一、hdfs的基本系统架构
HDFS主要采用主备模式,其架构包含NameNode,DataNode,Client三个部分
NameNode:NameNode用于存储、生成文件系统的元数据。运行一个实例。
DataNode:DataNode用于存储实际的数据,将自己管理的数据块上报给NameNode ,运行多个实例。
Client:支持业务访问HDFS,从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行。
二、HDFS数据读取流程
HDFS数据读取流程如下:
1. 业务应用调用HDFS Client提供的API打开文件。
2. HDFS Client联系NameNode,获取到文件信息(数据块、DataNode位置信息)
3. 业务应用调用read API读取文件。
4. HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应的数据快(Client采用就近原则读取数据)
5. HDFS Client会与多个DataNode通讯获取数据块。
6. 数据读取完成后,业务调用close关闭连接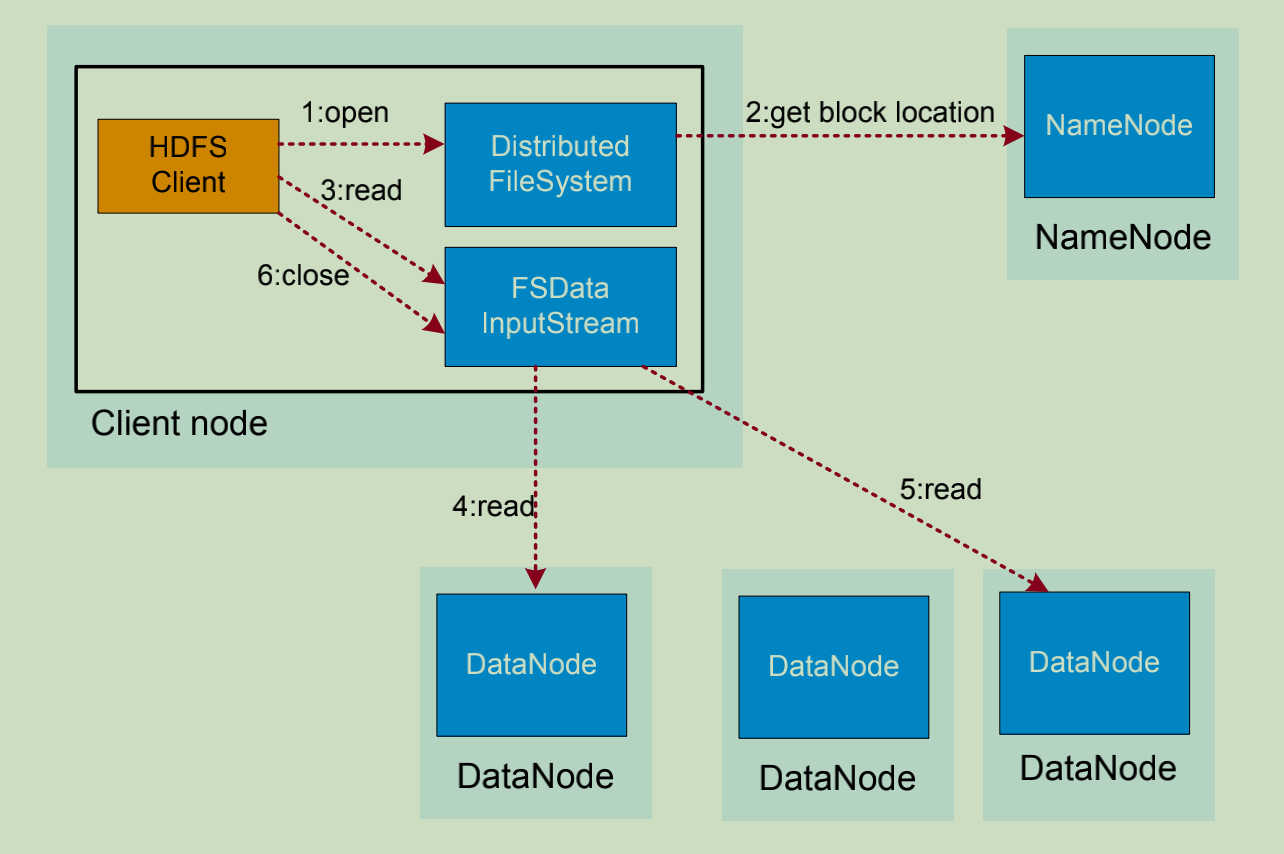
三、HDFS数据写入流程
HDFS数据写入流程如下:
1. 业务应用调用HDFS Client提供的API创建文件,请求写入。
2. HDFS Client联系NameNode,NameNode在元数据中创建文件节点。
