- 第一章 本周介绍
- 第二章 脚手架开发入门
- 2-4 脚手架原理讲解(上)
- 2-5 脚手架原理讲解(下)
- 2-6 脚手架开发流程和难点解析
- 2-7 快速入门第一个脚手架
- 2-8 脚手架本地调试方法
- 2-9 脚手架本地调试标准流程总结
- 2-10 脚手架命令注册和参数解析
- 2-11 脚手架项目发布
- 第三章 脚手架框架搭建
- 3-5 Lerna核心操作
- 3-6 Lerna发布流程(lerna使用总结)
- 第四章 Lerna源码解析
- 4-1 赚回学费:武装简历、升职加薪
- 4-2 lerna源码结构分析和调试技巧
- 4-3 Node源码调试过程中必会的小技巧
- 4-4 lerna初始化过程源码详细分析
- 4-5 【高能知识点】npm项目本地依赖引用方法
- 4-6 脚手架框架yargs快速入门
- 4-7 yargs高级用法讲解
- 4-8 lerna脚手架初始化过程超详细讲解
- 4-9 lerna脚手架Command执行过程详解
- 4-10 【关键知识复习】javascript事件循环—EventLoop
- 4-11 import-local执行流程深度分析
- 4-12 pkg-dir源码解析(一大波优秀的文件操作库)
- 4-13 resolve-from源码解析(彻底搞懂node_modules模块加载逻辑)
- 4-14 Node模块加载核心方法_resovleFileName源码深入解析
- 4-15 fs模块toRealPath源码深入解析
- 4-16 讲一个高难度的正则表达式(想挑战的点进来)
- 4-17 大招:如何快速拿到面试“一血”
第一章 本周介绍
1-1 确立本周目标
- 脚手架的实现原理、调试原理
- Lerna的常见用法、源码分析
- 架构设计技巧和架构图绘制方法
- Node的module模块分析
- yargs使用方法
- 剖析Lerna架构设计
1-2 前端研发脚手架imooc-cli核心功能演示
- 安装imooc-cli脚手架: npm i -g @imooc-cli/core
- 查看脚手架相关内容: **imooc-cli**
- 通过脚手架新建项目: imooc-cli init
- 项目发布到测试环境: imooc-cli publish
- 项目发布到正式环境: imooc-cli publish —prod
1-3 脚手架在课程中的定位
- 本项目中基础项目均由脚手架管理
- 技术简历突出
- 提高技能
第二章 脚手架开发入门
2-1 本章知识脉络和难点解析
- 分析开发脚手架的必要性
- 从使用角度去理解什么是脚手架
- 脚手架的实现原理(与操作系统关联)
- 脚手架的开发流程
2-2 站在前端研发的视角,分析开发脚手架的必要性
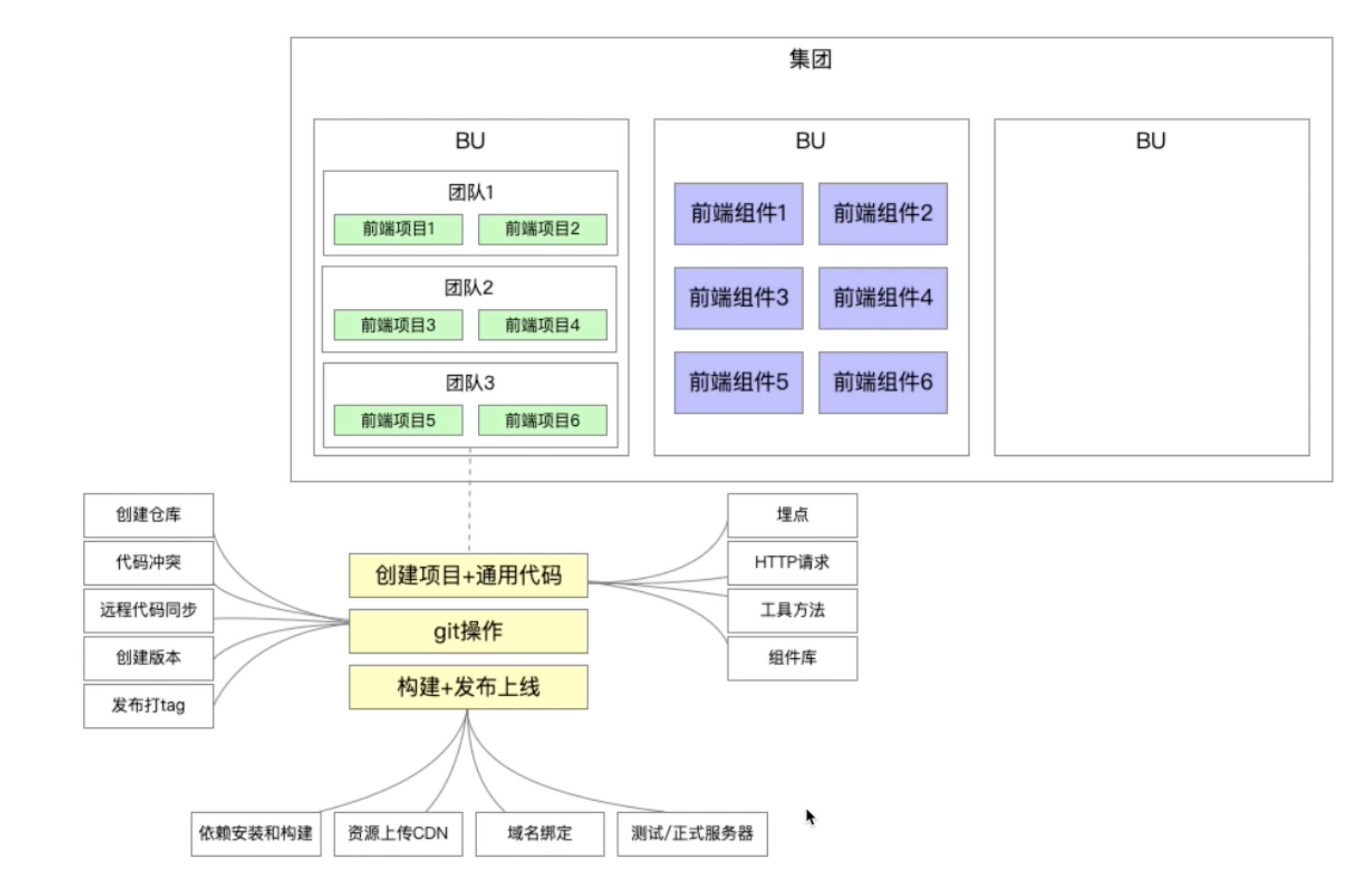
- 开发imooc-cli脚手架的核心目标:提升前端研发效能【提炼通用代码、通用流程、构建发布上线】
- 脚手架核心价值:自动化、标准化、数据化
和自动化构建工具(jenkins、travia)区别:自动化构建工具在服务端执行,无法覆盖本地操作且定制自动化的构建工具需要用到Java等后端语言,对前端不友好。
2-3 从使用角度理解什么是脚手架?
