一、HashMap原理浅谈
HashSet,HashMap,HashTable存储元素都是靠哈希表, HashSet底层实现本质上就是靠HashMap,HashTable我们就当跟HashTable一样
Collection接口下的Set接口下的Hashset类调用add方法来实现存储
所以接下里我们以Map接口实现类的HashMap来讲解原理
put方法里面调用了putVal方法,里面传了三个参数,第一个是通过hash方法生成的哈希值,第二个是键,第三个是值。
这里的hash方法就是我们通常所说的哈希算法,对于哈希算法和哈希值的生成,美团技术团队的一篇文章写得特别好,下面就引用他们的话:
HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表,大大优化了查询的效率。HashMap定位数组索引位置,直接决定了hash方法的离散性能。先看看源码的实现(方法一+方法二):
所以看来Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
对于任意给定的对象,只要它的hashCode()返回值相同,那么程序调用方法一所计算得到的Hash码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,在HashMap中是这样做的:调用方法二来计算该对象应该保存在table数组的哪个索引处。
这个方法非常巧妙,它通过h & (table.length -1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
另外我们注意到hash方法调用了hashCode方法,这个也就是为什么要一般要重写的hashCode方法的原因,这里key就是我们传入的对象或者叫存储的对象。因为如果是自定义对象没重写覆盖的话,hashCode方式就是object类的方法。随之而来的肯定也是重写equals方法。
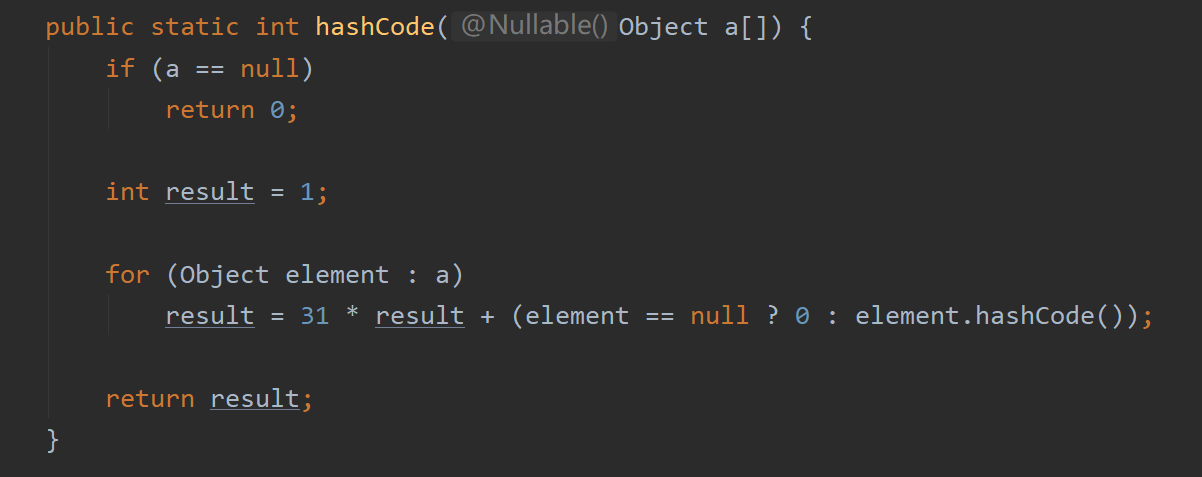
p.s. 一般来说我们自定义的对象,重写hashCode值最终会调用Arrays里面定义的hashCode方法,通过31的一个公式生成一个哈希值。

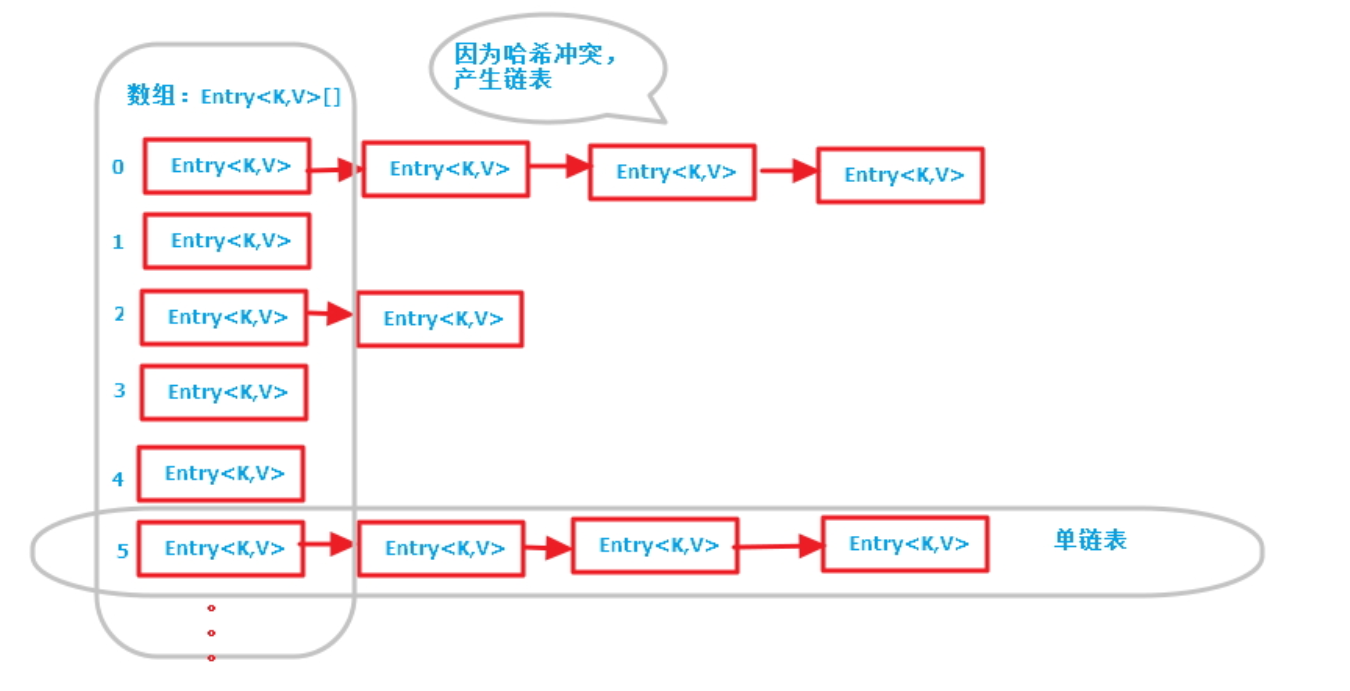
我们通过Hash算法生成相应的哈希值,再根据key的哈希值得到一个数组索引,然后根据索引找到链表表头结点,之后进行一系列操作将元素(这里主要是值键值对对象)决定是否存进去。存在哈希冲突就根据equals判断对象(键)是否相等,相等则不存(替换值)。前者针对HashSet,后者针对HashMap;如果不相等的话,那就存在链表后面。
简而言之就是三种情况:
- 哈希值相等,对象相等,不存
- 哈希值相等,但是对象不相等,则存入节点后面形成链表
- 哈希值不相等,那就肯定不是同一个对象,存入
下面是putVal具体实现过程
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
可以明显的看到这个是实现就是通过传入的hash值进行判断存值,哈希值一样,里面就会调用equal方法进行进行对比是否相等,决定是否存入;哈希值不一样的话,直接存。
