一、Object类的equals()方法
源码如下
public boolean equals(Object obj) {return (this == obj);}
public boolean equals(Object obj) 返回值:布尔值true或者falseequals方法在非空对象引用上实现等价关系:
- 自反性:对于任何非空参考值x,x.equals(x)应该返回true。
- 对称性:对于任何非空参考值x和y,当且仅当y.equals(x)返回true时,x.equals(y)才应返回true。
- 可传递性:对于x,y和z的任何非空引用值,如果x.equals(y)返回true,而y.equals(z)返回true,则x.equals(z)应该返回true。
- 一致性:对于任何非空引用值x和y,如果未修改对象的equals比较中使用的信息,则多次调用x.equals(y)始终返回true或始终返回false。
- 对于任何非null参考值x,x.equals(null)应该返回false。
类Object的equals方法在对象上实现了最有区别的对等关系。也就是说,对于任何非空参考值x和y,当且仅当x和y引用相同的对象(x==y的值为true)时,此方法才返回true。
请注意,通常有必要在每次重写此方法时都重写hashCode方法,以便维护hashCode方法的常规协定,该协定规定相等的对象必须具有相等的哈希码。(这个也是本文的重点)
我们看到equals是比较两个对象是否完全相等,即引用地址是否一致,在一定程度上说,没重写Object类的equals方法前equals等价于==,而==运算符是判断两个对象是不是同一个对象,即他们的地址是否相等。所以Object类的这个方法应用场景就不是很多,在很多时候我们更多的是追求两个对象在逻辑上的相等,你可以说是值相等,也可说是内容相等。所以一般来说基本上Object类的子类很多都会重写equals方法。
当然也有不需要重写这个Object类的equals方法的,如以下几种条件中,不重写equals就能达到目的:
- 类的每个实例本质上是唯一的:强调活动实体的而不关心值得,比如Thread,我们在乎的是哪一个线程,这时候用equals就可以比较了。
- 不关心类是否提供了逻辑相等的测试功能:有的类的使用者不会用到它的比较值得功能,比如Random类,基本没人会去比较两个随机值。
- 超类已经覆盖了equals,子类也只需要用到超类的行为:比如AbstractMap里已经覆写了equals,那么继承的子类行为上也就需要这个功能,那也不需要再实现了。
- 类是私有的或者包级私有的,那也用不到equals方法:这时候需要覆写equals方法来禁用它。(可以把它看做一种不需要重写的特殊情况):
@Override public boolean equals(Object obj) { throw new AssertionError();}
二、Object类中的hashCode()方法
官方API文档链接
源码如下
public native int hashCode();
public int hashCode()介绍: 返回值: 该对象的哈希码值。
返回对象的哈希码值。支持这种方法是为了散列表,如HashMap提供的那样。hashCode的一般约定是:
- 只要在Java应用程序执行期间在同一对象上多次调用它,
hashCode方法就必须一致地返回相同的整数,前提是不修改该对象的equals比较中使用的信息。 从一个应用程序的一次执行到同一应用程序的另一次执行,此整数不必保持一致。 - 如果根据
equals(Object)方法两个对象相等,则在两个对象中的每个对象上调用hashCode方法必须产生相同的整数结果。 - 不要求如果两个对象根据
equals(java.lang.Object)方法不相等,那么在两个对象中的每个对象上调用hashCode方法必须产生不同的整数结果。 但是,开发者应该意识到,为不等对象生成不同的整数结果可能会提高哈希表的性能。
尽可能多的合理实用,由类别Object定义的hashCode方法确实为不同对象返回不同的整数。
(这通常通过将对象的内部地址转换为整数来实现,但Java的编程语言不需要此实现技术。这个原因是因为有__JNI帮助我们实现)
Object类中hashCode()方法源码(JDK11):
很简短的两行代码就实现了对对象的hashcode值生成。
那么究竟这个一行代码时如何工作的呢,注意到有个native关键字,这个就是原理所在之处,上面我们说到JNI,具体就是Java平台有个用户和本地C代码进行互操作的API,称为Java Native Interface (Java本地接口)。它提供了若干的API实现了Java和其他语言的通信(主要是C&C++)
hashCode()方法加了一个关键字native,就代表是一个native接口.执行这个方法时,会根据jni.h来找到真正的C来编写的hashCode()的实际函数。注:下图是JDK中jni.h所在位置
对于native关键字和jni有兴趣的可以详细去了解一下。
1.Java关键字(二)——native
2.Java中Native关键字的作用
3.JNI详解———完整Demo
所以Object类中hashCode()方法其实是调用了系统本地的一些C函数来实现生成hashcode值,准确来说,Object的hashCode方法会根据对象的地址生成对相应的hashcode值。hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。
补充知识点:
native 关键字在JDK源码中很多类中都有,在 Object.java类中,其getClass() 方法、hashCode()方法、clone() 方法等等都是用native关键字修饰的。
public final native Class<?> getClass();public native int hashCode();protected native Object clone() throws CloneNotSupportedException;
三、Object的子类重写equals()方法(以String类举例)
源码如下(JDK11)
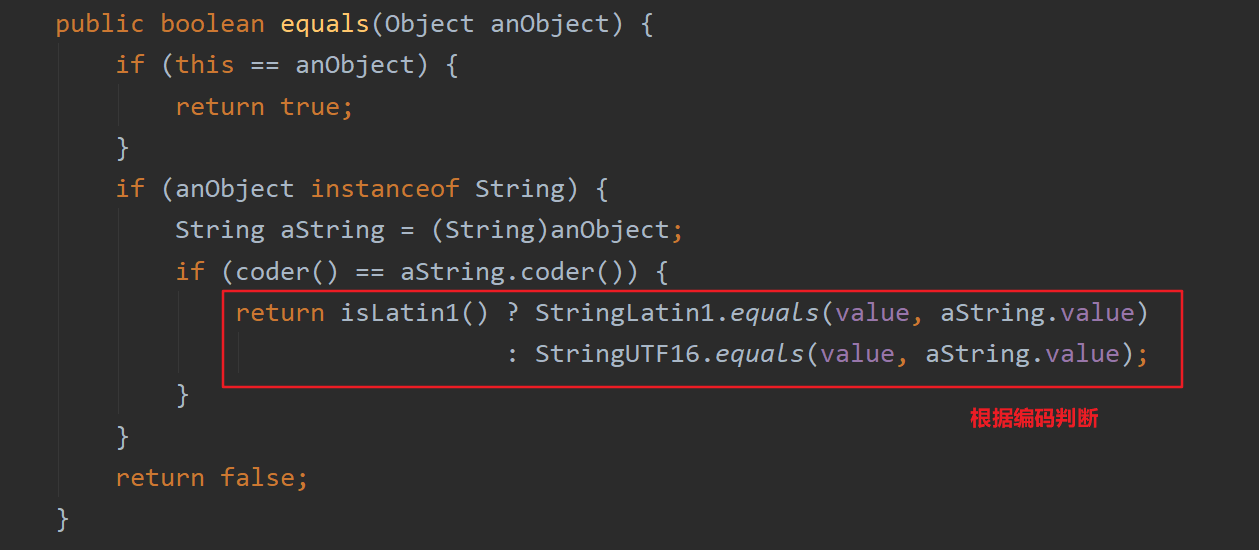
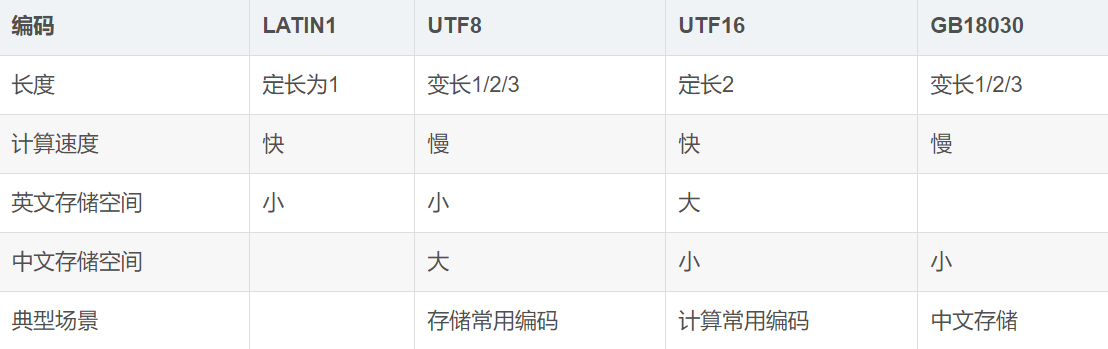