- 脚手架简介:脚手架的本质是一个操作系统的客户端,通过命令行执行。
- 脚手架执行原理:
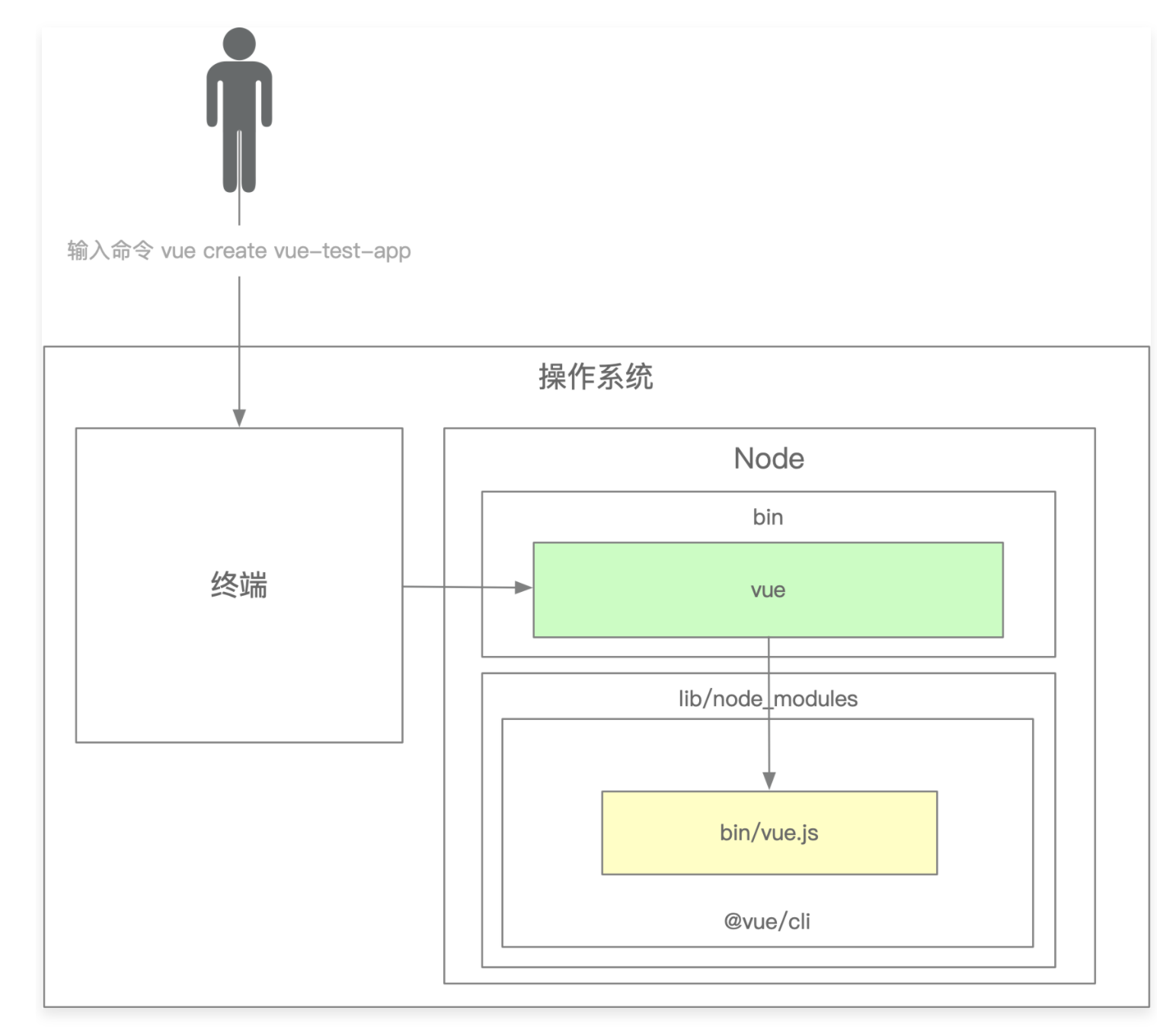
- 从应用角度看vue-cli开发脚手架过程:
- 首先是个npm项目,项目中有一个bin/vue.js的文件,且这个项目发布到了npm上
- 将npm项目安装到了lib/node_modules
- 在node的bin目录下配置软链接到lib/node_modules/@vue/cli/bin/vue.js
脚手架执行原理解析:
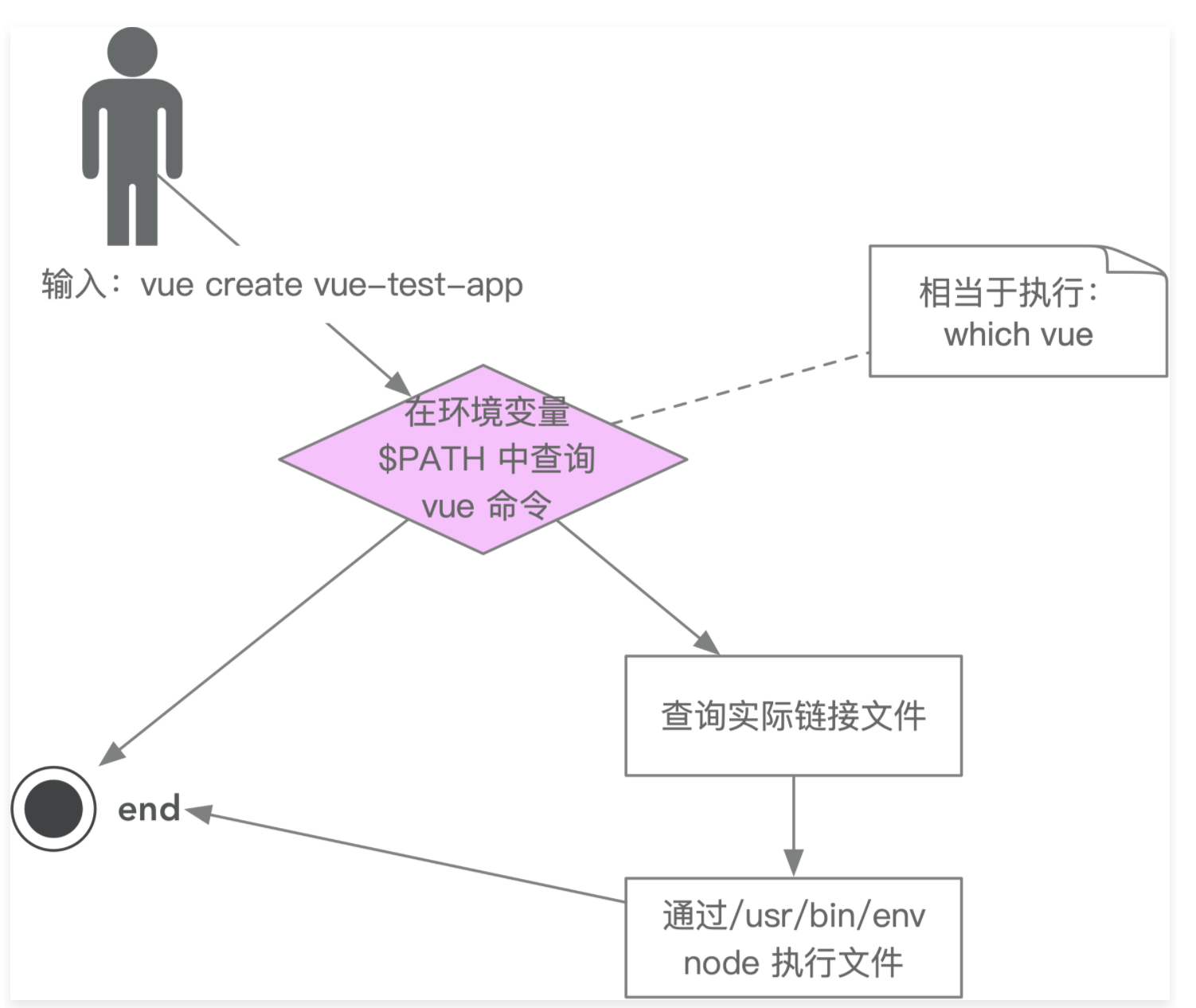
在终端输入:vue create vue-test-app
- 终端解析vue命令【通过which vue查找vue】
- 根据vue命令链接到实际的vue.js文件
- 终端使用node执行vue.js文件
- vue.js文件解析command/options
- vue.js文件执行command
- 执行完毕,退出执行
2-4 脚手架原理讲解(上)
问题一:为什么全局安装@vue/cli后,我们执行的命令为 vue呢?
答:这是因为通过which vue后我们会看到vue所在目录,而这个vue是一个软链接,指向的是@vue/cli。确定这个vue命令名称的是在
node/v12.16.1/lib/node_modules/@vue/cli目录下package.json中的bin的键值。
问题二:全局安装@vue/cli时发生了什么?
答:执行 npm install -g @vue/cli的时候,首先node会把我们当前包下载到node下的node_modules中去。下载完成后,会在下载好的包中查找package.json中是否有bin,如果有,会通过package.json中的bin中的键去配置软链接。
上面两个问题其实问题二在前,问题一在后,两个问题说的是一个流程的双向解释,理解了问题二,问题一就清楚了。
问题三:执行vue命令时发生了什么?为什么vue指向一个js文件,我们却可以通过vue命令执行它?
