浏览器中的网络
HTTP/0.9 完整请求流程
- 客户端根据 IP 地址、端口、服务器建立 TCP 连接(三次握手)
- 发送一个请求行信息来获取内容,如:GET /index.html
- 服务器接收到信息,读取对应的 index.html, 将数据以 ASCLL 字符流返回给客户端
- 传输完成后,断开连接
三个特点
- 只有请求行,无请求头和请求体
- 服务器只返回数据,没有返回头之类的信息
- 返回内容是以 ASCLL 字符流形式返回
HTTP/1.0
此时浏览器不仅支持 HTML,还支持 JS、CSS、图片、音频等不同类型文件。
- 如何实现多类型文件的下载?
要想下载这些不同类型的文件,就需要告诉服务器需要文件的类型、编码等信息。于是 HTTP/1.0 就加入了请求头和响应头。发送请求时,带上请求头信息,返回数据时,会先返回响应头信息。 - HTTP/1.0 请求头各个字段的来源
accept: text/html: 浏览器需要知道服务器返回什么类型的数据,然后才能针对不同类型的数据做处理。此处表示期望服务器返回 html 类型的文件。
accept-encoding: gzip,deflate,br: 由于万维网支持的数据越来越广,单个文件的数据量也变得越来越大。为了减轻传输性能,服务器汇兑数据压缩后再传输,所以浏览器需要知道服务器的压缩方法以便解密用。此处表示浏览器期望服务器可以采用 gzip、deflate、br 这几种压缩方法。
accept-charest: ISO-8859-1,UTF-8: 各种不同类型的文件所用的编码方式都不太一样,为了准确读取文件,浏览器也需要知道文件的编码类型。此处表示期望返回的文件编码为 UTF-8 或 ISO-8859-1。
accept-language: zh-CN,zh: 提供国际化支持,对不同地区提供不同的语言版本 。此处表示期望优先返回的语言是中文。 - HTTP/1.0 响应头的数据信息
conte nt-encoding: br:告诉浏览器,服务器采用了 br 的压缩方法
content-type: text/html; charset=UTF-8:告诉浏览器,服务器返回的是 html 文件并且采用 UTF-8 编码。 - 状态码
有的请求服务器可能无法处理或者处理出错,这时就要告诉浏览器最终处理该请求的情况,就引入了状态码,通过响应行的方式来通知浏览器。 - Cache 机制
为了减轻服务器的压力,用来缓存已经下载过的数据。 - user-agent
服务器需要统计客户端的基础信息,比如:windows、mac、android 的用户数量分别是多少。
HTTP1.1 改进的功能
1. 改进持久连接
随着浏览器普及,单个页面中的资源文件越来越多,如果每个文件的下载都要建立 TCP 连接、传输数据、断开连接的步骤,会增加大量不必要的开销。
