1、基于数据主键自增简单版本
实现描述
专门搞一个库,搞一个表,专门用于生成全局唯一id,insert into插入一条数据,他会返回给你一个全局唯一id,然后你把这个id设置给数据,插入分表后的1024张表里去,全局唯一的
优点
专门搞一个库,搞一个表,专门用于生成全局唯一id,insert into插入一条数据,他会返回给你一个全局唯一id,然后你把这个id设置给数据,插入分表后的1024张表里去,全局唯一的
缺点
单库单表,并发抗不住,一旦达到每秒几千的高并发;不停的在表里插入数据获取id,表数据会越来越多,还得定期清理,很麻烦
适用场景
分库分表是因为数据量大,但是低并发低负载,而且数据库单机有高可用问题,必须上高可用方案,另外是单表数据一直增长也是个问题,一般不会直接投入生产,投入生产环境的时候会用下面说的flickr的数据库唯一id生成方案
2、flickr(雅虎旗下的图片分享平台)公司的方案主键自增变种方案
实现描述
CREATE TABLE `uid_sequence` (`id` bigint(20) unsigned NOT NULL auto_increment,`stub` char(1) NOT NULL default '',PRIMARY KEY (`id`),UNIQUE KEY `stub` (`stub`)) ENGINE=MyISAM;REPLACE INTO uid_sequence (stub) VALUES ('test');SELECT LAST_INSERT_ID();
优点
replace into语法替代insert into,避免表行数过大,一张表就一行数据,然后再select获取这个表的最新id,last_insert_id()函数是connection级别的,就你这个连接的最近insert生成的id,多个客户端之间没影响
当然,其实也可以优化成这样,就是每次你一台机器要申请一个唯一id,你就REPLACE INTO uid_sequence (stub) VALUES (‘192.168.31.226’),用你自己机器的ip地址去replace into,那么就你自己机器会有id不停自增,完了用select id from table where stub=机器地址,就可以了
最多如果你要考虑到多线程并发问题,那么就在机器地址后加入线程编号,这样一台机器的不同线程,都是对自己的id在自增
缺点
这个方案本质跟第一个方案没区别,唯一优化就是用replace into替代了insert into,避免表数据量过大,缺点也在于数据库并发能力不高,所以适用场景,就是分库分表的时候,低并发,用这个方案生成唯一id,低并发场景下可以用于生产
而且一般会部署数据库高可用方案,两个库设置不同的起始位置和步长,分别是1、3、5,以及2、4、6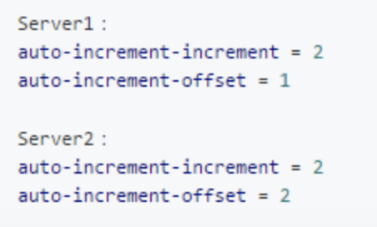
3、基于flickr方案的高并发优化
实现描述
有一种变种方案,是基于flickr方案的高并发优化,他核心问题在于每一次生成id都得找数据库,所以这就是并发瓶颈,所以这里可以把数据库优化为号段,而不是id号,什么意思呢?一起来看看
每台机器都引入一个自己封装的客户端,只要一旦服务启动,就直接采用flickr方案获取一个id,但是他仅仅代表的是一个号段,什么意思呢?比如说,一个服务启动,通过flickr方案的replace into拿到一个id,假设是1吧
此时你的号段可以配置为一个号段是10000个id号,那么此时你这个号段的起始id就是1 10000,然后可以把起始id设置到AtomicLong里去,还可以保存一下号段的最大id,也就是(n + 1) 10000,就是2 * 10000,20000
所以这个号段的id就是[10000, 20000,20000是不包含在内的
接着服务里如果要获取唯一id,直接找你封装的客户端,每次拿一个id,就是AtomicLong.incrementAndGet(),直接原子递增,这样你大部分的id获取,都是在内存里通过号段内递增实现的
优点
如果拿到了号段里最大id,此时对获取id的请求得阻塞住,只要拿到的id大于等于了最大id,请求全部自己陷入阻塞,比如大家都去while循环阻塞,过一会儿再次获取id,跟最大id比较
发号器客户端的线程,定时轮询,一旦发现这个问题,此时就重新利用flickr方案获取一个号段,再次设置AtomicLong里的初始id以及更新最大id,在这个过程中别的任何一个线程来获取id都会发现AtomicLong自增值比最大id是大的
即使是发号器客户端线程,刚刚设置了AtomicLong的值,然后还没设置volatile的最大id值,此时别的线程在while循环过程中获取了id,AotmicLong自增值一定大于之前的最大id值,也会继续陷入阻塞的
只有 当发号器客户端线程更新了volatile最大id值之后,其他线程才会在while循环之后,发现AtomicLong自增值是小于最大id值的,此时就可以继续工作了,这种情况通常是很少的,所以大部分情况下,各个服务都是基于本地的号段在内存里获取id,而且全局上还是唯一的,没有高并发问题,数据库的并发也是很低的
缺点
这个方案的唯一缺点就是,每次重启服务,就会浪费一个号段里还没自增到的大量id,重启后又是新的号段了,但是如果要优化,可以在spring销毁事件里,发号器内部设置一个volatile标识,不允许获取id了,接着 把AtomicLong的值持久化到本地磁盘,下次服务重启后直接从本地磁盘里读取,就不会浪费了
其实这个优化以后的方案,就可以投入生产了,确实也有个别大厂是这么做的,也运行的很好。如果一定要说这个方案有什么弊端,那就是,归根结底,还是有一个数据库这么个外部依赖,其实如果方案真做好了,你还得考虑数据库的高可用方案这些东西,就是牵扯到了外部依赖,就容易做的很重
另外一个问题,就是对于这个方案,你还得去做步长的配置,那么到底允许多长的步长呢?是否允许用户自己配置呢?如果不允许,你固定一个步长,那个步长会不会在一些特殊高并发场景下,比如你1000作为步长,1000个号瞬间被秒光,一个服务每秒都得请求一次数据库获取新的号段,此时你有上千个服务实例,数据库不还是抗不住?