答:首先执行vue命令,与执行which vue打印出来的地址 效果是等价的(即执行的是which vue的那个软连接:/Users/liumingzhou/.nvm/versions/node/v12.16.1/bin/vue)。 而软连接又指向它的实际文件存在路径(../lib/node_modules/@vue/cli/bin/vue.js)。
我们知道,一个test.js文件可以通过node执行,但不能单独执行,这是因为它没有可执行权限。 我们在/Users/liumingzhou/Desktop目录下新建一个test.js文件,我们可以给这个js文件一个执行权限:chmod 777 test.js 然后在命令行直接输入 ./test.js仍然不可以执行。这是因为js文件需要一个解释器来进行执行,这个node就是一个解释器。(.py文件需要 python解释器执行,.java文件需要java解释器进行执行)。
那么我们上面的vue.js文件是怎么执行的呢? 通过查看vue.js文件源码,我们发现第一行代码是这样的:#!/usr/bin/env node 这行代码的意思是:告诉我们的操作系统,直接调用这个文件的时候,到环境变量中查找node命令执行。 (/usr/bin/env 是我们的环境变量)
然后,我们在我们的test.js文件中第一行加入这行代码 #!/usr/bin/env node 直接输入 ./test.js 即可执行这个js文件。
接着,我们不想用 ./test.js这样的方式执行js文件,我们想通过一个命令,比如 liugezhou 这个命令来执行这个test.js文件,我们需要怎么做呢? 第一种方式,我们去找环境变量,通过 echo $PATH
首先,我们创建一个环境变量: cd /Users/liumingzhou/.nvm/versions/node/v12.16.1/bin 创建软连接:ln -s /Users/liumingzhou/Desktop/test.js liugezhou 创建完毕后,就可以看到一个liugezhou软连接,我们在任何目录执行liugezhou就可以执行test.js文件了。
2-5 脚手架原理讲解(下)
问题一:为什么说脚手架本质是操作系统的客户端?它和我们在PC上安装的应用/软件有什么区别
脚手架执行起来的本质是靠node这个命令,node是一个操作系统客户端,而test.js 这个文件仅仅是作为一个参数注入到node命令中。node本质上是一个可执行文件(在window操作系统中可以看到node的扩展名为.exe的)。 本质来说没有区别。区别仅仅是安装的应用软件会提供一个GUI,而node并没有提供GUI
问题二:如何为node脚手架命令创建别名
方法一:即为上文提到的创建一个软连接。 接着,我们希望继续为上文提到的 liugezhou 软连接继续添加一个别名,我们需要这么做 在上文的bin目录下,执行命令 ln -s ./liugezhou liugezhou2 即 软连接可以嵌套。
问题三:描述脚手架命令执行的全过程
2-6 脚手架开发流程和难点解析
通过以上分析,我们大致了解一个脚手架的开发流程如下:
- 创建一个npm项目
- 创建脚手架的入口文件,且入口文件需要添加代码:#!/usr/bin/env node
- 配置package.json文件,添加bin属性(指定脚手架命令与地址)
- 编写脚手架代码
- 将脚手架发布到npm
使用流程:
- 安装脚手架: npm install - g your-own-cli
- 使用脚手架: your-own-cli
脚手架开发难点:
- 脚手架开发过程中通常需要将复杂的系统拆分为多个模块(分包)
- 脚手架开发过程中需要注册一系列的命令。如何对命令进行注册是一个重要的环节
- 需要对参数进行解析: [vue command [options]
] - 帮助文档:global[主命令]
………… 命令行交互、日志打印、命令行文字变色、网络通信 HTTP/WebSocket、文件处理等。
2-7 快速入门第一个脚手架
通过上节流程,我们本节快速开发一个liugezhou-test脚手架并发布,流程如下:
- cd /Users/liumingzhou/Desktop
- mkdir liugezhou-test
- cd liugezhou-test
- npm init -y
- 终端打开liugezhou-test项目:新建lib目录,lib目录下新建index.js文件(index.js文件内容如下)
- 修改package.json文件,添加 “bin”:{“liugezhou-test”:”lib/index.js”}
- npm publish 发布npm包
- 下载安装:npm i -g liugezhou-test
- 测试:liugezhou-test
#!/usr/bin/env nodeconsole.log('welcome liugezhou-test')
这里注意一点,在npm publish的时候,如果是在Descktop目录下执行的,那么我们下载liugezhou-test包之后,会看到软链指向的是本地,这是因为npm为了我们本地调试:如果/Desktop目录下有这个包,会指向本地。
2-8 脚手架本地调试方法
方式一:如上文所说,直接在Desktop目录下执行:npm install -g liugezhou-test,即调试本地包。 (移除本地安装的包:npm remove -g liugezhou-test)
方式二:直接在liugezhou-test文件目录下,执行:npm link,软链指向的node_modules源文件指向本地包。
分包情况下,如何调试本地包?
如果/Desktop/liugezhou-test要使用/Desktop/lilugezhou-test/lib包下的方法,如何做呢?
- 在/Desktop/liugezhou-test/lib目录下,npm link
- 在/Desktop/liugezhou-test/目录下,npm link liugezhou-test-lib
2-9 脚手架本地调试标准流程总结
链接本地脚手架
- cd your-cli-dir
- npm link
链接本地库文件
- cd your-lib-dir
- npm link
- cd your-cli-dir
- npm link your-lib-dir
取消链接本地库文件
- cd your-lib-dir
- npm unlink
- cd your-cli-dir
- npm unlink your-lib-dir #link存在
- rm -rf node_modules # link不存在
- npm i -S your-lib-dir
理解 npm link
- npm link : 将当前项目链接到node全局node_modules中作为一个库文件,并解析bin配置创建可执行文件。
- npm link your-libr:将当前项目中node_modules下指定的库文件链接到node全局node_modules下的库文件
理解 npm unlink
- npm unlink:将当前项目从node全局node_modules中移除
- npm unlink your-lib:将当前项目中的库文件依赖删除。
2-10 脚手架命令注册和参数解析
process是node的内置库 我们在index.js中写代码: console.log(require(‘process’))
通过命令行执行 liugezhou-test init 会看到process有许许多多个属性,其中有一个argv属性。 通过分析这个argv属性,我们就看到了init这个属性。
因此我们可以通过argv来判断是否输入了 init 这个命令。
2-11 脚手架项目发布
老生常谈,npm publish 通过判断argv输入的参数,在liugezhou-test-lib中与liugezhou-test中加入相关逻辑 实现 liugezhou-test init 与 liugezhou -V的输出显示 然后分别发布,remove掉本地链接。
第三章 脚手架框架搭建
3-1 本章的收获是什么,难点是什么?