为了解决上述问题,HTTP1.1 增加了持久连接,在一个 TCP 连接上可传输多个 HTTP 请求,只要浏览器和服务器没有明确断开连接,这个 TCP 连接会一直保持。
持久连接在 HTTP1.1 中是默认开启的。若不想采用,可以在请求头中加上Connection: close
2. 不成熟的 HTTP 管线化
持久连接虽然能减少 TCP 的建立和断开次数,但需要等待前面每次请求返回之后,才能进行下一次请求。如果某个请求没有及时返回,那么会阻塞后面的所有请求,这就是队头阻塞问题。
HTTP1.1 试图通过管线化,将多个 HTTP 请求批量提交给服务器,不过服务器依然要根据请求顺序来回复浏览器的请求。
3. Host 字段:提供虚拟主机的支持
HTTP1.0 中,每个域名只能绑定一个 IP 地址,即一个服务器只能支持一个域名。随着虚拟主机技术的发展,一个物理主机上可以绑定多个虚拟主机,每个虚拟主机都有自己单独的域名,这些域名公用同一个 IP 地址。
因此,HTTP1.1 的请求头中增加 Host 字段,用来表示当前的域名地址,这样服务器就可以根据不同 Host 做不同处理。
4. 对动态内容提供了完美支持
HTTP1.0 需要通过响应头 content-length 告诉浏览器数据的大小,这样浏览器就可以根据设置的数据大小来接收数据(浏览器对大文件不能一次性接受,所以要根据数据大小来判断是否接受完毕)。
但现在服务端返回的都是动态生成的内容,因此在传输数据之前并不知道最终数据的大小,进而导致浏览器不知道何时会接受完所有数据。
HTTP1.1 引入 Chunk transfer 机制,在服务器端将数据分割成若干个任意大小的数据块,在发送时附上数据块的长度,最后使用 0 长度的数据块表示发送完毕,这样就支持动态内容。
5. 客户端的 Cookie、安全机制
Cookie 机制:服务器发送的响应中若有 set-cookie 字段,浏览器就会将字段内容保存到本地,下次再请求时就会把 cookie 带上。可用来存储用户的登录信息。
安全机制:……
HTTP1.1 核心优化方式
- 增加持久连接
- 每个域名可同时维护 6 个 TCP 持久连接
- 使用 CDN 来实现域名分片机制
通过这些方式大大提高了页面的下载速度。
如果使用单个 TCP 持久连接,下载 100 个资源用时:100×n×RTT(Round-Trip TIme 往返时延)。
通过上面技术用时为:100×n×RTT/(6×CDN)

HTTP1.1 主要缺陷
对带宽的利用率不理想。
带宽:每秒最大能发送或者接收的字节数。
上行带宽:每秒能发送的最大字节数。
下行带宽:每秒能接受的最大字节数。
100M 带宽,实际下载速度能达到 12.5M/s。
下载速度的 M 单位是”字节“。
带宽的 M 是 单位是”位“。
1 字节 = 8 位
加载页面很难将 12.5M 全部用满,主要有下面 3 个原因。
- TCP 慢启动
一个 TCP 建立连接之后,就进入发送数据状态。刚开始 TCP 协议会采用一个非常慢的速度去发送数据,然后慢慢加快速度