所以,这个方案适合一些没有特殊超高并发的场景,而且扩展性和灵活性不是很强,总是让人担心他的号段步长会出一些问题,但是在一些普通场景下,其实一般可能也没什么问题,所以有普通高并发场景的生产环境,还是可用的
基于数据库的方案就是flickr方案以及flickr高并发优化方案,但是没有snowflake生产级方案那么具备普适性,snowflake方案不涉及什么号段问题,也不会额外依赖数据库,不需要考虑数据库高可用之类的,他自己就是peer-to-peer的一个集群架构,随时可以扩容
时间戳+业务id,相当好用,推荐第一选择是他,能用时间戳+业务id的,就别搞分布式id生成,如果不行的,再考虑flickr方案或者snowflake方案
4、基于flickr方案的一种实现-来自美团开源Leaf
github:https://github.com/Meituan-Dianping/Leaf
博文链接:https://tech.meituan.com/2019/03/07/open-source-project-leaf.html
值得一说-Leaf双Buffer优化
1、问题
- 在更新DB的时候会出现耗时尖刺,系统最大耗时取决于更新DB号段的时间。
- 当更新DB号段的时候,如果DB宕机或者发生主从切换,会导致一段时间的服务不可用。
2、优化方案
为了解决这两个问题,Leaf采用了异步更新的策略,同时通过双Buffer的方式,保证无论何时DB出现问题,都能有一个Buffer的号段可以正常对外提供服务,只要DB在一个Buffer的下发的周期内恢复,就不会影响整个Leaf的可用性。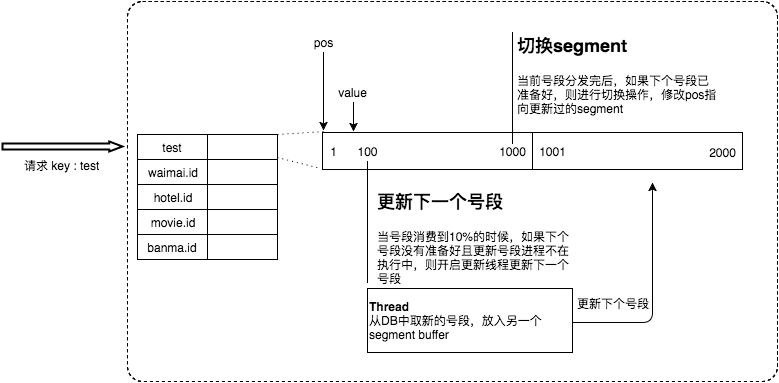
这个版本代码在线上稳定运行了半年左右,Leaf又遇到了新的问题:
- 号段长度始终是固定的,假如Leaf本来能在DB不可用的情况下,维持10分钟正常工作,那么如果流量增加10倍就只能维持1分钟正常工作了。
- 号段长度设置的过长,导致缓存中的号段迟迟消耗不完,进而导致更新DB的新号段与前一次下发的号段ID跨度过大。
Leaf动态调整Step
假设服务QPS为Q,号段长度为L,号段更新周期为T,那么Q * T = L。最开始L长度是固定的,导致随着Q的增长,T会越来越小。但是Leaf本质的需求是希望T是固定的。那么如果L可以和Q正相关的话,T就可以趋近一个定值了。所以Leaf每次更新号段的时候,根据上一次更新号段的周期T和号段长度step,来决定下一次的号段长度nextStep:
- T < 15min,nextStep = step * 2
- 15min < T < 30min,nextStep = step
- T > 30min,nextStep = step / 2
至此,满足了号段消耗稳定趋于某个时间区间的需求。当然,面对瞬时流量几十、几百倍的暴增,该种方案仍不能满足可以容忍数据库在一段时间不可用、系统仍能稳定运行的需求。因为本质上来讲,Leaf虽然在DB层做了些容错方案,但是号段方式的ID下发,最终还是需要强依赖DB。
MySQL高可用
在MySQL这一层,Leaf目前采取了半同步的方式同步数据,通过公司DB中间件Zebra加MHA做的主从切换。未来追求完全的强一致,会考虑切换到MySQL Group Replication。
现阶段由于公司数据库强一致的特性还在演进中,Leaf采用了一个临时方案来保证机房断网场景下的数据一致性:
- 多机房部署数据库,每个机房一个实例,保证都是跨机房同步数据。
- 半同步超时时间设置到无限大,防止半同步方式退化为异步复制。

若有收获,就点个赞吧
0 人点赞