本节课程非常下饭:
收获一:Lerna简介 [Lerna管理的项目有:babel、create-reat-app、vue-cli]
通过学习lerna将学会如何管理一个复杂的Javascript项目
- 收获二:Lerna源码分析:讲解源码结构、执行流程、源码精读
- 收获三:基于lerna设计简历。
3-2 原生脚手架开发痛点分析
lerna设计源于其要解决的问题,首先我们要分析写原生脚手架开发的痛点:
- 痛点一:重复操作
- 多Package本地link
- 多Package依赖安装
- 多Package单元测试
- 多Package代码提交
- 多Package代码发布
- 版本一致性
- 发布时版本一致性
- 发布后相互依赖版本升级
3-3 本章重点:lerna简介及脚手架开发流程
Lerna简介
Lerna : A tool for managing JavaScript projects with multiple packages. 用于管理具有多个程序包的JavaScript项目的工具。
Lerna : Lerna is a tool that optimizes the workflow around managing multi-package repositories with git and npm. Lerna是一个基于 git+npm 的优化工作流的多package项目的管理工具。
优势
- 大幅减少重复操作
- 提升操作的标准化
Lerna 是架构优化的产物,它揭示了一个架构真理:项目复杂度提升后,就需要对项目进行架构优化。架构优化的主要目标往往都是以效能为核心。 lerna官网:https://lerna.js.org/
Lerna开发脚手架流程 ⭐️⭐️⭐️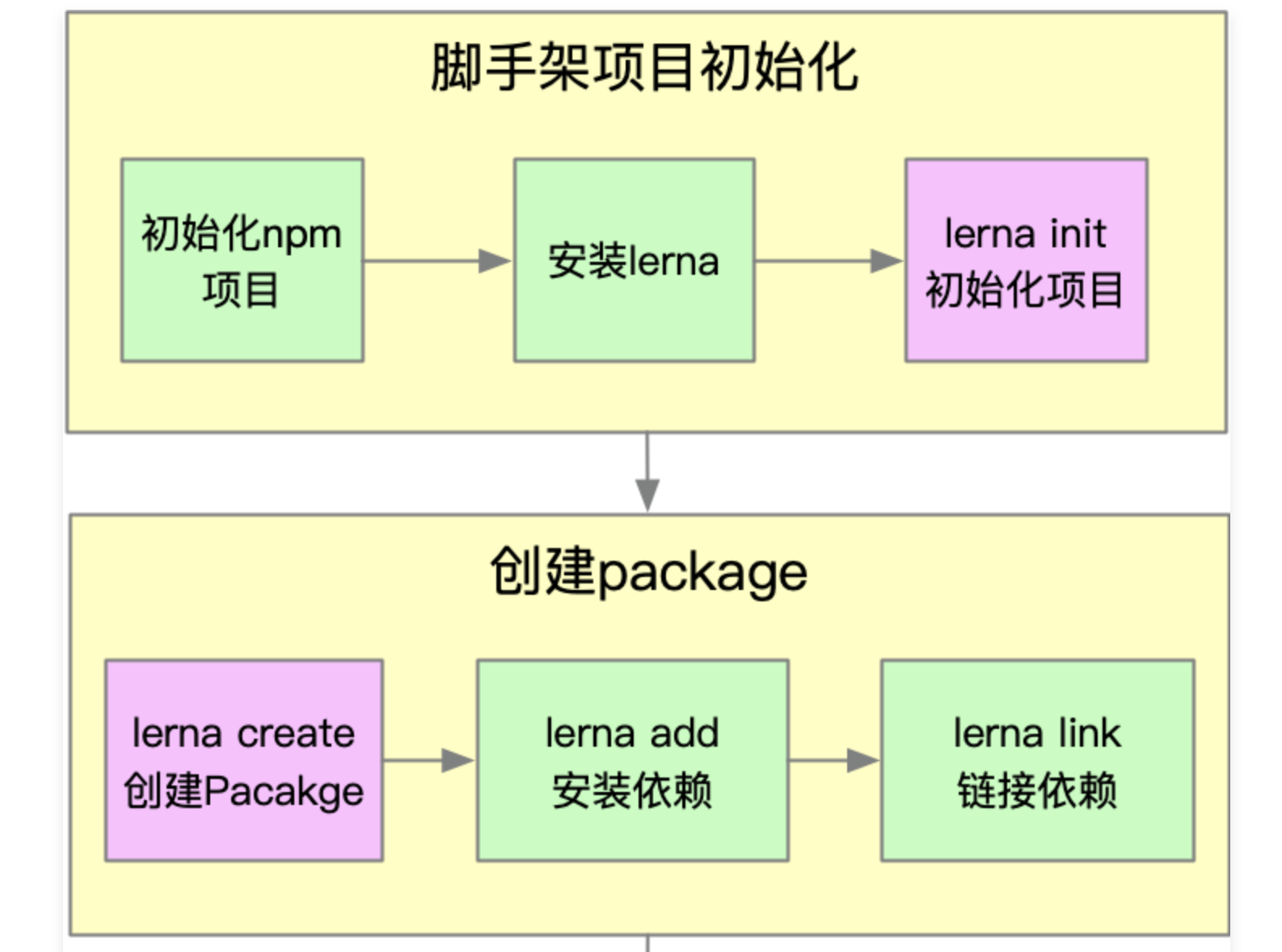
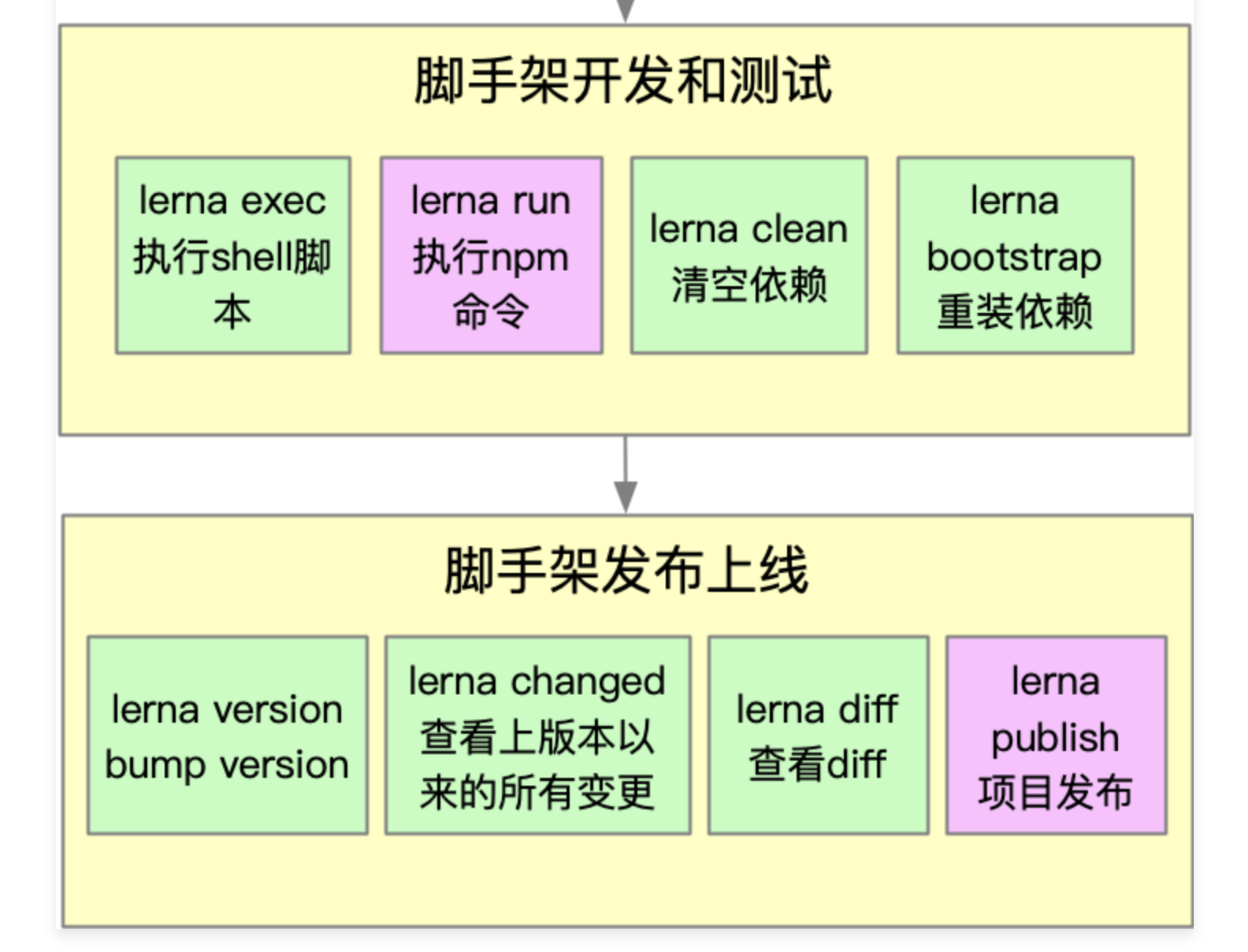
3-4 基于lerna搭建脚手架框架
本节使用命令依次如下
- mkdir liugezhou-cli-dev
- cd liugezhou-cli-dev
- npm init -y
- npm i -g lerna【全局安装】
npm i -S lerna
lerna init
- lerna create core
- lerna create utils
3-5 Lerna核心操作
本节使用命令依次如下:
lerna add liugezhou-test (在packages目录下所有包中安装liugezhou-test包)
lerna add liugezhou-test packages/core (在指定包core中添加依赖)
lerna clean (清除packages目录下的依赖)
lerna bootstrap (将刚清除的所有依赖,重新安装)
lerna link (开发的版本互相存在依赖,可用此命令完成)
lerna exec —
[…args] lerna exec — rm -rf node_modules 删除packages目录下的所有node_modules文件夹 lerna exec —scope @liugezhou-cli/utils—rm -rf node_modules 删除packages目录下utils的。。。。 【上下文为packages目录】
lerna run test
- lerna run —scope @liugezhou-cli/core test [执行core包package.json中script标签的test属性]
3-6 Lerna发布流程(lerna使用总结)