3. 业务应用调用write API写入文件。
4. HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并将需要写入数据的DataNode建立起流水线,完成后,客户端再通过自有协议写入数据到Datanode1,再有DataNode1复制到DataNode2,DataNode3。
5. 写完的数据,将返回确认信息给HDFS Client。
6. 所有数据确认完成后,业务调用HDFS Client关闭文件。
7. 业务调用close, flush后,HDFS Client联系NameNode,确认数据包写入完成,NameNode持久化元数据。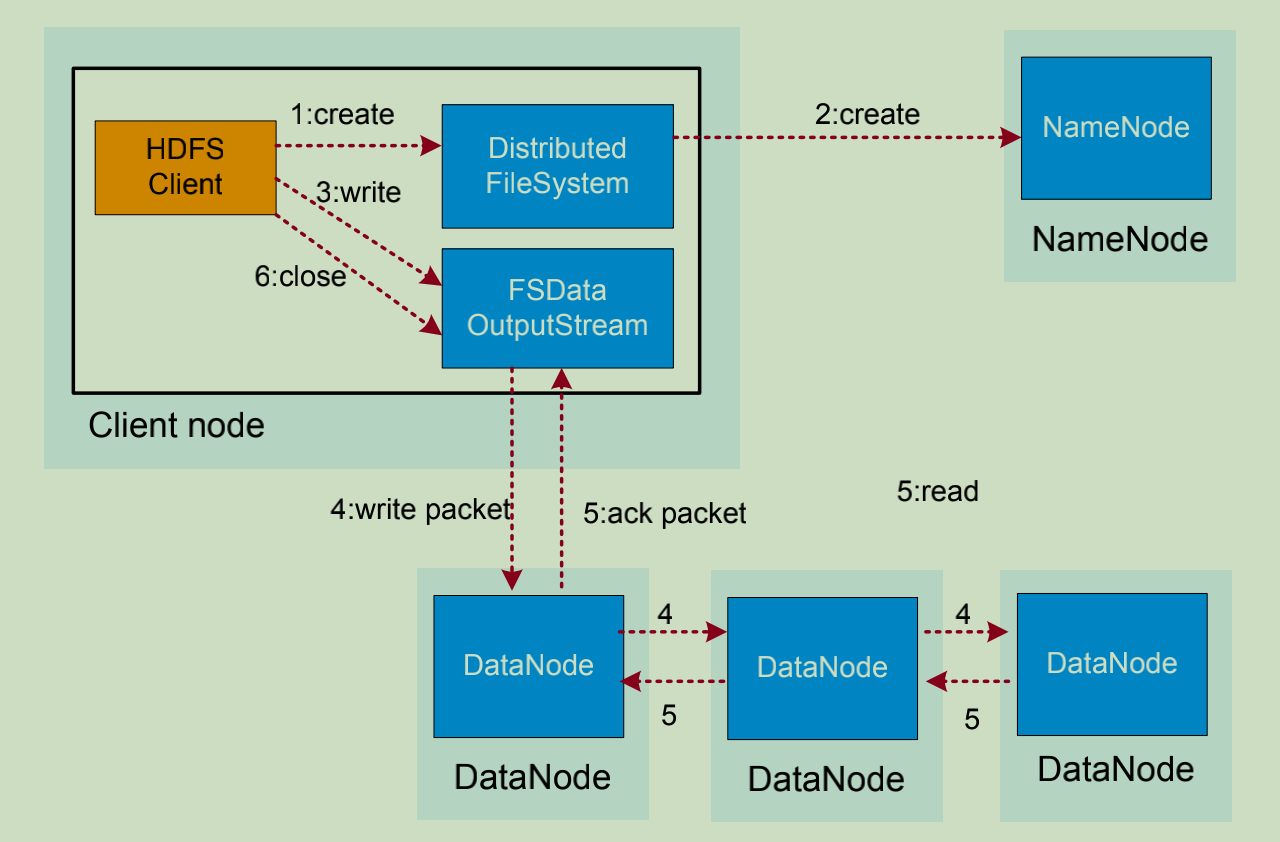
四、HDFS Federation
应用场景
Federation支持上层应用使用多个独立的基于NameNode/Namespace 的 文 件 系 统 。 这 些NameNode之间相互独立且不需要互相协调,各自分工管理自己的区域。
解决方案
一个namespace使用一个block pool管理数据块,每个block pool内部自治,不会与其他block pool交流 。
命名空间管理: Federation中存在多个命名空间,可以使用Client Side Mount Table对命名空间划分和管理。
用户价值
【扩展性】
支持NameNode/Namespace水平扩展,后向兼容,结构简单。