之所以慢启动会带来性能问题,是因为页面中关键资源 html,css,js 加载的时间可能比慢启动耗费的时间还少,这样就推迟了首屏渲染时间了。
慢启动是 TCP 为减少网络拥赛的策略,没有办法改变。 - 同时开启多条 TCP 连接,这些连接会竞争固定的带宽。
同时建立多条 TCP 连接,当带宽不足时,这些 TCP 连接会减慢发送或者接收的速度。
比如:一个页面 200 个资源,用了 3 个 CDN,即 18 个 TCP 连接来下载资源。当带宽不足时,各个 TCP 连接就需要动态减慢接收数据的速度。
有的 TCP 连接下载的是关键资源(html,css,js等),有的下载的则是普通资源(图片、视频),多条 TCP 之间不能协商让关键资源优先下载,这样就会影响关键资源的下载速度。 - HTTP1.1 队头阻塞问题。
使用持久连接时,多个请求共用一个 TCP 连接,当一个请求被阻塞了 5s,后面排队的请求都要延迟等待 5s,这个过程中带宽,CPU 都被白白浪费了。
浏览器生成页面过程中,提前接受到数据就可以做预处理操作。比如:提前接收到图片就可以开始编码操作,等到用时便可直接给出处理后的数据,让用户感到整体速度提升。
队头阻塞使得这些数据不能并行请求,不利于浏览器优化。
HTTP/2
虽然 TCP 有问题,但不能换掉 TCP,就要想办法规避 TCP 的慢启动和连接之间的竞争问题。
基于此,HTTP/2 思路就是一个域名只使用一个 TCP 长连接来传输数据,这样只要一次慢启动,也避免了竞争问题。
对于队头阻塞问题,HTTP/2 需要实现资源的并行请求,任何时候都可以将请求发给服务器,并不需要等待其他请求的完成,服务器也可以随时返回处理好的请求给浏览器。
HTTP/2 的解决方案可总结为:一个域名只使用一个 TCP 长连接和消除队头阻塞问题。
HTTP/2 多路复用

从上图中可以发现,每个请求都有一个对应的 ID,streamX。服务器收到这些请求后,会优先返回已缓存好的内容。比如:index.html,bar.js 的响应头信息已缓存好,就会立即返回给浏览器。然后再把 index.html,bar.js 的响应体数据返回给浏览器。浏览器接收到之后,会筛选出相同 ID 的内容,将其拼接为完整的 HTTP 响应数据
HTTP/2 多路复用技术,可以将请求分成一帧一帧的数据去传输,当收到一个优先级高的请求时(例如:关键资源),服务器可以暂停之前的请求来优先处理关键资源的请求。
HTTP/2 多路复用的实现
下图为 HTTP/2 协议栈,通过引入二进制分帧层,实现了 HTTP 的多路复用技术。
HTTP/2 的语义和 HTTP/1.1 依然是一样的,变得只是传输方式,这意味这我们不需要为 HTTP/2 去重建生态,故容易推广。
HTTP/2 请求和接收的过程:
- 首先,浏览器准备好请求数据,包括请求行、请求头等信息,如果是 POST 方法,还有请求体。