lerna init会自动完成 git 初始化,但不会创建 .gitignore,这个必须要手动添加,否则会将 node_modules 目录都上传到 git
lerna add:第一个参数:添加npm包名 第二个参数:本地package的路径(如果不加,则全部安装) 可选参数:—dev:将依赖安装到devDependencies,不加时安装到dependencies
lerna link如果未发布上线,需要手动添加到package.json中再执行。
lerna clean只会删除 node_modules,不会删除package.json中的依赖
lerna exec 和 lerna run—scope属性后添加的是包名,不是package的路径,这点和 lerna add 不同
lerna publish
- 发布时会自动执行 git add package-lock.json,所以该文件不能加入到.gitignore中去。
- 发布时先创建远程仓库,且push代码。
- 执行npm publish前完成 npm login
- 如果发布的包名为 @xxxx/yyy 的格式,需要现在npmjs.org上注册organization
- 发布到npm group时默认为private,package.json中需手动添加配置:
"publishConfig": { "access": "public"}
第四章 Lerna源码解析
4-1 赚回学费:武装简历、升职加薪
为什么要做源码解析:赚回学费、走上人生巅峰
- 自我成长、提升编码能力和技术深度的需要
- 为我所用,应用到实际开发,实际产生效益
- 学习借鉴,站在巨人的肩膀上,登高望远
为什么要分析Lerna源码
- 2W+ star的明星项目
- Lerna是脚手架,对我们开发脚手架有借鉴意义
- Lerna项目中蕴含大量的最佳实践,值得深入研究和学习
学习目标
- Lerna源码结构和执行流程分析
- import-local源码深度精读
学习收获
- 如何将源码分析写进简历
- 学习明星项目的架构设计
- 获得脚手架执行流程的一种实现思路
- 获得脚手架调试本地源码的另一种方式
- Node.js加载node_modules模块的流程 ✨✨✨✨✨
- 各种文件操作算法和最佳实践
4-2 lerna源码结构分析和调试技巧
- github下载lerna源码到本地且安装依赖!
- 使用webstorm打开源码,找到入口文件—package.json中的bin属性。
- webstorm添加调试:Edit Configurations,这里需要在Configuration中添加
node parameters
这里遇到一个问题,代码调试的时候,Variables窗口内没内容。
4-3 Node源码调试过程中必会的小技巧
- WebStorm -> Preferences… -> 搜索 Node.js and NPM -> 勾选 Coding assistance for Node.js
这个目的是:对当前项目中的一些默认库或内置库做一些高亮,使得node提供的一些库文件可以进行跳转。
- 搜索 Debugger -> Stepping -> 默认勾选的都取消掉
这个目的是在调试的时候,取消勾选就可以进去一些库文件查看源码
4-4 lerna初始化过程源码详细分析
通过前面分析,我们知道,入口文件为:lerna/core/lerna/cli.js文件,从这里开始看源码:
require(“.”)(process.argv.slice(2));
- require(‘.’):这里的
.是相对路径,相当于是 require(‘./index.js)- 到这行代码后,先加载与该cli.js同级别目录下的index.js文件。