这里String类做了个判断,判断字符编码来决定分别调用了StringLatin1类还是StringUTF16类equals()方法。(这是JDK9以后的特性,JDK9之后,value类型从char[]变成byte[],增加了一个字段code,如果字符全部是ASCII字符,使用value使用LATIN编码;如果存在任何一个非ASCII字符,则用UTF16编码。这种混合编码的方式,使得英文场景占更少的内存。缺点是导致Java 9的String API性能可能不如JDK 8,有些场景下降10%)
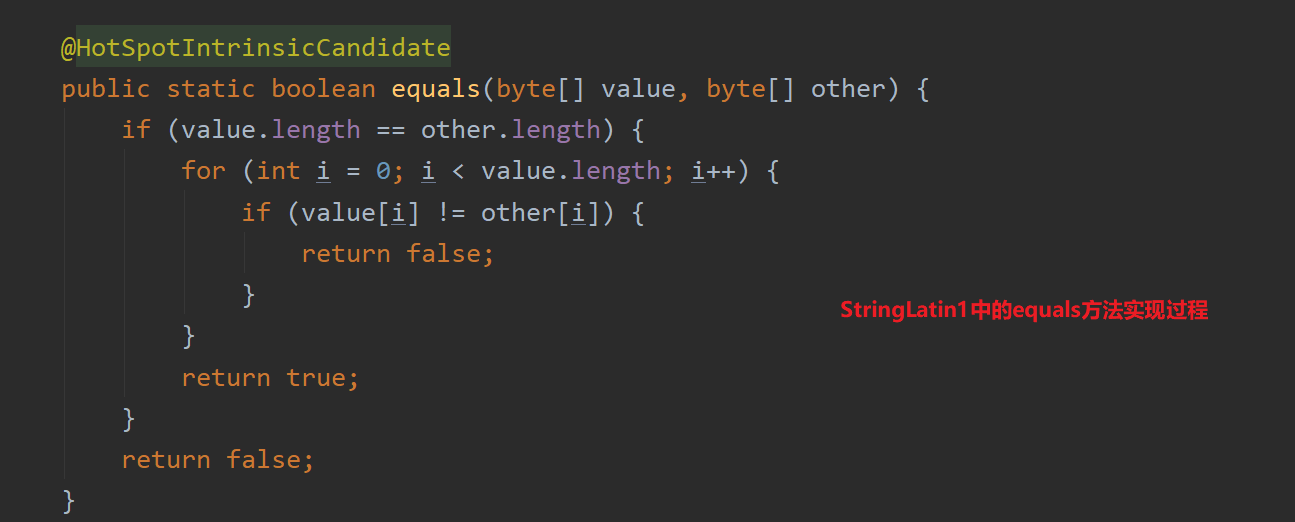
1.如果字符串是Latin1编码,调用StringLatin1类的equals()方法来实现String类equals方法的重写
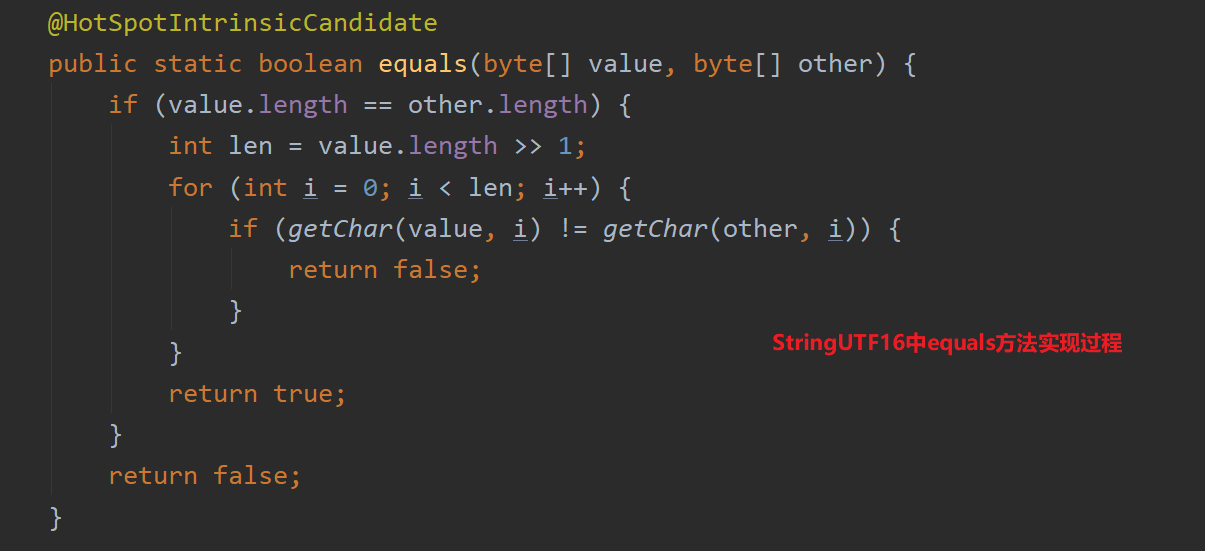
2.如果字符串是UTF16编码,调用StringUTF16类的equals()方法来实现String类equals方法的重写
不管是那种,最后得到的效果就是String类的equals方法是判断字符串内容是否相等。所以,这样我们就可以知道Object子类其实很多都重写equals方法来为自己服务,String类就是一个代表
P.S. __不同版本的JDK String的实现不一样,从而导致有不同的性能表现。char是UTF-16编码,但String在JDK 9之后内部可以有LATIN1编码。
想了解更多可以看这篇文章:Java字符串编码介绍
四、Object的子类重写hashCode()方法(以String类举例)
Object类定义了hashCode()方法是调用的一个本地方法,跟跑的系统有关,当然我们可以在自己写的类中覆盖hashCode()方法,比如String、Integer、Double等这些类都是覆盖了hashCode()方法的。以String类为例,我们讲解一下String类中重写的hashCode()方法。源码如下(JDK11)
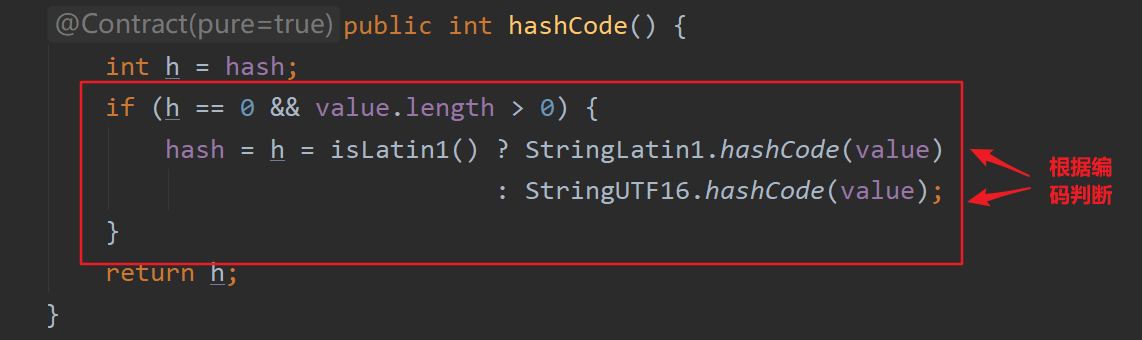
这里String类做了个判断,判断字符编码来决定分别调用了StringLatin1类还是StringUTF16类hashCode()方法,原因上面说过了。
1.如果字符串是Latin1编码,调用StringLatin1类的hashCode()方法来实现String类equals方法的重写
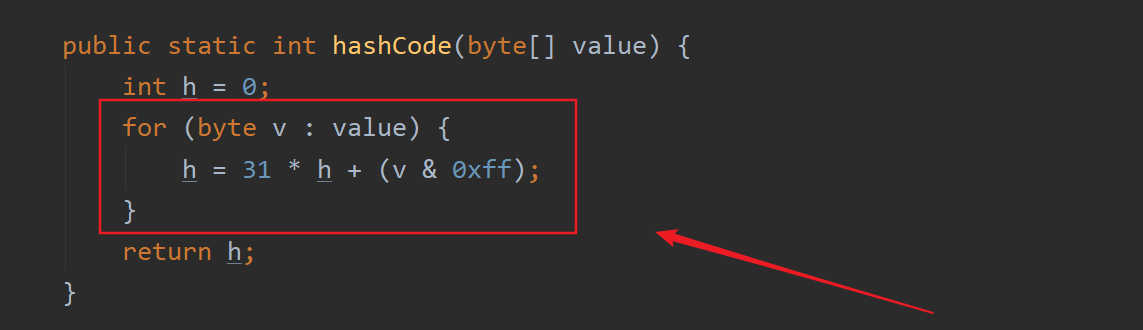
2.如果字符串是UTF16编码,调用StringUTF16类的hashCode()方法来实现String类equals方法的重写
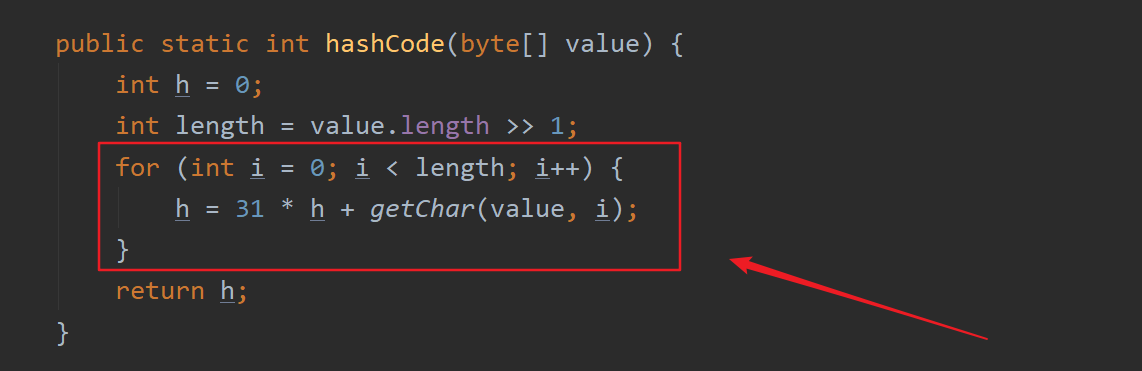
不管过程如何,最后通过String类的hashCode()方法返回的是返回此字符串的hashCode值。 String对象的hashCode值为s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] —-使用int算术,其中s[i]是字符串的第i个字符,
n是字符串的长度, ^表示取幂。 (空字符串的哈希值为零)
最后生成的哈希码是跟String对象的每一个字符相关的,所以两个内容相等的字符串必然也就生成的哈希码相同。
五、equals和hashCode方法的作用以及应用
