, 0)tensor(inf)>>> torch.dist(x, y, 1)tensor(2.6537)
torch.mean()
返回输入张量给定维度dim上每行的均值,输出形状与输入相同,除了给定维度上为1。
torch.mean(input, dim, out=None)
torch.median()
返回输入张量给定维度每行的中位数,同时返回一个包含中位数的索引。dim默认为输入张量的最后一维。
- input(Tensor) - 输入张量
- dim(int) - 缩减的维度
- values(Tensor, optional) - 结果张量
- indices(Tensor, optional) - 返回的索引结果张量
torch.median(input, dim=-1, values=None, indices=None) -> (Tensor, LongTensor)
torch.mode()
返回给定维度dim上,每行的众数值,同时返回一个索引张量。dim值默认为输入张量的最后一维。输出形状与输入相同,除了给定维度上为1。
torch.mode(input, dim=-1, values=None, indices=None) - > (Tensor, LongTensor)
官方例子:
>>> a = torch.randint(10, (5,))>>> atensor([6, 5, 1, 0, 2])>>> b = a + (torch.randn(50, 1) * 5).long()>>> torch.mode(b, 0)torch.return_types.mode(values=tensor([6, 5, 1, 0, 2]), indices=tensor([2, 2, 2, 2, 2]))
torch.norm()
返回输入张量给定维度dim上每行的p范数。
- input(Tensor) - 输入张量
- p(float, optional) - 范数计算中的幂指数值
torch.norm(input, p, dim, out=None) -> Tensor
torch.prod()
返回输入张量input所有元素的积
torch.prod(input) -> float
返回输入张量给定维度上的积。
torch.prod(input, dim, out=None) -> Tensor
torch.std()
返回输入张量给定维度上的标准差。如果缺省dim则返回输入张量input所有元素的标准差。
torch.std(input, dim, out=None)
torch.sum()
返回输入张量在给定维度上的和。如果缺省dim则返回输入张量input所有元素的和。
torch.sum(input, dim, out=None) -> Tensor
torch.var()
返回输入张量在给定维度上的方差。如果缺省dim则返回输入张量input所有元素的方差。
torch.var(input, dim, out=None) -> Tensor
比较操作 Comparison Ops
torch.eq()
比较元素相等性,第二个参数可为一个数,或与第一个参数同类型形状的张量。
- input(Tensor) - 待比较张量
- other(Tensor or float) - 比较张量或数
- out(Tensor, optional) - 输出张量,须为ByteTensor类型或与input同类型
torch.eq(input, other, out=None) -> Tensor
torch.equal()
若两个张量有相同的形状和元素值,则返回True, 否则False。
torch.equal(tensor1, tensor2) -> bool
torch.ge()
逐元素比较input和other,即是否input >= other。第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
- input(Tensor) - 待对比的张量
- other(Tensor or float) - 对比的张量或float值
- out(Tensor, optional) - 输出张量,必须为ByteTensor或与第一个参数相同类型。
torch.ge(input, other, out=None) -> Tensor:
torch.gt()
逐元素比较input和other,是否input > other。若两个张量有相同的形状和元素值,则返回True,否则False。第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
torch.gt(input, other, out=None) -> Tensor
torch.kthvalue()
取输入张量input指定维度上第k个最小值,若不指定dim,则默认为input的最后一维。返回一个元组,其中indices是原始输入张量input中沿dim维的第k个最小值下标。
- input(Tensor) - 输入张量
- k(int) - 第k个最小值
- dim(int, optional) - 沿着此维度进行排序
- out(tuple, optional) - 输出元组
torch.kthvalue(input, k, dim=None, out=None) -> (Tensor, LongTensor)
torch.le()
逐元素比较input和other,即是否input <= other,第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
torch.le(input, other, out=None) -> Tensor
torch.lt()
逐元素比较input和other,即是否input < other。
torch.lt(input, other, out=None) -> Tensor
torch.max()
返回输入张量给定维度上每行的最大值,并同时返回每个最大值的位置索引。
- input(Tensor) - 输入张量
- dim(int) - 指定的维度
- max(Tensor, optional) - 结果张量,包含给定维度上的最大值
- max_indices(LongTensor, optional) - 包含给定维度上每个最大值的位置索引。
torch.max(input, dim, max=None, max_indice=None) -> (Tensor, LongTensor)
torch.min()
返回输入张量给定维度上每行的最小值,并同时返回每个最小值的位置索引。
torch.min(input, dim, min=None, min_indices=None) -> (Tensor, LongTensor)
torch.ne()
逐元素比较input和other, 即是否input != other。第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
返回值:一个torch.ByteTensor张量,包含了每个位置的比较结果(如果tensor != other 为True,返回1)。
torch.ne(input, other, out=Tensor) -> Tensor
torch.sort()
对输入张量input沿着指定维度按升序排序,如果不给定dim,默认为输入的最后一维。如果指定参数descending为True,则按降序排序。
返回两项:重排后的张量,和重排后元素在原张量的索引。
- input(Tensor) - 输入张量
- dim(int, optional) - 沿此维排序,默认为最后一维
- descending(bool, optional) - 布尔值,默认升序
