文章概览
- Kafka 的延迟队列你有了解吗?
- Kafka 的幂等性是怎么实现的?
- 知道 ISR、AR 是什么吗?
- Kafka 中的 HW、LEO、LSO 知道是什么意思吗?
- Kafka 消息有顺序吗?如果有其顺序性是怎么保证的?
- 有遇到过消息重复消费的情况吗?
Kafka 的延迟队列你有了解吗?
Kafka 的延迟队列使用了一个叫“时间轮”的东西来实现的,听起来牛逼哄哄的样子,直接来看图。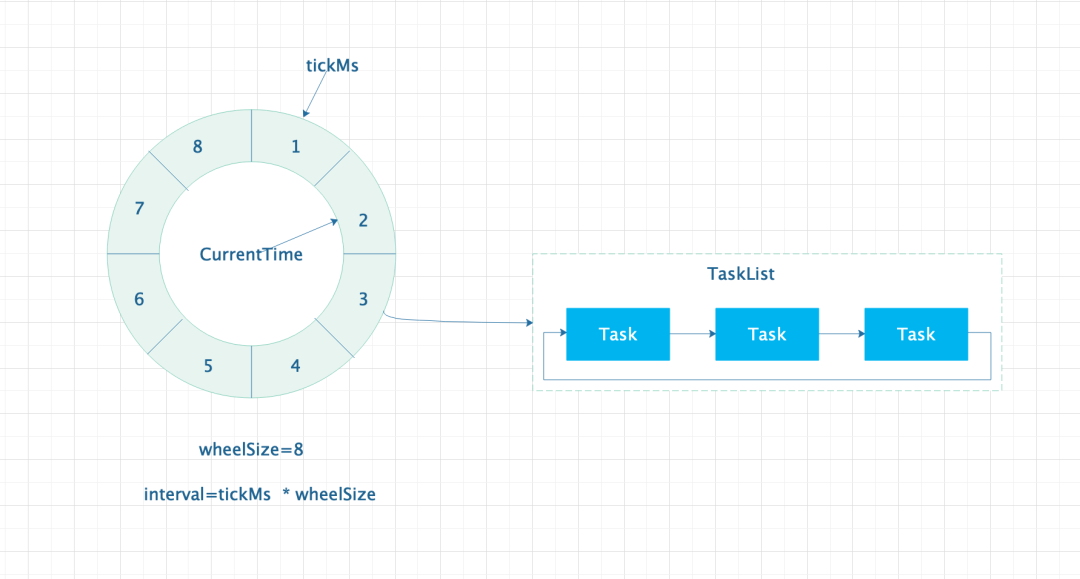 时间轮原理图
时间轮原理图
- TickMs:时间单位,每一格代表一个时间跨度。
- CurrentTime:当前时间,表示当前时间轮运行到的位置。CurrentTime 运行到一个位置,表示当前位置对应的队列中的任务需要被处理。
- TaskList:双端任务队列,其中每个 Task 就是一个实际要执行的任务。
- WheelSize:表示时间轮的容量大小。
- Interval:表示时间轮的最长时间跨度,即最长可以存储的时间跨度有多长。
从上图可以看出,时间轮是由左侧的类似“时钟”的转盘和右侧的任务队列组成。其中左侧的转盘是由一个数组实现的循环队列。看到这里大家应该会有一个疑问,假设时间单位是毫秒,现在需要一个 30 分钟大小的延迟队列,那么时间轮的大小应该是 30 60 1000 = 1800000 大小的数组才能实现。
相信没几个人愿意直接初始化一个这么大的数组,聪明的人类总是会想出各种办法来解决问题,所以就出现了“二级”时间轮和“三级”时间轮。我们暂且把上面的图称之为“一级”时间轮,其每个相邻位置的时间跨度为 1ms,总时间跨度为 1ms 8 = 8ms,二级时间轮相邻位置的时间跨度以一级时间轮总时间跨度为基准,则其二级时间轮的总跨度为 8ms 8 = 64ms,即“二级”时间轮可以容纳 64ms 内的任务,同理,“三级”时间轮以“二级”时间轮的总跨度为基准,则“三级”时间轮的总跨度为 64ms * 8 = 512ms,即三级时间轮可以容纳 512ms 内的任务。假设“一级”时间轮的 WheelSize 设置为 100,30 分钟的延迟任务只需使用三个时间轮,总容量 300 大小就可以容纳所有的任务了。
需要注意的一点是,“二级”和“三级”时间轮是不直接执行任务的,当 CurrentTime 执行到时,会将其对应的任务进行降级操作,降级就是“三级”时间轮的任务降级到“二级”时间轮上,“二级”时间轮上的任务降级到“一级”时间轮上,即所有的任务实际是在“一级”时间轮上执行的。
Kafka 的幂等性是怎么实现的?