从上面知道Object类的equals方法是判断两个对象是否相等即引用地址值是否一样,hashCode方法是生成哈希码,也称散列码(hash code),这个哈希码的作用是确定该对象在哈希表中的索引位置。也就是说每一个不同的对象生成的哈希码是不同的。我们举例来说:
public class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public void setName(String name) {this.name = name;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public int getAge() {return age;}}
我们定义了一个Person类,定义了它的两个属性,name和age,然后我们在main方法中创建两个Person对象,并调用equals方法比较是否相等,和调用hashCode方法来查看生成的哈希码。
public static void main(String[] args) {Person p1 = new Person("张三",23);Person p2 = new Person("李四",24);boolean b = p1.equals(p2);System.out.println(b);System.out.println(p1.hashCode());System.out.println(p2.hashCode());}
运行结果是false,然后两个对象的哈希码都是不一样的,验证了我们上面的说法。
既然这是“最原始”的equals和hashCode方法,那我们接下来就来用用重写之后的这两个方法,还是以String为例
public static void main(String[] args) {String s1 = "abc";String s2 = "abc";boolean b = s1.equals(s2);System.out.println(b);System.out.println(s1.hashCode());System.out.println(s2.hashCode());}
运行结果是true,两个对象的哈希码都是一样的,那么为什么跟我们上面那个不一样呢,原因想必都知道,那就是String重写了equals和hashCode方法。这里也间接解释了这句话如果根据equals(Object)方法两个对象相等,则在两个对象中的每个对象上调用hashCode方法必须产生相同的整数结果。(不记得的请看此文的第二部分那里关于hashCode的约定)
通过这里我们就知道了在某些情况下重写equals和hashCode方法能给我们开发带来很大的便利,还记得前文中提到的这句话吗?(第一部分里的)
请注意,通常有必要在每次重写此方法时都重写hashCode方法,以便维护hashCode方法的常规协定,该协定规定相等的对象必须具有相等的哈希码。(这个也是本文的重点)
这里说到了重写equals每次有必要要重写hashCode方法,是一定的吗?答案是不一定,但是非常有必要,十分重要,所以在一定程度上就是一定的。乃至于官方文档都说Note that it is generally necessary to override the hashCode method whenever this method is overridden,乃至网上很多博客都说是一定要。那么原因是什么呢,我们得先从HashCode的作用或者叫主要用途来说起。