二、TreeMap原理浅谈
TreeSet和TreeMap都是添加元素和排序都是靠二叉树来实现的。TreeSet的add方法调用了

而NavigableMap接口继承自SortedMap接口,对于SortedMap来说,该类是TreeMap体系中的父接口,也是区别于HashMap体系最关键的一个接口。 主要原因就是SortedMap接口中定义的第一个方法—-Comparator<? super K> comparator(); 该方法决定了TreeMap体系的走向,有了比较器,就可以对插入的元素进行排序了;
说了这么多其实就是说TreeSet里面调用NavigableMap接口实例化对象的put方法,而NavigableMap接口有一个实现子类叫TreeMap,所以本质上TreeSet add方法调用的put方法是TreeMap里put方法功能。
TreeMap添加元素并排序的实现过程,调用put方法
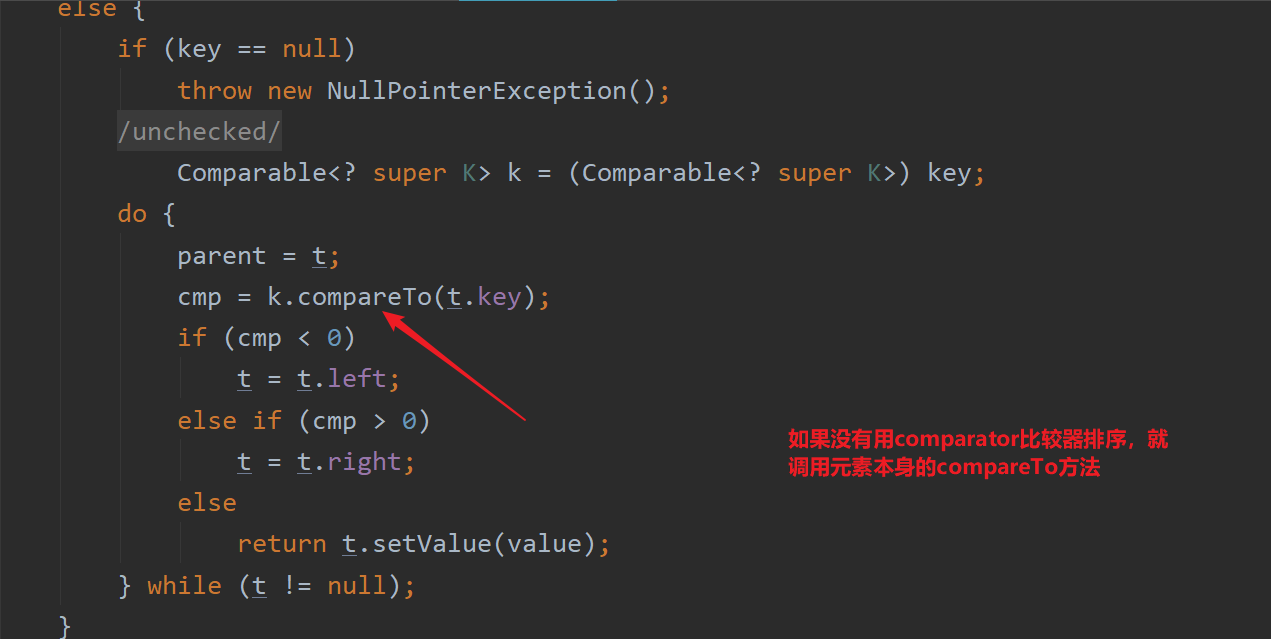
public V put(K key, V value) {Entry<K,V> t = root;if (t == null) {compare(key, key); // type (and possibly null) checkroot = new Entry<>(key, value, null);size = 1;modCount++;return null;}int