信息熵
信息熵常见定义为表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。公式为 ,当随机变量分布为均匀分布时,信息熵最大。
,当随机变量分布为均匀分布时,信息熵最大。
应用在数据传输或者数据压缩等方面可理解为怎么使用更短的编码来描述高概率的事件,使用更长的编码来描述低概率的事件,即用最小的带宽传输或者最小的空间来存储,假设用 来表示一天的天气情况,那么用计算机来存储每天的天气,可以使用一个公式来计算记录n天数据需要的存储空间:
来表示一天的天气情况,那么用计算机来存储每天的天气,可以使用一个公式来计算记录n天数据需要的存储空间: (1-1)
(1-1)
表示第x个事件发生的概率;
表示存储空间的存储因子
要满足 越大的时候编码越短,常见的有反比例函数  ,这里有个除法,对数操作可将其转换成减法,同时能让模型更符合正态分布,比如那些随着模型自变量的增加,因变量的方差也增大的模型取对数后会更加平稳,所以得到
,这里有个除法,对数操作可将其转换成减法,同时能让模型更符合正态分布,比如那些随着模型自变量的增加,因变量的方差也增大的模型取对数后会更加平稳,所以得到
 (1-2)
(1-2)
a做为底数一般取 2,10,e
将(1-2) 代入(1-1)得到公式:
从而可以这么理解,以最小的代价(比如存储空间或者编码)消除系统的不确定性,而这个代价的大小就是信息熵
交叉熵
现有两个概率分布 p(x) 和 q(x),其中 p(x) 为真实分布, q(x)非真实分布。如果使用非真实分布 q(x) 来表示来自真实分布 p(x) 的平均编码长度得到
非真实分布 q(x) 得到的平均码长大于根据真实分布 p(x) 得到的平均码长,这多出的部分就是相对熵
相对熵
相对熵可以用来衡量两个概率分布之间的差异,记为  ,也称之为KL散度
,也称之为KL散度
若p(x)是数据的真实概率分布,q(x)是由数据计算得到的概率分布。 由于真实的概率分布是固定的,相对熵公式的后半部分H(p)就是个常数 。那么相对熵达到最小值的时候,也意味着交叉熵达到了最小值。对q(x)的优化就等效于求交叉熵的最小值。最小化相对熵 DKL(p||q) 等价于最小化交叉熵 H(p,q) 也等价于最大化似然估计(具体参考Deep Learning 5.5 Maximum Likelihood Estimation)。在机器学习中,我们希望训练数据上模型学到的分布 P(model) 和真实数据的分布 P(real) 越接近越好,所以我们可以使其相对熵最小。但是我们没有真实数据的分布,所以只能希望模型学到的分布 P(model) 和训练数据的分布 P(train) 尽量相同。假设训练数据是从总体中独立同分布采样的,那么我们可以通过最小化训练数据的经验误差来降低模型的泛化误差。即:
- 希望学到的模型的分布和真实分布一致,P(model)≃P(real)
- 但是真实分布不可知,假设训练数据是从真实数据中独立同分布采样的P(train)≃P(real)
- 因此,我们希望学到的模型分布至少和训练数据的分布一致,P(train)≃P(model)
条件熵
若(X,Y)~p(x,y)条件熵 H(Y|X)表示在已知随机变量 X 的条件下随机变量 Y 的不确定性。条件熵 H(Y|X)定义为 X 给定条件下 Y 的条件概率分布的熵对 X 的数学期望:
条件熵 H(Y|X)相当于联合熵 H(X,Y)减去单独的熵 H(X),即H(Y|X)=H(X,Y)−H(X),证明如下:
当已知 H(X) 这个信息量的时候,H(X,Y) 剩下的信息量就是条件熵:H(Y|X)=H(X,Y)−H(X)
互信息
两个随机变量X和Y,它们的联合概率密度函数为p(x,y),其边际概率密度函数分别是p(x)和p(y)。互信息为联合分布p(x,y)和乘积分布p(x)p(y)之间的相对熵
互信息也可以看作是一个随机变量包含另外一个随机变量的信息量,或者说如果已知一个变量,另外一个变量减少的信息量
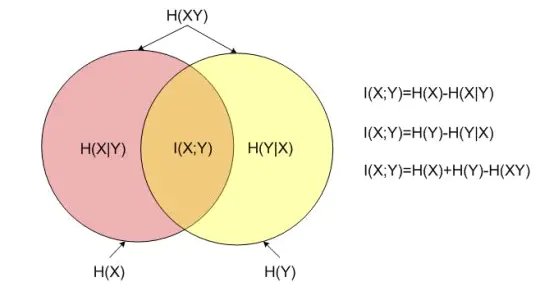
信息熵、联合熵、条件熵、互信息的关系:

若有收获,就点个赞吧
0 人点赞