hashCode()方法定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode()函数。虽然,每个Java类都包含hashCode() 函数。但是,仅仅当创建并某个“类的散列表”(关于“散列表”见下面说明)时,该类的hashCode()才有实际作用(作用是:确定该类的每一个对象在散列表中的位置;其它情况下(例如,创建类的单个对象,或者创建类的对象数组等等),类的hashCode()没有什么具体的实际作用。
上面的散列表,指的是:Java集合中本质是散列表的类,如HashMap,Hashtable,HashSet。
也就是说:hashCode()在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
想要弄明白hashCode的作用,必须要先知道Java中的集合。
总的来说,Java中的集合(Collection)有两类,一类是Collection,一类是Map。总所周知Collection接口下的List和Set类。前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。这里就引出一个问题:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?我们以Set类中的HashSet来举例说明(`HashMap,Hashtable原理也差不多,都是用的哈希算法`)<br /> 对于如何去除集合中重复的元素,一般很多人都是想到equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。 <br /> 于是,Java采用了哈希表的原理。哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上,初学者可以简单理解,hashCode方法实际上返回的就是对象存储的物理地址(实际可能并不是)。 <br /> 这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。(这也是HashSet如何保证元素不重复的原理)<br />**简而言之,在集合查找时,使用哈希码能大大降低对象比较次数,提高查找效率!**
P.S.这里就补充一下知识点
- 1.HashSet原理
- 我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
- 当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象
- 如果没有哈希值相同的对象就直接存入集合
- 如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
- 2.将对象存入HashSet去重复
- 类中必须重写hashCode()和equals()方法(JDK中的String类等等无需做此操作,因为已经重写了,自定义对象需要自己手动重写)
- hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)
- equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储
六、关于hashCode()方法三个约定的详细解释
最后写了这么多,我们来解释一下hashCode的三个约定,通过上面那些相信大家也知道了为什么这么约定
- 只要在Java应用程序执行期间在同一对象上多次调用它,
hashCode方法就必须一致地返回相同的整数,前提是不修改该对象的equals比较中使用的信息。 从一个应用程序的一次执行到同一应用程序的另一次执行,此整数不必保持一致。- 如果根据
equals(Object)方法两个对象相等,则在两个对象中的每个对象上调用hashCode方法必须产生相同的整数结果。- 不要求如果两个对象根据
equals(java.lang.Object)方法不相等,那么在两个对象中的每个对象上调用hashCode方法必须产生不同的整数结果。 但是,开发者应该意识到,为不等对象生成不同的整数结果可能会提高哈希表的性能。
关于第一点,这是**hashCode()方法的特性,这也是最基本的性质,这个就不需要解释了,上面的文章已经说的很清楚了。**
关于第二点,相等(相同)的对象必须具有相等的哈希码(或者散列码),为什么?
想象一下,假如两个Java对象A和B,A和B相等(eqauls结果为true),但A和B的哈希码不同,则A和B存入HashSet(HashMap等)时的哈希码计算得到的HashSet(HashMap等)内部数组位置索引可能不同,那么A和B很有可能允许同时存入HashSet(HashMap等),显然相等/相同的元素是不允许同时存入HashSet(HashMap等),HashSet(HashMap等)不允许存放重复元素。
例如:
public class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return age == person.age &&Objects.equals(name, person.name);}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}}
在main方法中
public class Demo1_HashSet {public static void main(String[] args) {Person p1 = new Person("张三",23);Person p2 = new Person("张三",23);HashSet<Person> hs = new HashSet<Person>();hs.add(p1);hs.add(p2);boolean b = p1.equals(p2);System.out.println(b);System.out.println(p1.hashCode());System.out.println(p2.hashCode());System.out.println(hs);}}
运行结果为,可以明显看到相等(相同)的对象如果不具有相等的哈希码(或者散列码),那么这种HashSet中就存在了相同元素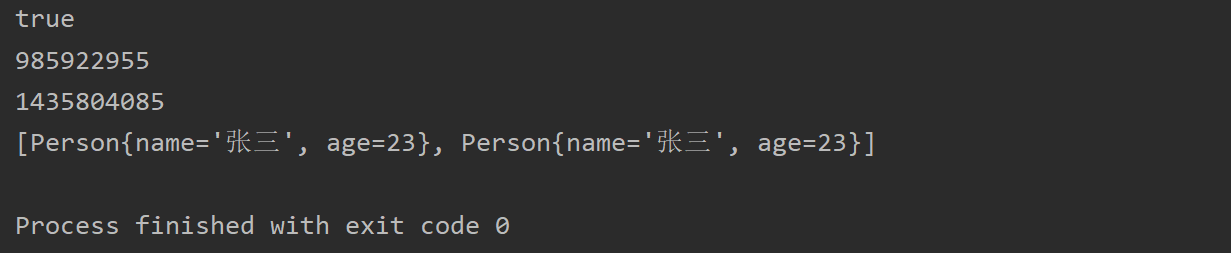