- 这些数据经过二进制分帧层处理后,会被转换为一个个带有请求 ID 编号的帧,通过协议栈将这些帧发送给服务器。
- 服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息。
- 服务器处理该条请求,并将处理好的响应行、响应头、响应体分别发送至二进制分帧层。
- 二进制分帧层将这些响应数据转换为一个个带有请求 ID 编号的帧,经过协议栈发送给浏览器。
- 浏览器接到响应帧后,根据 ID 编号将帧的数据提交给对应的请求。
HTTP/2 其他特性
- 可以设置请求的优先级。
在发送请求时,标上该请求的优先级,当服务器接收到请求之后,会优先处理优先级高的请求。 - 服务器推送。
HTTP/2 可直接将数据提前推送到浏览器。
例:当用户请求一个 HTML 页面之后,服务器知道该 HTML 页面会引用哪些 JS 和 CSS 文件,在接到 HTML 请求后,附带着将引用到的文件一并发送给浏览器。这样当浏览器解析完 HTML 文件后,便可直接拿到所需要的 JS 和 CSS 文件,可大大提高页面首次打开速度。 - 头部压缩。
HTTP/1.X 与 HTTP/2 都有请求头和响应头,通常情况下页面至少有 100 个以上的资源,如果将这些请求头数据压缩为原来的 20%,也能大幅提升传输效率。
TCP 队头阻塞如何影响到 HTTP/2 的性能?
在tcp层 Tls层以上的数据都是tcp层的数据,tcp层对每个数据包都有编号,分为1,2,3 …. tcp保证双向稳定可靠的传输,如果2包数据丢失,1号包和3号包来了,那么在超时重传时间还没有收到2编号数据包,服务端会发送2号数据包,客服端收到之后,发出确认,服务端才会继续发送其他数据,客服端数据才会呈现给上层应用层,这样tcp层的阻塞就发生了。
HTTP/2 主要缺陷
- TCP 的队头阻塞
- 正常情况下 TCP 传输数据过程

上图为正常情况下 TCP 传输数据过程,从一端到另一端的数据会被拆分为一个个按照顺序排列的数据包,这些数据包通过网络传输到接收端,接收端再按顺序将这些数据包组装成原始数据。 - TCP 丢包时的传输数据过程
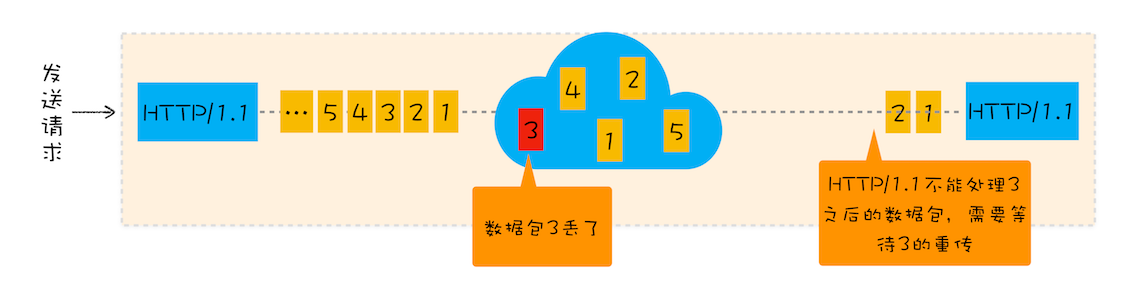
上图为 TCP 丢包时的传输数据过程,有一个数据包因为网络故障或其他原因丢包了,那个整个 TCP 连接就会处于暂停状态,等待丢失的数据包被重新传输过来。
我们就把在 TCP 传输过程中,由于单个数据包的丢失而造成的阻塞称为 TCP 上的队头阻塞。
- HTTP/2 多路复用

由上图可以看出,多个请求是跑在一个 TCP 管道中的,如果任一路数据流出现了丢包,会阻塞 TCP 连接中的所有请求。而再 HTTP/1.1 中,如果 1 个 TCP 连接发生队头阻塞,其他 5 个连接依然可以继续传输数据。