【性能】
文件操作的性能不再制约于单个namenode的吞吐量,支持多个namenode。
【隔离性】
可按照应用程序的用户和种类分离Namespace volume,进而增强了隔离性
五、数据副本机制
副本距离计算公式:
• Distance(Rack1/D1, Rack1/D1)=0 同一台服务器的距离为0
• Distance(Rack1/D1, Rack1/D3)=2 同一机架不同的服务器距离为2
• distance(Rack1/D1, Rack2/D1)=4 不同机架的服务器距离为4
副本放置策略:
• 第一个副本在本地机器
• 第二个副本在远端机架
• 第三个副本看之前的两个副本是否在同一机架,如果是则选择其他机架,否则选择和第一个副本相同机
架的不同节点。
• 第四个及以上,随机选择副本存放位置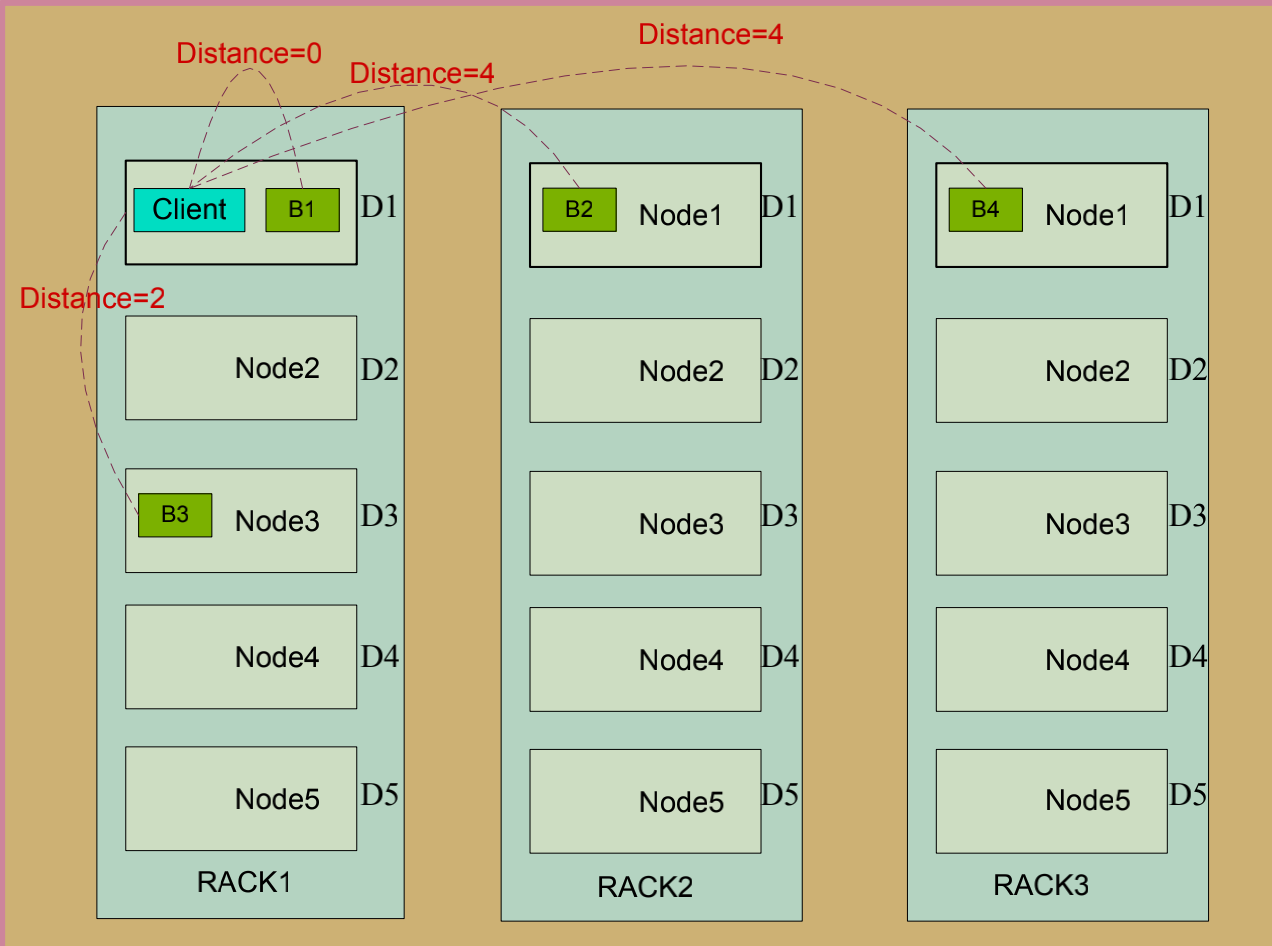
六、元数据持久化
元数据持久化的流程如下:
1. 主用NameNode接收文件系统操作请求,生成EditLog,并回滚日志,向EditLog.new中记录日志。
2. 备用NameNode从主用NameNode上下载FSImage,并从共享存储中读取EditLog。
3. 备用NameNode将日志和旧的元数据合并,生成新的元数据FSImage.ckpt
4. 备用 NameNode将元数据上传到主用NameNode
5. 主用NameNode将上传的元数据进行回滚。