那么问题来了,是如何保证相等(相同)的对象必须具有相等的哈希码(或者散列码),做法就是重写equals方法的同时也重写hashCode方法,对于JDK已经封装好的类,如String类,已经帮我们做好了,而我们做的就是针对自定义类进行equals和hashCode的同时重写。让他们相互协作达到目的。代码如下,还是以Person类为例:
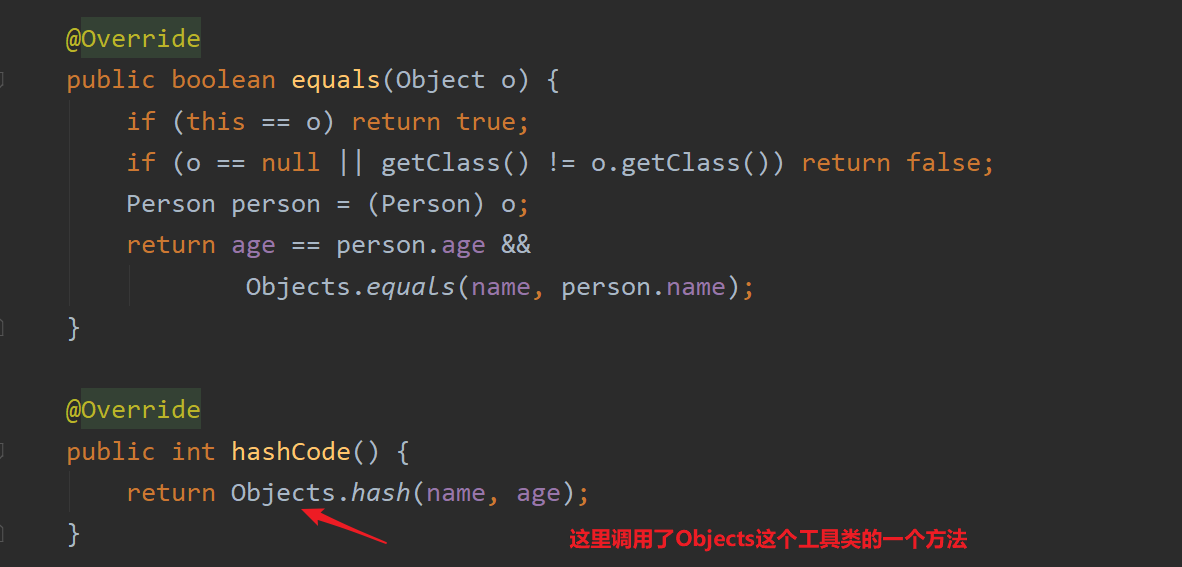
这里我们把关注点放在hashCode方法上,看它如何保证两个内容相等的对象的哈希码相同,这里调用了Objects这个工具类的hash方法,把该Person对象的属性值传递了进去,我们进去查看一下它又是如何实现。

这里在Objects工具类的hash方法又调用了另外一个工具类Arrays的hashCode方法,可变参数接收了Objects类hash方法传过来的值,继续点进去查看。
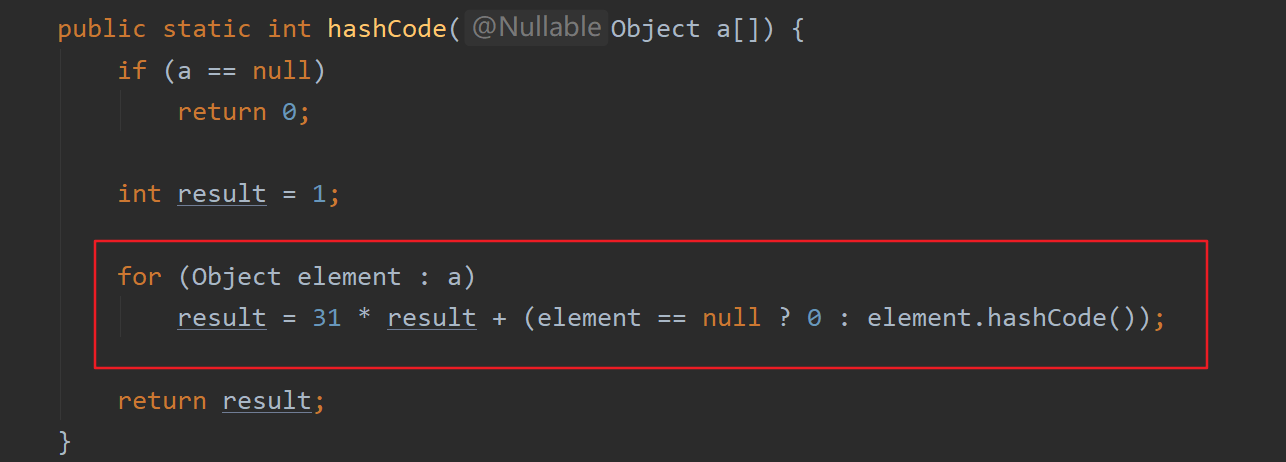
这里我们终于看到了这个最终实现过程,发现是不是跟之前String类重写的hashCode方法有异曲同工之处,就是根据输进来的参数生成一个值,而这个值的大小取决于这些参数,既然我们知道取决于参数,那么传进来的参数值一样,那么结果肯定是一样的,所以这就是为什么两个内容相等的对象哈希码是一样的。
关于第三点,两个对象的hashCode相同,它们并不一定相同
也就是说,不同对象的hashCode可能相同;假如两个Java对象A和B,A和B不相等(eqauls结果为false),但A和B的哈希码相等,将A和B都存入HashSet(HashMap等)时会发生哈希冲突,也就是A和B存放在HashSet(HashMap等)内部数组的位置索引相同这时HashMap会在该位置建立一个链接表,将A和B串起来放在该位置,显然,该情况不违反HashSet(HashMap等)的使用原则,是允许的。当然,哈希冲突越少越好,尽量采用好的哈希算法以避免哈希冲突。减少哈希冲突这是可以提高效率的地方。
七、关于equals()和hashCode()方法的一些解答
有人会说,可以直接根据哈希码判断两个对象是否相等吗?肯定是不可以的,因为不同的对象可能会生成相同的哈希码。虽然不能根据哈希码判断两个对象是否相等,但是可以直接根据hashcode值判断两个对象不等,如果两个对象的哈希码不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。
也就是说对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同。
如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;如果两个对象的hashcode值相等,则equals方法得到的结果未知。
重写equals()和hashcode()小结:
- 重点是equals,重写hashCode只是技术要求。(为了提高效率)
- 为什么要重写equals呢?因为在java的集合框架中,是通过equals来判断两个对象是否相等的。
- 在hibernate中,经常使用Set集合来保存相关对象,而Set集合是不允许重复的。在向HashSet集合中添加元素时,只重写equals()方法是不行的,因为上面第六部分的那个hashCode约束说的非常清楚了,也指明了会出现什么错误。
