我们都知道java中io操作分为字节流和字符流,对于字节流,顾名思义是按字节的方式读取数据,所以我们常用字节流来读取二进制流(如图片,音乐等文件)。问题是为什么字节流中定义的read()方法返回值为int类型呢?既然它一次读出一个字节数据为什么不返回byte类型呢?
网上的说法不能说它是错误的,只是我感觉没有解释清楚,接下来我们以FileInputStream /FileOutputStream和BufferedInputStream/BufferedOutputStream为例,这两个来解释一下为什么是这样的,以及中间实现过程是什么。
一、我们以FileInputStream/FileOutputStream角度来说,这个主要是与调用的native方法有关,想知道必须看native层怎么实现。
FileInputStream中read()源码:
public int read() throws IOException {return read0();}private native int read0() throws IOException;
这里我们是看不出为什么read()方法为什么要返回int类型的,所以我们深入点,看Native层代码:
/////////////////////////////////////////////////////////////////////// FilelnputStream.cJNIEXPORT jint JNICALLJava_java_io_FileInputStream_read0(JNIEnv *env, jobject this) {return readSingle(env, this, fis_fd);}////////////////////////////////////////////////////////////////////// io_util.c文件jintreadSingle(JNIEnv *env, jobject this, jfieldID fid) {jint nread;char ret;FD fd = GET_FD(this, fid);if (fd == -1) {JNU_ThrowIOException(env, "Stream Closed");return -1;}// 调用IO_Readnread = IO_Read(fd, &ret, 1);if (nread == 0) { /* EOF */return -1;} else if (nread == -1) { /* error */JNU_ThrowIOExceptionWithLastError(env, "Read error");}return ret & 0xFF;}
这里Java_java_io_FileInputStream_read0方法就是JDK中read0()调用的native方法
可以看到这里,我们重点关注的是如果读取结束,则返回一个int类型的-1,否则的话就是返回ret(这里是一个byte数据)返回的是byte,而& 0xFF是为了保证由byte 类型向上拓展成int的时候,不进行符号拓展,而是0拓展。
以上就是实现过程,相信看到这里大家也知道为什么Java IO流的read()返回的是int而不是byte了,因为底层对byte进行了int扩展
那么为什么这么做呢,我们知道字节输入流可以操作任意类型的文件,比如图片音频等,这些文件底层都是以二进制形式的存储的,如果每次读取都返回byte,会有可能在读到111111111,而11111111是byte类型的-1,程序在遇到-1就会停止读取,用int类型接收遇到11111111会在其前面补上24个0凑足4个字节,那么byte类型的-1就变成int类型的255了,这样可以保证整个数据读完。而结束标记的-1是int类型的来作为判断的,像下面这样。
(这里我们要时刻明白一个道理,使用的-1这个结束标志是通过一个判断文件结尾的返回的,而不是输入流读到了一个-1,这里就是为了避免这种情况!)
利用是&0xFF进行0扩展的原因(计算机中存储数据都是用的补码形式,不懂的先去了解下)
1个字节8位,(byte) 4个字节32位,(int)
byte -1 —->int -1(将byte提升为int)
byte 是1一个字节,即8位,如果取到连续11111111,为了避免读到连续8个1(就是-1)和定义的结束标记-1相同(read()返回-1就是读到末尾)。所以在保留11111111的基础上,在转成int类型时,前面24位补0而不补1。
如果是补1(比如强转) 11111111 11111111 11111111 11111111不还是-1?
所以前面24位补0,-1变成了255,既可以保留原字节数据不变(最低8位,配合write方法强转),又可以避免-1的出现。
我们继续看FileOutputStream里面的write方法,也是调用了一个本地native方法。
public void write(int b) throws IOException {write(b, fdAccess.getAppend(fd));}private native void write(int b, boolean append) throws IOException;
直接看Native层代码:
////////////////////////////////////////////////////////////////////// FileOutputStream.cJNIEXPORT void JNICALLJava_java_io_FileOutputStream_write(JNIEnv *env, jobject this, jint byte, jboolean append) {// writeSingle:写入单个字节writeSingle(env, this, byte, append, fos_fd);}////////////////////////////////////////////////////////////////////// io_util.c文件voidwriteSingle(JNIEnv *env, jobject this, jint byte, jboolean append, jfieldID fid) {// Discard the 24 high-order bits of byte. See OutputStream#write(int)// 这里通过强转处理了int的高24位字节,变成了一个字节char c = (char) byte;jint n;// 获取文件句柄(Windows)FD fd = GET_FD(this, fid);if (fd == -1) {JNU_ThrowIOException(env, "Stream Closed");return;}if (append == JNI_TRUE) {// 向后追加n = IO_Append(fd, &c, 1);} else {// 覆盖写入n = IO_Write(fd, &c, 1);}if (n == -1) {JNU_ThrowIOExceptionWithLastError(env, "Write error");}}
这里就是将字节一个个的写入,在写入前在OutputStream.write(int)方法中通过强转处理了int的高24位字节,实现原数据的还原
对这JDK有明确表示
所以这样一来就保证了数据读和写的无差错。这也是为什么JDK的OutputStream及其子类为什么方法write(int b)的入参类型是int的原因。(Java中有byte类型,c语言中没有,可能也是用int的原因)
二、扩展:从BufferedInputStream/BufferedOutputStream角度来说
BufferedInputStream中的read()方法的实现
/*** See* the general contract of the <code>read</code>* method of <code>InputStream</code>.** @return the next byte of data, or <code>-1</code> if the end of the* stream is reached.* @exception IOException if this input stream has been closed by* invoking its {@link #close()} method,* or an I/O error occurs.* @see java.io.FilterInputStream#in*/public synchronized int read() throws IOException {if (pos >= count) {fill();if (pos >= count)return -1;}return getBufIfOpen()[pos++] & 0xff;}private byte[] getBufIfOpen() throws IOException {byte[] buffer = buf;if (buffer == null)throw new IOException("Stream closed");return buffer;}
从上面的源码我们可以看到,getBufIfOpen()方法返回的byte[],也通过& 0xff进行了0扩展,即read()方法的最后一行把读到的字节 0扩展成了int。实现了一个字节的数据的返回,如果达到流的末尾, 则返回-1(这里是int类型)
而在BufferedOutputStream中的writer()方法果断的又将int强制转成了byte(截取后八位)
public synchronized void write(int b) throws IOException {if (count >= buf.length) {flushBuffer();}buf[count++] = (byte)b;}
想必看到这里,应该知道这样做的原因吧:在用输入流读取一个byte数据时,有时会出现连续8个1的情况,这个值在计算机内部表示-1,正好符合了流结束标记。所以为了避免流操作数据提前结束,将读到的字节进行int类型的扩展。保留该字节数据的同时,前面都补0,避免出现-1的情况。
真正读到文件最后结束是通过这句实现的:if (pos >= count) return -1;
我们使用的-1这个结束标志是通过这句返回的,而不是输入流读到了一个-1。
最后总结一下,Java IO流中read()方法返回int而不是byte主要就是为了避免流操作提前结束,要保证能完全读取到数据。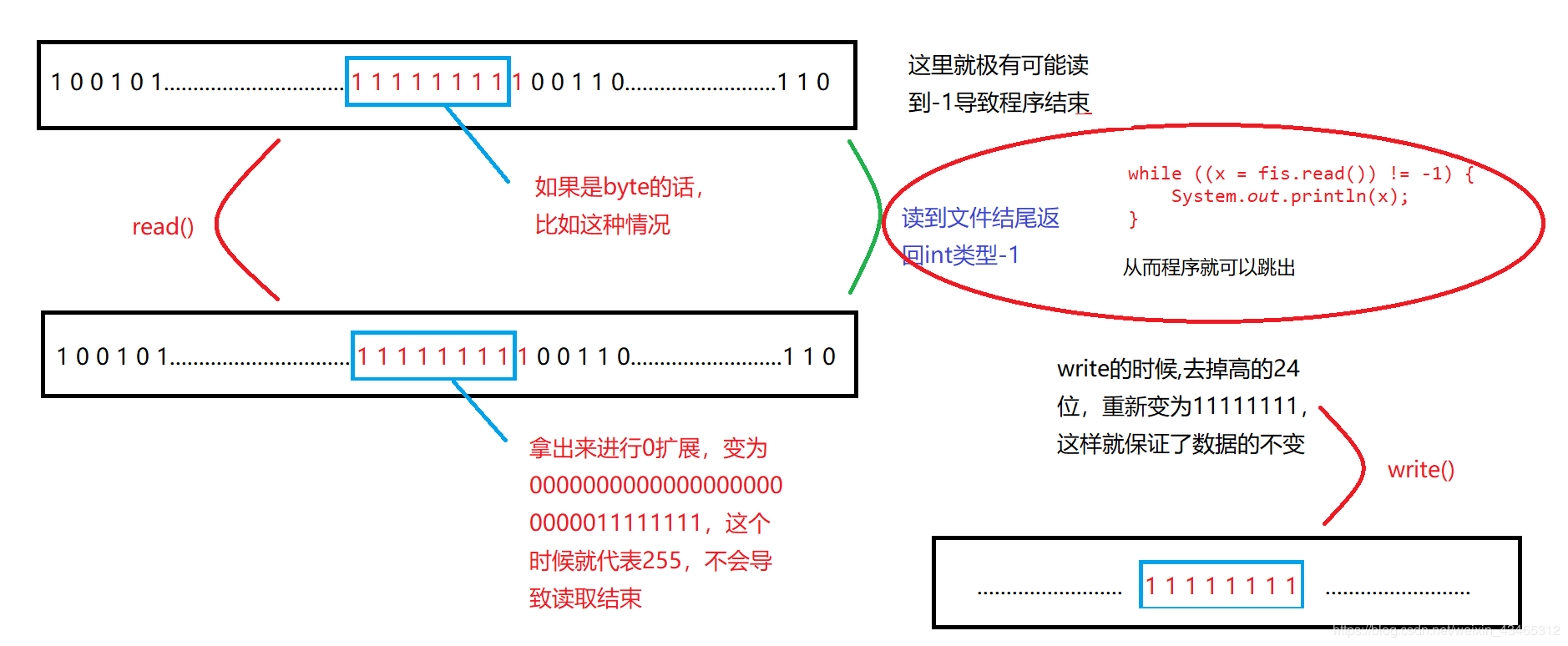
P.S.小知识:Java中低位向高位扩展是补符号位扩展,高位向低位强转是高位截断,低位保留

若有收获,就点个赞吧
0 人点赞