- 等文件加载完毕后,将process.argv.slice(2)参数, 也就是我们写入的参数,传入到 index.js文件中module.exports出来的方法 main
4-5 【高能知识点】npm项目本地依赖引用方法
本地依赖的最佳实践:引用本地包的方式可以使用 file的方式,这是因为lerna publish的时候可以在线上环境把fiel的方式改成引用线上包的方式。大概是个这么个意思。这种方式可以去除之前使用 npm link的方式。
理解了这里本地依赖的file引用后,回到之前的3-6 lerna-publish发布流程项目,将本地引用的@cloudscope-cli/utils改为file引用,这里需要注意:在@cloudscope-cli/core中使用file方式引用了本地的utils包后,需要npm install一下。
4-6 脚手架框架yargs快速入门
首先在npmjs官网搜索yargs,看一下基本使用情况,然后开始我们的学习:
在某目录下,新建一个空的项目,具体操作如下:
mkdir liugezhou-test npm init -y 新建lib/index.js package.json文件添加 “bin”:”lib/index.js” npm install -S yarns npm install -S dedent
然后,开始编辑index.js文件,进行yargs相关用法的学习: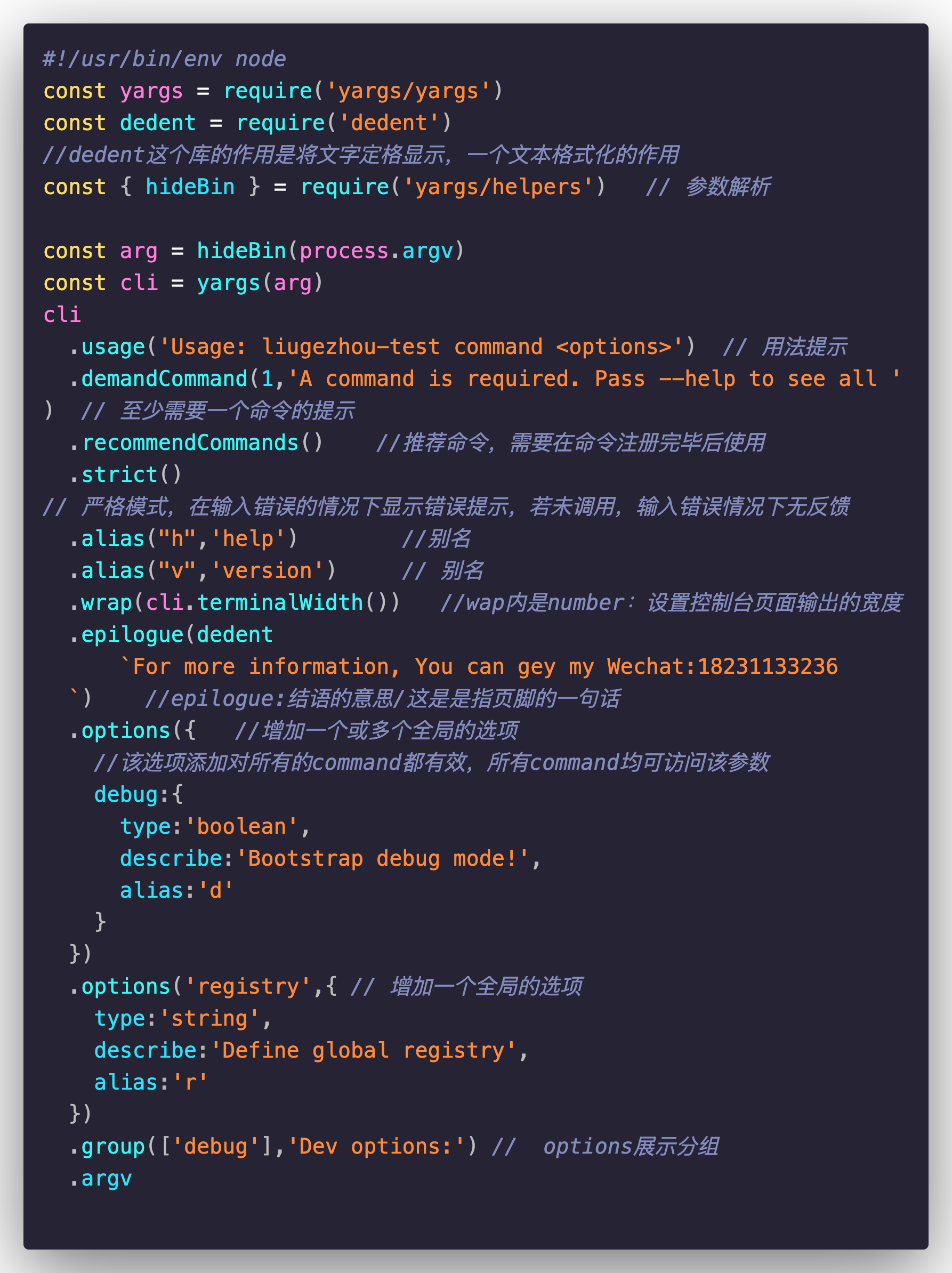
4-7 yargs高级用法讲解
关于yargs的command用法,我们从npmjs官网,看到示例如下:
通过以上代码,我们可以看到定义command的时候,传入了四个参数:
- ‘serve [port]’: command的格式,port为我们自定义的option,相当于 liugezhou-test serve
- ‘start the serve’:关于此serve command命令的补充描述
- 第三个参数为builder函数:在执行此command具体命令之前做的动作,比如上文为serve这个命令定义了一个参数 port,且给定port的默认值为5000
- 第四个参数我们叫做handler:是用来具体执行command的一个行为
在对上面demo有个简单了解后,回到我们上一节的代码中,继续添加command定义: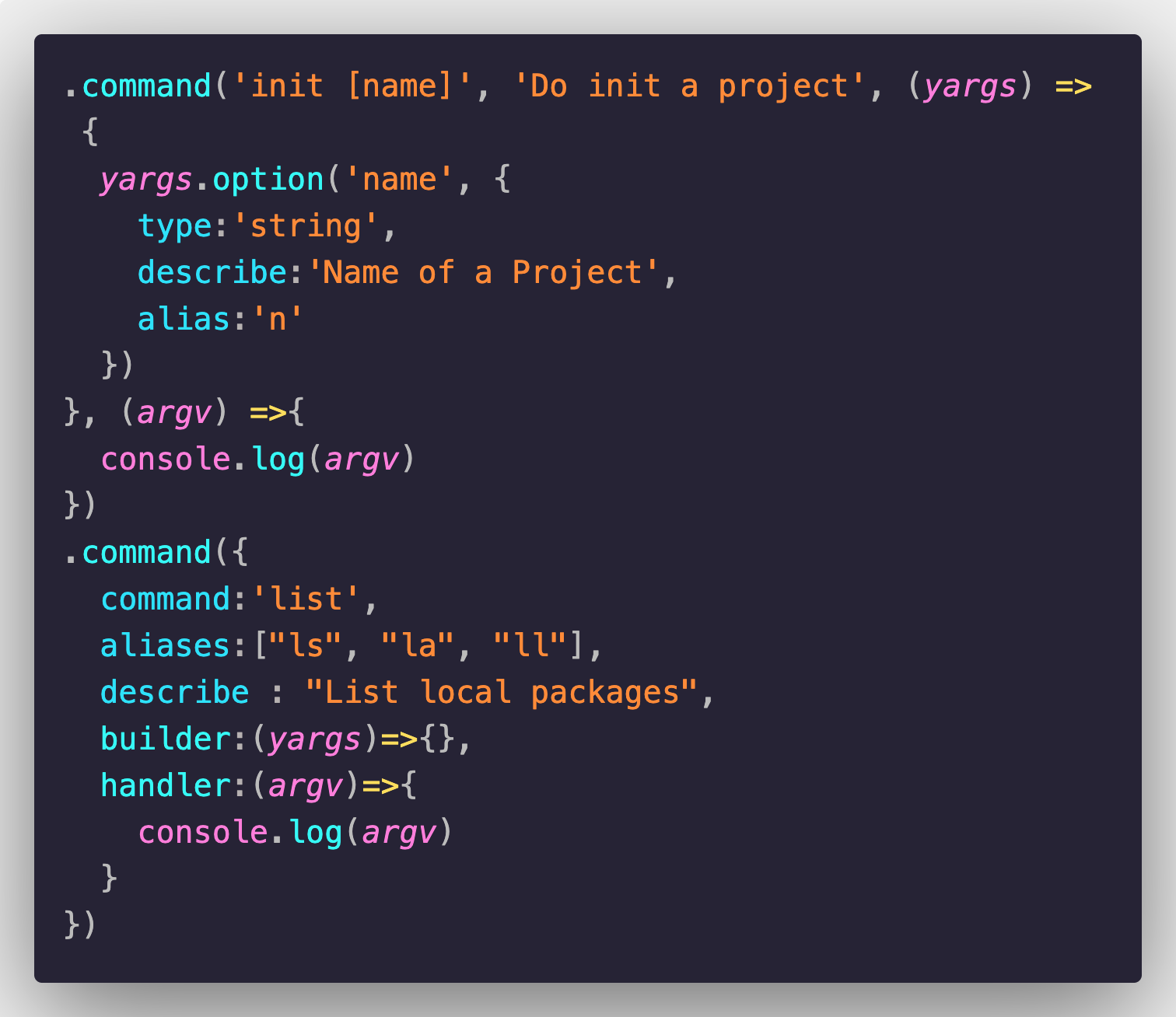
4-8 lerna脚手架初始化过程超详细讲解
通过 4-6、4-7两节内容,分析lerna脚手架的初始化过程讲解。
4-9 lerna脚手架Command执行过程详解
大致流程了解,未画流程图。
4-10 【关键知识复习】javascript事件循环—EventLoop
- EventLoop中存在两种事件:宏任务(MacroTask)和微任务(MicroTask)
- JavaScript脚本中加入到宏任务中去
- 当宏任务队列中任务执行完毕后,会将微任务队列中任务清空,清空之后再去执行宏任务队列。这种循环往复的执行流程就称为事件循环—EventLoop。
- 然后:我们在宏任务中加入一个setTimeout。
- 接着,我们在宏任务队列中加入一个 Promise.then() , Promise.then()中的内容会被加入到微任务队列中去。
4-11 import-local执行流程深度分析
import-local的作用是:当我们的项目当中本地存在一个脚手架命令,同时全局在node当中也存在一个脚手架命令的时候,优先选用本地的node_modules中的版本。
在执行一个node代码的时候,默认会向node代码当中注入一些变量:filename 、 dirname 、 require 、 module、exports.
