ResNext
与 ResNet 相比,相同的参数个数,结果更好:一个 101 层的 ResNeXt 网络,和 200 层的 ResNet 准确度差不多,但是计算量只有后者的一半
洞见: split-transform-merge
如下图,左边是ResNet的基本结构,右边是ResNeXt的基本结构: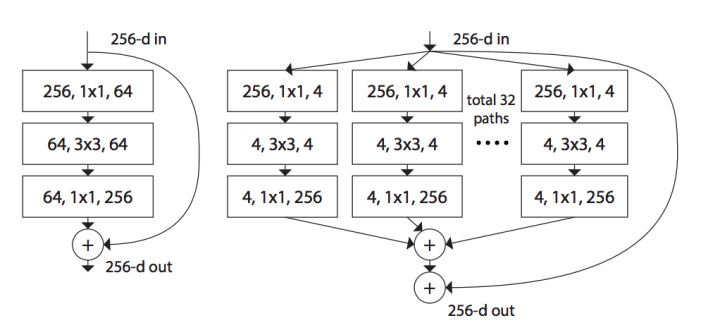
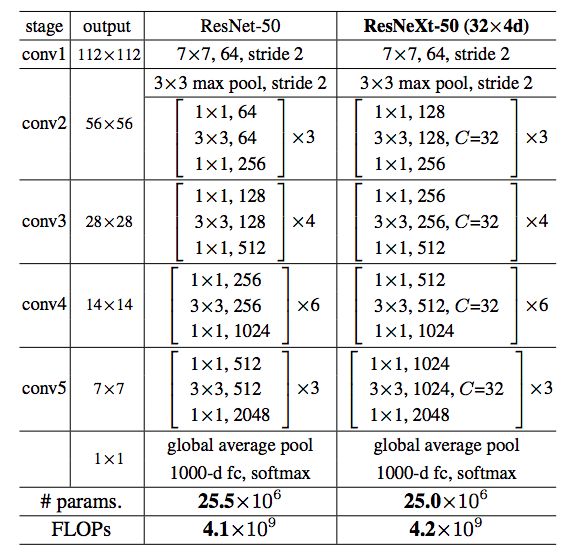
下面是ResNeXt-50(32x4d)的配置清单,32指进入网络的第一个ResNeXt基本结构的分组数量C(即基数)为32,4d表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128):
SE-ResNet
ResNet-50和SE-ResNet-50各方面相当,但是准确率却和ResNet-101相当
洞见: 在于通过网络根据loss去学习特征通道权重,使得有效的通道权重大,无效或效果小的通道权重小的方式训练模型达到更好的结果
如下,就是SENet的基本结构:
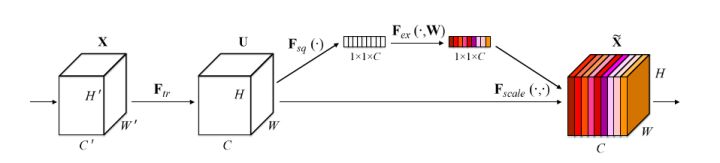
原来的任意变换,将输入X变为输出U,现在,假设输出的U不是最优的,每个通道的重要程度不同,有的通道更有用,有的通道则不太有用。
对于每一输出通道,先global average pool,每个通道得到1个标量,C个通道得到C个数,然后经过FC-ReLU-FC-Sigmoid得到C个0到1之间的标量,作为通道的权重,然后原来的输出通道每个通道用对应的权重进行加权(对应通道的每个元素与权重分别相乘),得到新的加权后的特征,作者称之为feature recalibration。
第一步每个通道HxW个数全局平均池化得到一个标量,称之为Squeeze,然后两个FC得到01之间的一个权重值,对原始的每个HxW的每个元素乘以对应通道的权重,得到新的feature map,称之为Excitation。任意的原始网络结构,都可以通过这个Squeeze-Excitation的方式进行feature recalibration,采用了改方式的网络,即SENet版本。
下面是SENet和ResNet的结合:
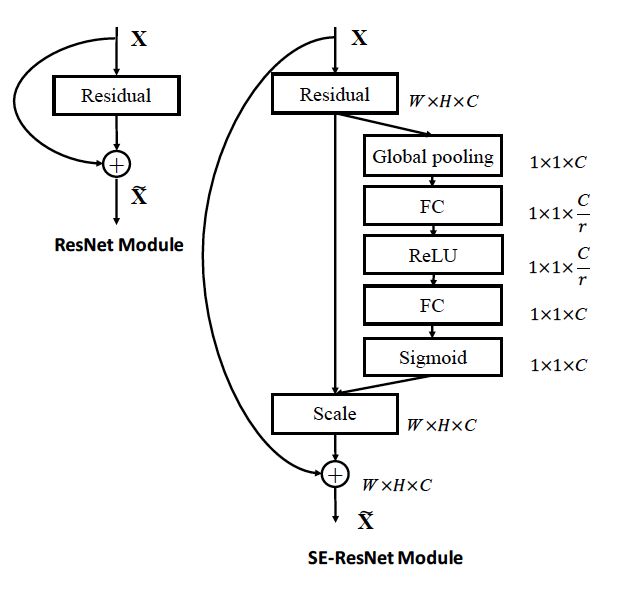
具体实现上就是一个Global Average Pooling-FC-ReLU-FC-Sigmoid,第一层的FC会把通道降下来,然后第二层FC再把通道升上去,得到和通道数相同的C个权重,每个权重用于给对应的一个通道进行加权。上图中的r就是缩减系数,实验确定选取16,可以得到较好的性能并且计算量相对较小。
SE-ResNext
ResNext通过Squeeze-Excitation的方式进行feature recalibration 就是SE-ResNext网络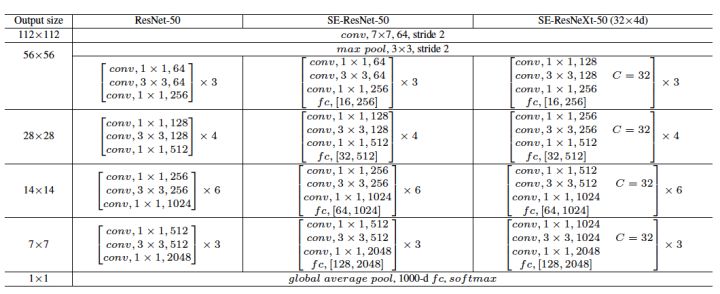

若有收获,就点个赞吧
0 人点赞