幂等性原理
在 kafka0.11 之前是没有幂等性的概念的,在 0.11 之后 Kafka 通过引入 PID 实现了单 Partition 的幂等性。
消息生产端生产的每条消息都会带上一个 PID 值,Broker 端也会缓存当前 Partition 对应的 PID,Broker 接收到消息以后会判断 PID 值,此时可能会产生三种情况。
- 【Broker 中缓存的 PID - 生产端发送的 PID <= 0】,此时认为消息是发生了重传,直接丢弃该条消息。
- 【Broker 中缓存的 PID - 生产端发送的 PID > 1】,此时认为中间的消息发生了丢失,直接丢弃掉该条消息。
- 【Broker 中缓存的 PID - 生产端发送的 PID = 1】,此时认为消息是单调递增,可以正常写入。
开启幂等性
Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 注意,启用幂等性时,需要将其设置为all,否则会报错props.put(ProducerConfig.ACKS_CONFIG, "all");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 启用幂等性props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);kafkaProducer.send(new ProducerRecord<String, String>("truman_kafka_center", "1", "hello world.")).get();kafkaProducer.close();
知道 ISR、OSR、AR 是什么吗?
- ISR:全称 In-Sync-Replicas,表示当前正在同步的从 Partition,该列表是由主 Partition 进行维护的,在该列表中的 Partition 定期从主 Partition 上拉取数据进行同步,若在指定周期内没同步数据,则认为该从 Partition 失效,从 ISR 列表中剔除,并将其移入到 OSR 列表中。
- OSR:全称 Out-Sync-Replicas,没有进行数据同步的从 Partition 列表,其中包括失效的从 Partition 和刚刚加入进来的新 Partition。处于 OSR 列表中的 Partition 不能够进行数据的同步操作。
AR:全称 Assigned-Replicas,一个 Partition 对应的主从所有的 Partition 列表,AR = ISR + OSR。
Kafka 中的 HW、LEO、LSO 知道是什么意思?
 位置示意图
位置示意图HW:全称 High-Water,即“高水位”,处于 HW 之前的数据才可能被正常消费,处于 HW 之后的数据不能够被消费。
- LEO:全称 Log-End-Offset,表示下一条消息被写入的位置。注意,每次消息被写入后会更新 LEO 值,所以 LEO 值代表的不是当前最新一条消息的位置,而是下一条消息要被写入的位置。
- LSO:全称 Last-Stable-Offset,表示为 LSO 之前的消息都已经被确认,而在 LSO 之后的消息还未被确认,其主要被用于事务。
Kafka 消息有顺序吗?如果有其顺序性是怎么保证的?
Kafka 无法做到消息全局有序,只能做到 Partition 维度的有序。所以如果想要消息有序,就需要从 Partition 维度入手。一般有两种解决方案。
- 单 Partition,单 Consumer。通过此种方案强制消息全部写入同一个 Partition 内,但是同时也牺牲掉了 Kafka 高吞吐的特性了,所以一般不会采用此方案。
多 Partition,多 Consumer,指定 key 使用特定的 Hash 策略,使其消息落入指定的 Partition 中,从而保证相同的 key 对应的消息是有序的。此方案也是有一些弊端,比如当 Partition 个数发生变化时,相同的 key 对应的消息会落入到其他的 Partition 上,所以一旦确定 Partition 个数后就不能在修改 Partition 个数了。
有遇到过消息重复消费的情况吗?是怎么解决的?
有,发生过两次重复消费的情况。发现用户的”xx”计数偶现大于实际情况,排查日志发现大概意思是心跳检测异常导致 commit 还没有来得及提交,对应的 Partition 被重新分配给其他的 Consumer 消费导致消息被重复消费。
解决方式 1:调整降低消费端的消费速率、提高心跳检测周期。
通过方案 1 调整参数后,还是会出现重复消费的情况,只是出现的概率降低了。
- 解决方案 2:在业务层增加 Redis,在一定周期内,相同 key 对应的消息认为是同一条,如果 Redis 内不存在则正常消费消费,反之直接抛弃。

若有收获,就点个赞吧
0 人点赞