首先,执行lerna命令的时候,会执行node全局下的lerna,即which lerna 指向的: 软连接:/Users/liumingzhou/.nvm/versions/node/v12.16.1, 实际指向:/Users/liumingzhou/.nvm/versions/node/v12.16.1/lib/node_modules/lerna/cli.js
[PRATIC]然后,在webstorm的debug调试中,Node parameters修改为
[PRATIC]地址。 接着,点击调试按钮,我们知道,程序首先进入的文件是[PRATIC]
#!/usr/bin/env node"use strict";/* eslint-disable import/no-dynamic-require, global-require */const importLocal = require("import-local");if (importLocal(__filename)) {require("npmlog").info("cli", "using local version of lerna");} else {require(".")(process.argv.slice(2));}
通过上面分析我们知道了执行流程,现在的重点就是看代码中的 require(‘import-local’)中的源码。
我们进入到import-local源码中:
'use strict';const path = require('path');const resolveCwd = require('resolve-cwd');const pkgDir = require('pkg-dir');module.exports = filename => {const globalDir = pkgDir.sync(path.dirname(filename));const relativePath = path.relative(globalDir, filename);const pkg = require(path.join(globalDir, 'package.json'));const localFile = resolveCwd.silent(path.join(pkg.name, relativePath));return localFile && path.relative(localFile, filename) !== '' ? require(localFile) : null;};
path.dirname(filename):这句代码的意思是获取到文件filename的上级目录。
4-12 pkg-dir源码解析(一大波优秀的文件操作库)
本节分析上面代码,对import-local源码细节分析,本节分析代码流程为globalDir是如何获得的:
const pkgDir = require(‘pkg-dir’) pkg-dir:字面意思为,获得package.json文件的上级目录
进入 pkg-dir源码:
'use strict';const path = require('path');const findUp = require('find-up');module.exports = cwd => findUp('package.json', {cwd}).then(fp => fp ? path.dirname(fp) : null);module.exports.sync = cwd => {const fp = findUp.sync('package.json', {cwd});return fp ? path.dirname(fp) : null;};
我们分析pkg-dir代码可知:pkg-dir这个库向我们暴露了两个方法:默认cwd和sync方法,其中sync方法会以同步的方式执行。
同时,这里又引用find-up这个库
'use strict';const path = require('path');const locatePath = require('locate-path');module.exports = (filename, opts = {}) => {const startDir = path.resolve(opts.cwd || '');const {root} = path.parse(startDir);const filenames = [].concat(filename);return new Promise(resolve => {(function find(dir) {locatePath(filenames, {cwd: dir}).then(file => {if (file) {resolve(path.join(dir, file));} else if (dir === root) {resolve(null);} else {find(path.dirname(dir));}});})(startDir);});};module.exports.sync = (filename, opts = {}) => {let dir = path.resolve(opts.cwd || '');const {root} = path.parse(dir);const filenames = [].concat(filename);// eslint-disable-next-line no-constant-conditionwhile (true) {const file = locatePath.sync(filenames, {cwd: dir});if (file) {return path.join(dir, file);}if (dir === root) {return null;}dir = path.dirname(dir);}};
同理,find-up这个库也是默认的module.exports方法与同步返回的sync方法。 这里我们继续分析find-up这个库的sync方法,一行一行代码解析:
let dir = path.resolve(opts.cwd || ‘’);
path.resolve是我node当中经常使用的方法,它主要作用是把两个相对路径进行结合。 path.resolve(‘/Users’,’/liumingzhou’),返回的路径为 /liumingzhou path.join(‘/Users’,’/liumingzhou’),返回的路径为 /Users/liumingzhou
这里有个注意点是path.resolve(‘.’)返回的是当前路径,而path.join(‘.’),返回的就是. 不会帮我们判定当前的 . 与上级路径的关系。
const {root} = path.parse(dir);
path.parse(“/Users/liumingzhou/Documents/imoocCourse/Web前端架构师/lerna/core”) 返回的结果为:
{
root:’/‘,
dir:’/Users/liumingzhou/Documents/imoocCourse/Web前端架构师/lerna/core’,
base:’lerna’,
ext:’’,
name:’lerna’
}
const filenames = [].concat(filename);
通过分析上下文,我们知道这行代码的filename指的是 package.json,于是filenames = [‘package.json’]
while (true) {}
这里是个无限循环,需要注意的一点是退出条件
const file = locatePath.sync(filenames, {cwd: dir});
这里又调用了这个locatePath这个库的sync方法,local-path这个库的作用是磁盘中是否存在这个路径,如果存在会把第一个文件返回。
...module.exports.sync = (iterable, options) => {options = Object.assign({cwd: process.cwd()}, options);for (const el of iterable) {if (pathExists.sync(path.resolve(options.cwd, el))) {return el;}}};
通过上面的代码,我们看到上面又用到了一个库:pathExists(通过名字我们显而易见的知道,这个库的作用是判断传入的一个路径是否存在的),pathExists这个库源码不贴了,主要的一行代码是:fs.accessSync(fp),这行代码就是判断是否能到达一个文件,如果报错就会被try catch捕获返回false
if (file) {