6. 循环步骤1。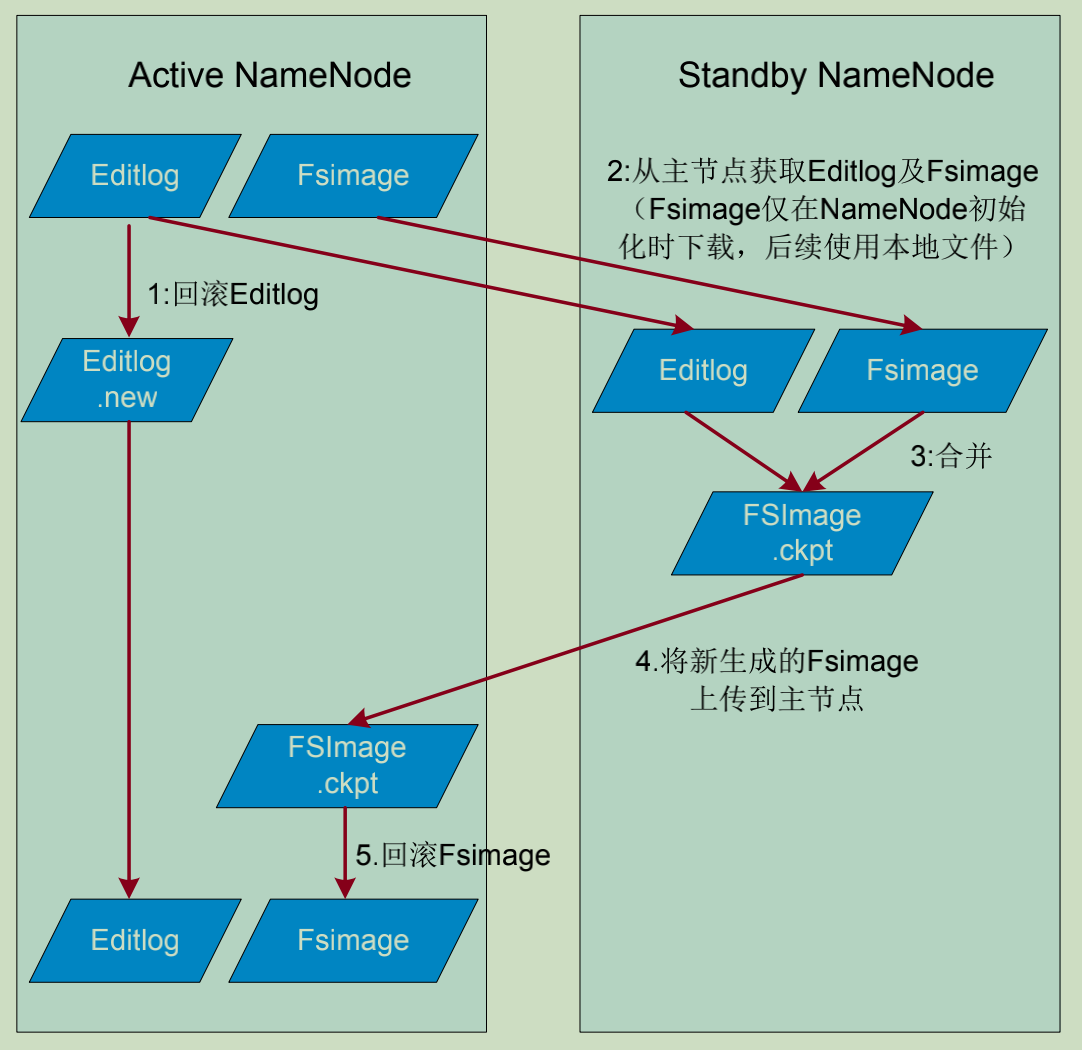
七、元数据持久化健壮机制
HDFS主要目的是保证存储数据的完整性,对于各个组件的失效,做了可靠性处理。
重建失效数据盘的副本数据。
DataNode与NameNode之间通过心跳周期汇报数据状态,NameNode管理数据块是否上报完整,如果
DataNode因硬盘损坏未上报数据块,NameNode将发起副本重建动作恢复丢失的副本。
集群数据均衡
HDFS架构设计了数据均衡机制,此机制保证数据在各个DataNode上存储是平均的。
数据有效性保证
DataNode存储在硬盘上的数据块,都有一个校验文件已之对应,在读取数据时,DataNode会校验器有
效性,若校验失败,则HDFS客户端将从其他数据节点读取数据,并通知NameNode,发起副本恢复。
元数据可靠性保证
采用日志机制操作元数据,同时元数据存放在主备NameNode上。
快照机制实现了文件系统常见的快照机制,保证数据误操作时,能及时恢复。
安全模式
HDFS提供独有安全模式机制,在数据节点故障,硬盘故障时,能防止故障扩散。
八、HDFS高可靠性
HDFS的高可靠性(HA)架构在基本架构上增加了以下组件:
ZooKeeper:
分布式协调,主要用来存储HA下的状态文件,主备信息。ZK个数建议是3个(含)以上且为奇数个。
NameNode主备
NameNode主备模式,主提供服务,备用于合并元数据并作为主的热备。
ZKFC:
ZKFC(ZooKeeper Failover Controller)用于控制NameNode节点的主备状态。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
JN:
JN(JournalNode)用于共享存储NameNode生成的Editlog。
一般导致NameNode切换的原因
随着集群规模的变大和任务量变多,NameNode的压力会越来越大,一些默认参数已经不能满足集群的日常需求,除此之外,异常的Job在短时间内创建和删除大量文件,引起NN节点频繁更新内存的数据结构从而导致RPC的处理时间变长,CallQueue里面的RpcCall堆积,甚至严重的情况下打满CallQueue,导致NameNode响应变慢,甚至无响应,ZKFC的HealthMonitor监控自己的NN异常时,则会断开与ZooKeeper的链接,从而释放锁,另外一个NN上的ZKFC进行抢锁进行Standby到Active状态的切换。这是一般引起的切换的流程。
当然,如果你是手动去切换这也是可以的,当Active主机出现异常时,有时候则需要在必要的时间内进行切换。
ZKFC的作用是什么?如何判断一个NN是否健康
在正常的情况下,ZKFC的HealthMonitor主要是监控NameNode主机上的磁盘还是否可用(空间),我们都知道,NameNode负责维护集群上的元数据信息,当磁盘不可用的时候,NN就该进行切换了。

若有收获,就点个赞吧
0 人点赞