- 另外当然也并不是一定要重写equals一定重写hashCode方法(不过这样做风险很大,因为你不知道什么时候会把对象丢到散列表中去,没用到散列表的地方可以不一定必须要重写),比如在List这类集合中,删除重复对象元素(主要指自定义对象),也要重写equals方法,因为contains和remove源码方法都是靠equals方法来实现的。但是这里不一定要重写hashCode方法。
P.S.像HashSet,HashMap,HashTable等等之类保证存储对象元素单一性的根本就是使用了哈希算法
_
八、原理浅谈
HashSet,HashMap,HashTable存储元素实现原理 HashSet底层实现本质上就是靠HashMap,HashTable我们就当跟HashTable一样
Collection接口下的Set接口下的Hashset类调用add方法来实现存储
所以接下里我们以Map接口实现类的HashMap来讲解原理
put方法里面调用了putVal方法,里面传了三个参数,第一个是通过hash方法生成的哈希值,第二个是键,第三个是值。
这里的hash方法就是我们通常所说的哈希算法,对于哈希算法和哈希值的生成,美团技术团队的一篇文章写得特别好,下面就引用他们的话:
HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表,大大优化了查询的效率。HashMap定位数组索引位置,直接决定了hash方法的离散性能。先看看源码的实现(方法一+方法二):
所以看来Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
对于任意给定的对象,只要它的hashCode()返回值相同,那么程序调用方法一所计算得到的Hash码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,在HashMap中是这样做的:调用方法二来计算该对象应该保存在table数组的哪个索引处。
这个方法非常巧妙,它通过h & (table.length -1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
另外我们注意到hash方法调用了hashCode方法,这个也就是为什么要一般要重写的hashCode方法的原因,这里key就是我们传入的对象或者叫存储的对象。因为如果是自定义对象没重写覆盖的话,hashCode方式就是object类的方法。随之而来的肯定也是重写equals方法。
我们通过Hash算法生成相应的哈希值,再根据key的哈希值得到一个数组索引,然后根据索引找到链表表头结点,之后进行一系列操作将元素(这里主要是值键值对对象)决定是否存进去。存在哈希冲突就根据equals判断对象(键)是否相等,相等则不存(替换值)。前者针对HashSet,后者针对HashMap;如果不相等的话,那就存在链表后面。
简而言之就是三种情况:
- 哈希值相等,对象相等,不存
- 哈希值相等,但是对象不相等,则存入节点后面形成链表
- 哈希值不相等,那就肯定不是同一个对象,存入

下面是putVal具体实现过程
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}

若有收获,就点个赞吧
0 人点赞