随着丢包率增加,HTTP/2 的传输效率也会越来越差。有测试数据表明,当丢包率 >= 2% 时,HTTP/1.1 传输效率更快。
- TCP 建立连接的时延
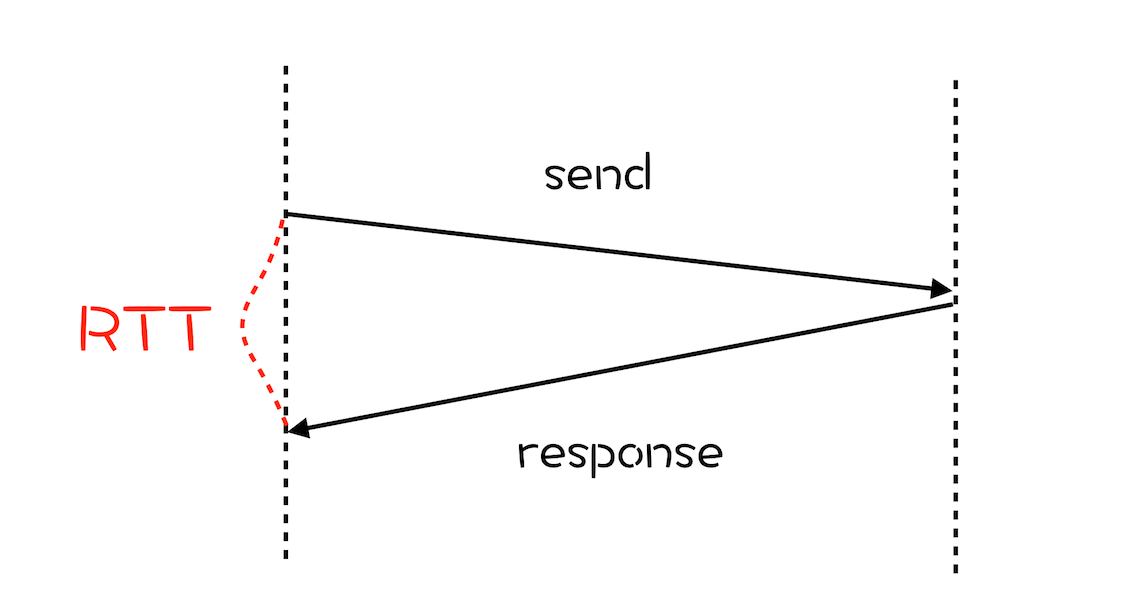
使用 HTTP/1 和 HTTP/2 都是使用 TCP 协议传输,如果使用 HTTPS,则还需要使用 TLS 协议进行安全传输。
建立 TCP 连接,三次握手耗费 1.5个RTT
进行 TLS 连接,TLS 两个版本(1.2,1.3) 大约耗费 1~2个RTT。
由上可得,在传输数据前,就要花费 3~4 个 RTT。若浏览器和服务器距离近,一个 RTT 可能在 10ms 内。远的话可能 100ms,这种情况下整个握手过程就需要 300~400ms,用户就会感觉到慢。 - TCP 协议僵化
改进 TCP 协议来解决上述问题非常困难。原因如下:
中间设备僵化,中间设备包括路由器、防火墙、NAT、交换机等,他们依赖一些很少升级的软件,这些软件大量使用 TCP 特性,设置之后很少更新。如果我们在客户端升级 TCP 协议,新协议的数据包经过这些中间设备时,他们对于不理解的包的内容就会丢弃。
除此之外,操作系统也是一个障碍,因为 TCP 协议都是通过操作系统内核实现,应用程序只能使用不能修改。操作系统通常更新缓慢,所以更新内核种的 TCP 协议也非常困难。
HTTP/3 甩掉TCP、TLS 的包袱,构建高效网络
HTTP/2 虽然有上述缺陷,但我们几乎不能通过修改 TCP 来解决这些问题。如果发明新协议,在中间设备上同样也不会被很好支持。
因此,HTTP/3 基于 UDP 实现一种新协议: QUIC。基于 UDP 实现了类似于 TCP 的多路数据流、传输可靠性等功能。
QUIC 协议拥有的功能:
- 实现了类似 TCP 的流量控制、传输可靠性的功能。
QUIC 在 UDP 的基础上加了一层来保证数据可靠性传输,它提供了数据包重传、拥塞控制以及其他一切 TCP 种存在的特性。 - 集成了 TLS 加密功能。
在 TLS1.3 上做了改进,最重要的一点是减少了握手所花费的 RTT 个数。 - 实现了 HTTP/2 中的多路复用功能。
QUIC 实现了在同一物理连接上可以有多个独立的逻辑数据流。数据流的单独传输解决了 TCP 中队头阻塞的问题。
下图为 QUIC 协议中的多路复用。
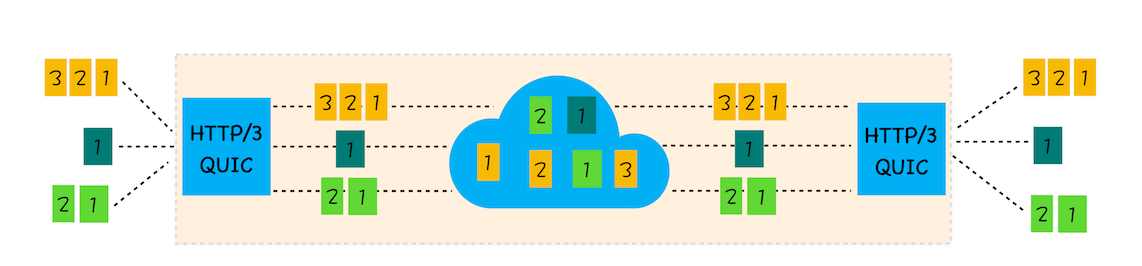
- 实现了快速握手功能。
因为 QUIC 基于 UDP,所以可以在 0~1个 RTT内建立连接,意味着可以用最快的速度来发送和接收数据,大大提高首屏速度。
HTTP/3 Challenge
- 服务器和浏览器端都没有对 HTTP/3 提供较完整的支持。
- 部署存在很大问题,因为系统内核对 UDP 的优化程度远小于 TCP。
- 中间设备对 UDP 的优化程度也远小于 TCP。据统计,大约有 3% ~ 7% 丢包率。

若有收获,就点个赞吧
0 人点赞