torch.sort(input, dim=None, descending=False, out=None) -> (Tensor, LongTensor)
torch.topk()
沿给定dim维度返回输入张量input中k个最大值,不指定dim,则默认为最后一维,如果largest为False,则返回最小的k个值。
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor)
其它操作 Other Operations
torch.cross()
返回沿着维度dim上,两个张量input和other的叉积。input和other必须有相同的形状,且指定的dim维上size必须为3。如果不指定dim,则默认为第一个尺度为3的维。
torch.cross(input, other, dim=-1, out=None) -> Tensor
官方例子:
>>> a = torch.randn(4, 3)>>> atensor([[-0.3956, 1.1455, 1.6895],[-0.5849, 1.3672, 0.3599],[-1.1626, 0.7180, -0.0521],[-0.1339, 0.9902, -2.0225]])>>> b = torch.randn(4, 3)>>> btensor([[-0.0257, -1.4725, -1.2251],[-1.1479, -0.7005, -1.9757],[-1.3904, 0.3726, -1.1836],[-0.9688, -0.7153, 0.2159]])>>> torch.cross(a, b, dim=1)tensor([[ 1.0844, -0.5281, 0.6120],[-2.4490, -1.5687, 1.9792],[-0.8304, -1.3037, 0.5650],[-1.2329, 1.9883, 1.0551]])>>> torch.cross(a, b)tensor([[ 1.0844, -0.5281, 0.6120],[-2.4490, -1.5687, 1.9792],[-0.8304, -1.3037, 0.5650],[-1.2329, 1.9883, 1.0551]])
torch.diag()
如果输入是一个向量,则返回一个以input为对角线元素的2D方阵。如果输入是一个矩阵,则返回一个包含input为对角元素的1D张量。
参数diagonal指定对角线:
- diagonal = 0,主对角线
- diagonal > 0,主对角线之上
- diagonal < 0,主对角线之下
torch.diag(input, diagonal=0, out=None) -> Tensor
torch.histc()
计算输入张量的直方图。如果min和max都为0,则利用数据中的最大最小值作为边界。
torch.histc(input, bins=100, min=0, max=0, out=None) -> Tensor
返回的直⽅图是基于整个输⼊的Tensor来说的,min和max如果默认都为0,则为Tensor的最⼩值和最⼤值。返回的直⽅图没有归⼀化,每个bin的值统计的是个数。
但是torch.histc()⽆法针对某⼀维度进⾏直⽅图计算。
官方例子:
>>> torch.histc(torch.tensor([1., 2, 1]), bins=4, min=0, max=3)tensor([ 0., 2., 1., 0.])
torch.renorm()
返回一个张量,包含规范化后的各个子张量,使得沿着dim维划分的各子张量的p范数小于maxnorm。如果p范数的值小于maxnorm,则当前子张量不需要修改。
torch.renorm(input, p, dim, maxnorm, out=None) -> Tensor
例子:
>>> x = torch.ones(3, 3)>>> x[1].fill_(2)tensor([ 2., 2., 2.])>>> x[2].fill_(3)tensor([ 3., 3., 3.])>>> xtensor([[ 1., 1., 1.],[ 2., 2., 2.],[ 3., 3., 3.]])>>> torch.renorm(x, 1, 0, 5)tensor([[ 1.0000, 1.0000, 1.0000],[ 1.6667, 1.6667, 1.6667],[ 1.6667, 1.6667, 1.6667]])
解释:
- 第一行的
 范数是3,不大于5,不处理。
范数是3,不大于5,不处理。 - 第二行的
 范数是6,大于5,每个元素要除以6,再乘以 5。
范数是6,大于5,每个元素要除以6,再乘以 5。 - 第三行的
 范数是9,大于5,每个元素要除以9,再乘以 5。
范数是9,大于5,每个元素要除以9,再乘以 5。
torch.trace()
返回输入2维矩阵对角元素的和(迹)
torch.trace(input) -> float
torch.tril()
返回一个张量,包含输入张量(2D张量)的下三角部分,其余部分设为0,参数diagonal控制对角线。
torch.tril(input, diagonal=0, out=None) -> Tensor
torch.triu()
返回一个张量,包含输入矩阵的上三角部分,其余被置为0。
torch.triu(input, diagonal=0, out=None) -> Tensor
BLAS and LAPACK Operations
torch.dot()
计算两个张量的点乘,两个张量都为1-D向量
torch.dot(tensor1, tensor2) -> float
torch.eig()
计算方阵a的特征值和特征向量。
- a(Tensor) - 方阵
- eigenvectors(bool) - 如果为True,同时计算特征值和特征微量,否则只计算特征值
返回值: - e(Tensor) - a的右特征向量
- v(Tensor) - 如果eigenvectors为True,则为包含特征向量的张量,否则为空。
torch.eig(a, eigenvectors=False, out=None) -> (Tensor, Tensor)
torch.inverse()
对方阵input求逆
torch.inverse(input, out=None) -> Tensor
torch.mm()
对矩阵mat1和mat2进行相乘。
torch.mm(mat1, mat2, out=None) -> Tensor
torch.mv()
对矩阵mat和向量vec进行相乘。
torch.mv(mat, vec, out=None) -> Tensor
Other
tensor.any()
如果tensor中存在一个元素为True,那么返回True;只有所有元素都是False时才返回False。
>>> a = torch.tensor([True,True,False])>>> print(a.any())tensor(True)>>> b = torch.tensor([False, False, False])>>> print(b.any())tensor(False)
tensor.all()
如果tensor中所有元素都是True, 才返回True; 否则返回False。
>>> a = torch.tensor([True,True,False])>>> print(a.all())tensor(False)>>> b = torch.tensor([True,True,True])>>> print(b.all())tensor(True)
参考链接

若有收获,就点个赞吧
0 人点赞