cmp;Entry<K,V> parent;// split comparator and comparable pathsComparator<? super K> cpr = comparator;if (cpr != null) {do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}else {if (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}Entry<K,V> e = new Entry<>(key, value, parent);if (cmp < 0)parent.left = e;elseparent.right = e;fixAfterInsertion(e);size++;modCount++;return null;}
详细解释一下这段代码,一开始判断该TreeMap中有无元素,没有的话就添加作为根节点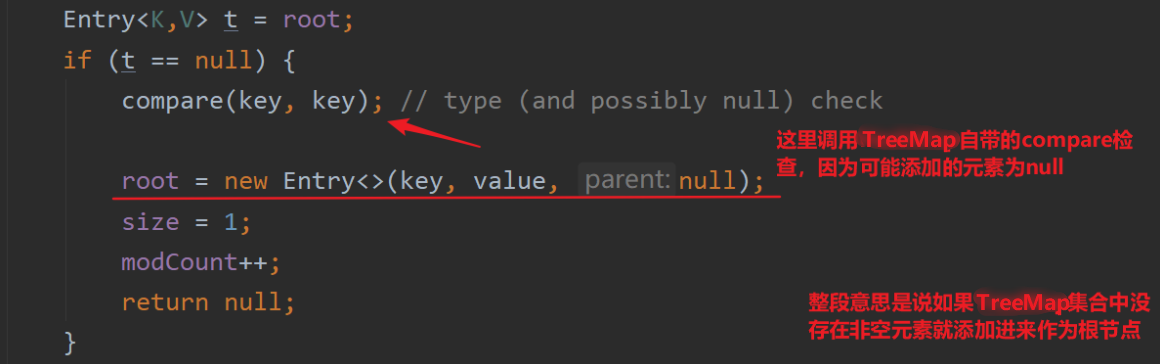
这里调用的compare方法的具体源码
下面就是为什么TreeMap添加的元素必须是可比较的原因,要不就是调用Comparator接口的compare方法,要不就是调用元素本身类自带的compareTo方法,否则就会报错。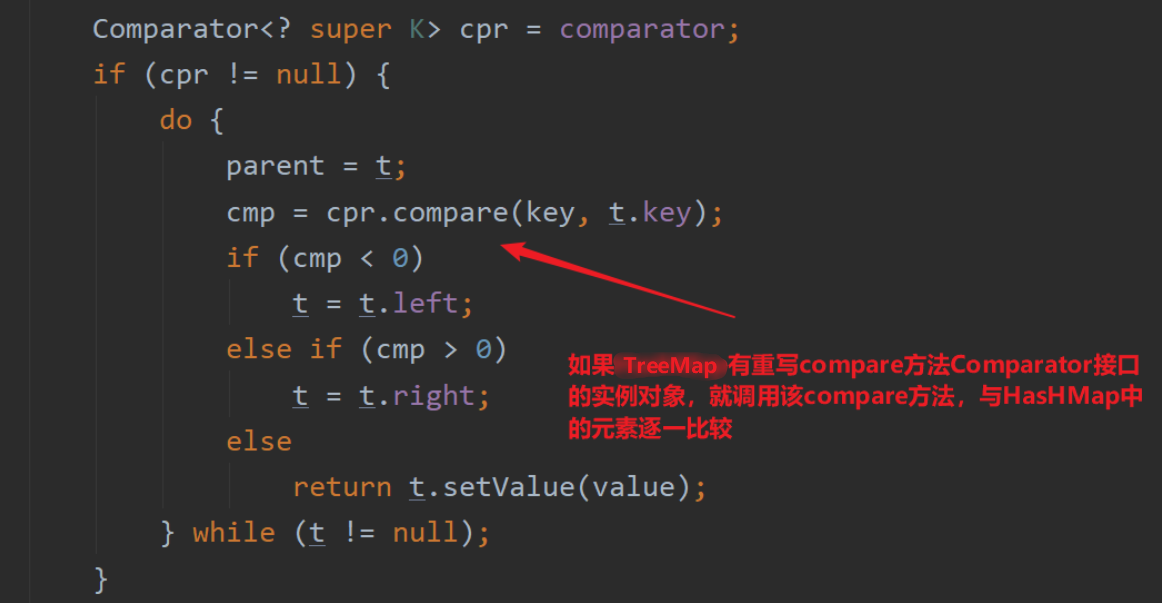
整个代码实现非重复添加和排序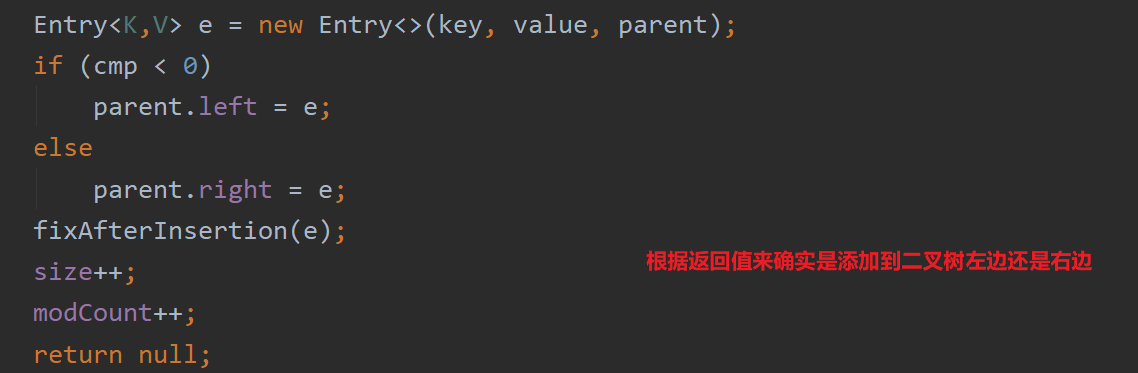

若有收获,就点个赞吧
0 人点赞