return path.join(dir, file);
}通过前面分析 path.join(dir, file)返回的就是 /Users/liumingzhou/Documents/imoocCourse/Web前端架构师/lerna/core/lerna/package.json
最终获得globalDir!
4-13 resolve-from源码解析(彻底搞懂node_modules模块加载逻辑)
我们回到import-local源码,继续看
const relativePath = path.relative(globalDir, filename);
demo: const relativePath = path.relative(“/a/b/c”, ‘/a/b/c/d.js’); relativePath返回值为 d.js
const pkg = require(path.join(globalDir, ‘package.json’));
这里获得package.json这个文件
import-local最关键的一部分来了:
const localFile = resolveCwd.silent(path.join(pkg.name, relativePath));
resolveCwd的含义是给出一个包名和主进入文件名,去本地文件中查找是否存在这样的路径
然后我们就进入resolveCwd这个引用库的源码,查看是如何实现的(传入的参数为 lerna/cli.js)
'use strict';const resolveFrom = require('resolve-from');module.exports = moduleId => resolveFrom(process.cwd(), moduleId);module.exports.silent = moduleId => resolveFrom.silent(process.cwd(), moduleId);
这里又引用了resolve-from这个库的silent静默方法(源码见下):
这里需要引起注意一点的是resolve-from这个库传入的两个参数分别是上面提到的 lerna/cli.js以及 process.cwd()这个参数,这个process.cwd的传入参数为Working directory: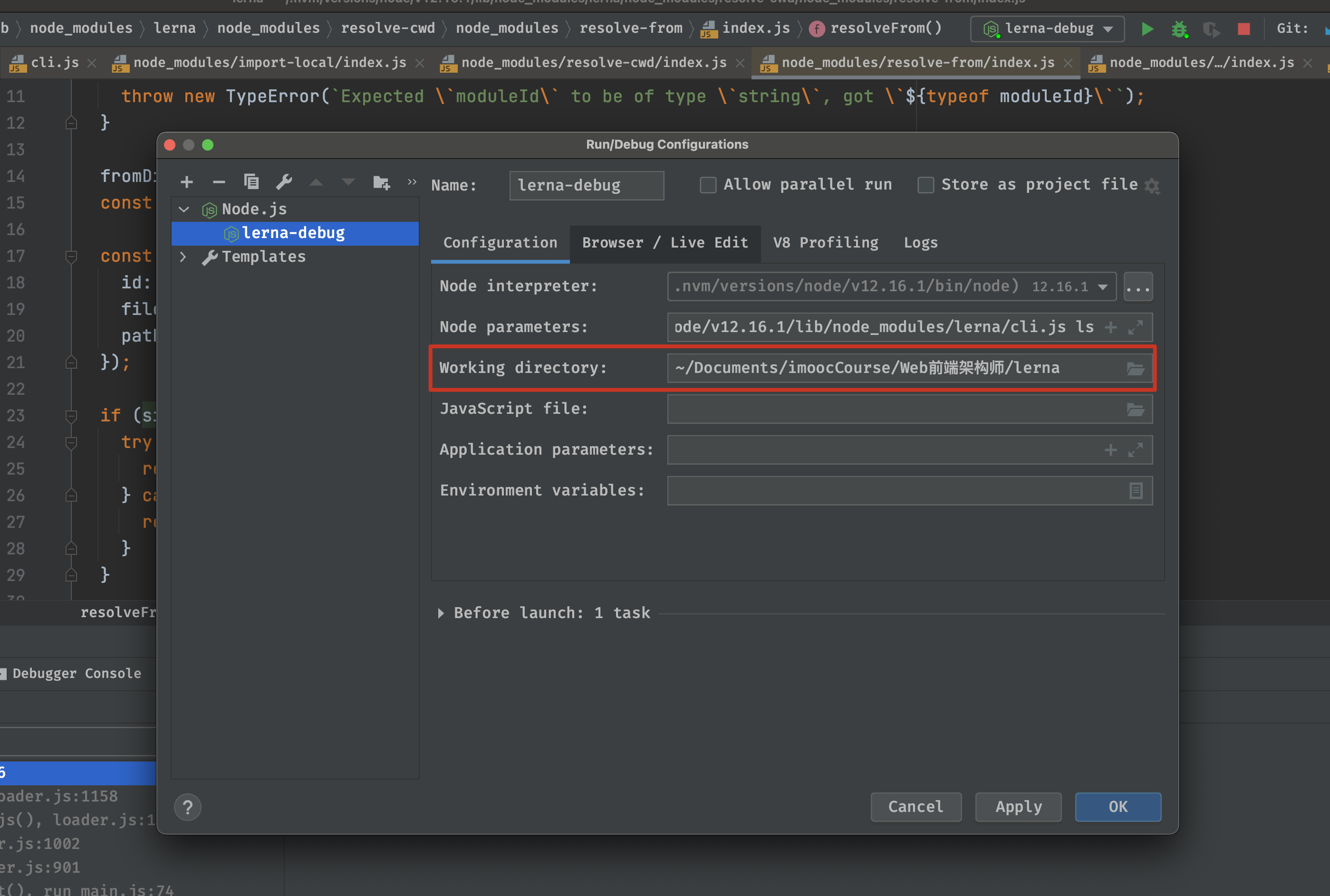
'use strict';const path = require('path');const Module = require('module');const resolveFrom = (fromDir, moduleId, silent) => {if (typeof fromDir !== 'string') {throw new TypeError(`Expected \`fromDir\` to be of type \`string\`, got \`${typeof fromDir}\``);}if (typeof moduleId !== 'string') {throw new TypeError(`Expected \`moduleId\` to be of type \`string\`, got \`${typeof moduleId}\``);}fromDir = path.resolve(fromDir);const fromFile = path.join(fromDir, 'noop.js');const resolveFileName = () => Module._resolveFilename(moduleId, {id: fromFile,filename: fromFile,paths: Module._nodeModulePaths(fromDir)});if (silent) {try {return resolveFileName();} catch (err) {return null;}}return resolveFileName();};module.exports = (fromDir, moduleId) => resolveFrom(fromDir, moduleId);module.exports.silent = (fromDir, moduleId) => resolveFrom(fromDir, moduleId, true);
分析上面代码,最关键的代码为:
const resolveFileName = () => Module._resolveFilename(moduleId, {id: fromFile,filename: fromFile,paths: Module._nodeModulePaths(fromDir)});
Module:node的内置模块,(通常开发过程中是不需要使用的),Module中的 下划线(_)方法,都称为内置方法 _resolveFilename方法,是我们node中 require方法实现的核心方法之一,关于require方法的实现,参考阮一峰老师的这篇文章:require()源码解读
分析上面这段代码,Module._resolveFilename的作用是解析模块的真实路径,这个方法传进去两个参数,其中第一个options我们发现了: Module._nodeModulesPaths(fromDir)这个方法,这个方法的作用是生成node_modules的可能路径。 在对这个方法源码进行学习前,我们预先从老师那了解到了这个方法的实现逻辑:
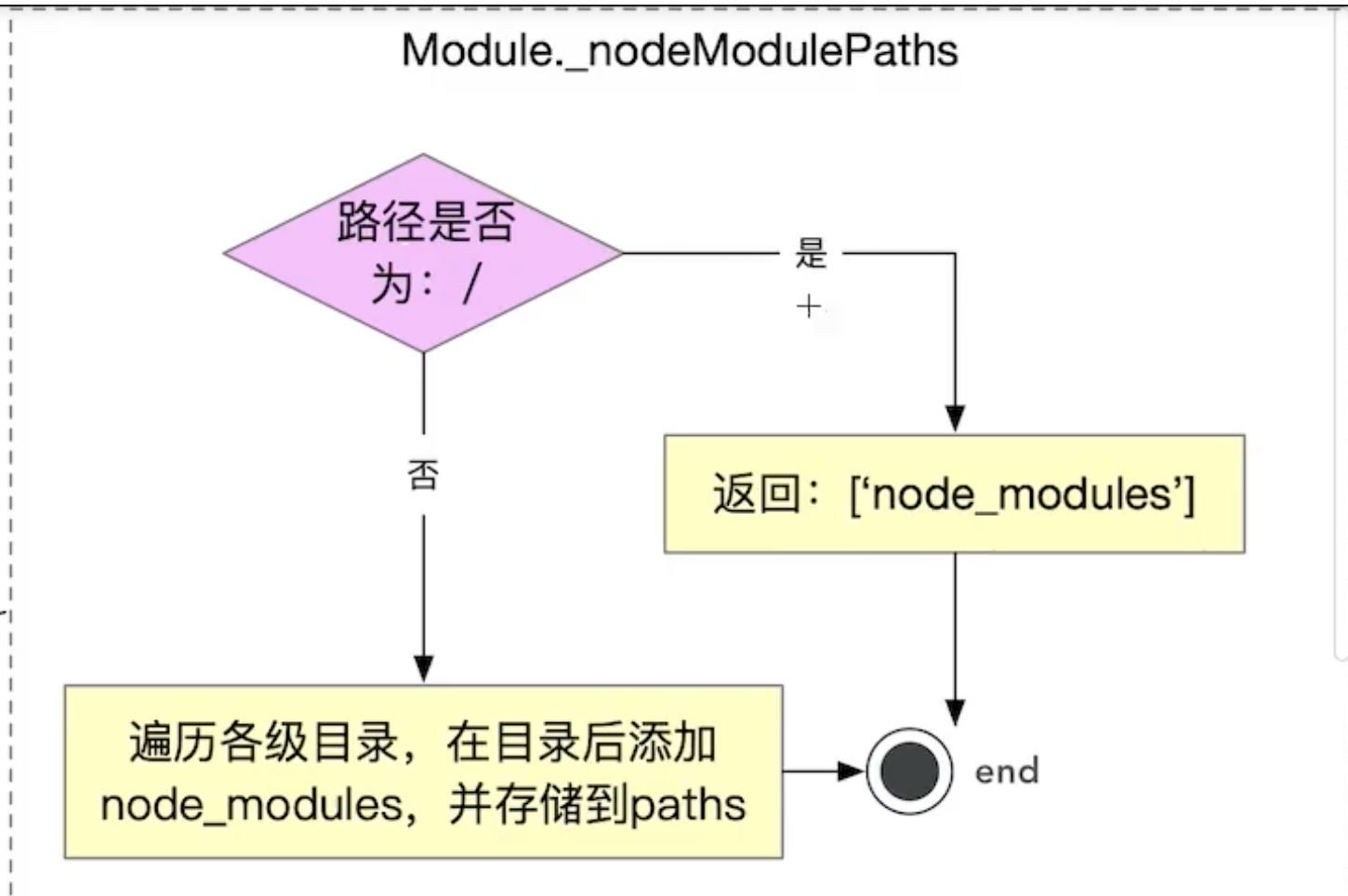
然后我们进入到Module._nodeModulesPaths方法中:
Module._nodeModulePaths = function(from) {// Guarantee that 'from' is absolute.from = path.resolve(from);// Return early not only to avoid unnecessary work, but to *avoid* returning// an array of two items for a root: [ '//node_modules', '/node_modules' ]if (from === '/')return ['/node_modules'];// note: this approach *only* works when the path is guaranteed// to be absolute. Doing a fully-edge-case-correct path.split// that works on both Windows and Posix is non-trivial.const paths = [];for (let i = from.length - 1, p = 0, last = from.length; i >= 0; --i) {const code = from.charCodeAt(i);if (code === CHAR_FORWARD_SLASH) {if (p !== nmLen)paths.push(from.slice(0, last) + '/node_modules');last = i;p = 0;} else if (p !== -1) {if (nmChars[p] === code) {++p;} else {p = -1;}}}// Append /node_modules to handle root paths.paths.push('/node_modules');return paths;};
分析以上代码,这里我们的from是:/Users/liumingzhou/Documents/imoocCourse/Web前端架构师/lerna 然后通过上面算法计算,最后得到的结果是:
[/Users/liumingzhou/Documents/imoocCourse/Web前端架构师/lerna/node_modules, /Users/liumingzhou/Documents/imoocCourse/Web前端架构师/node_modules, /Users/liumingzhou/Documents/imoocCourse/node_modules, /Users/liumingzhou/Documents/node_modules, /Users/liumingzhou/node_modules, /Users/node_modules, /node_modules]
将这个数组返回后,我们继续分析Module._resolveFilename这个方法的源码:
同样在对这个方法源码进行学习前,我们也预先从老师那了解到了这个方法的实现逻辑: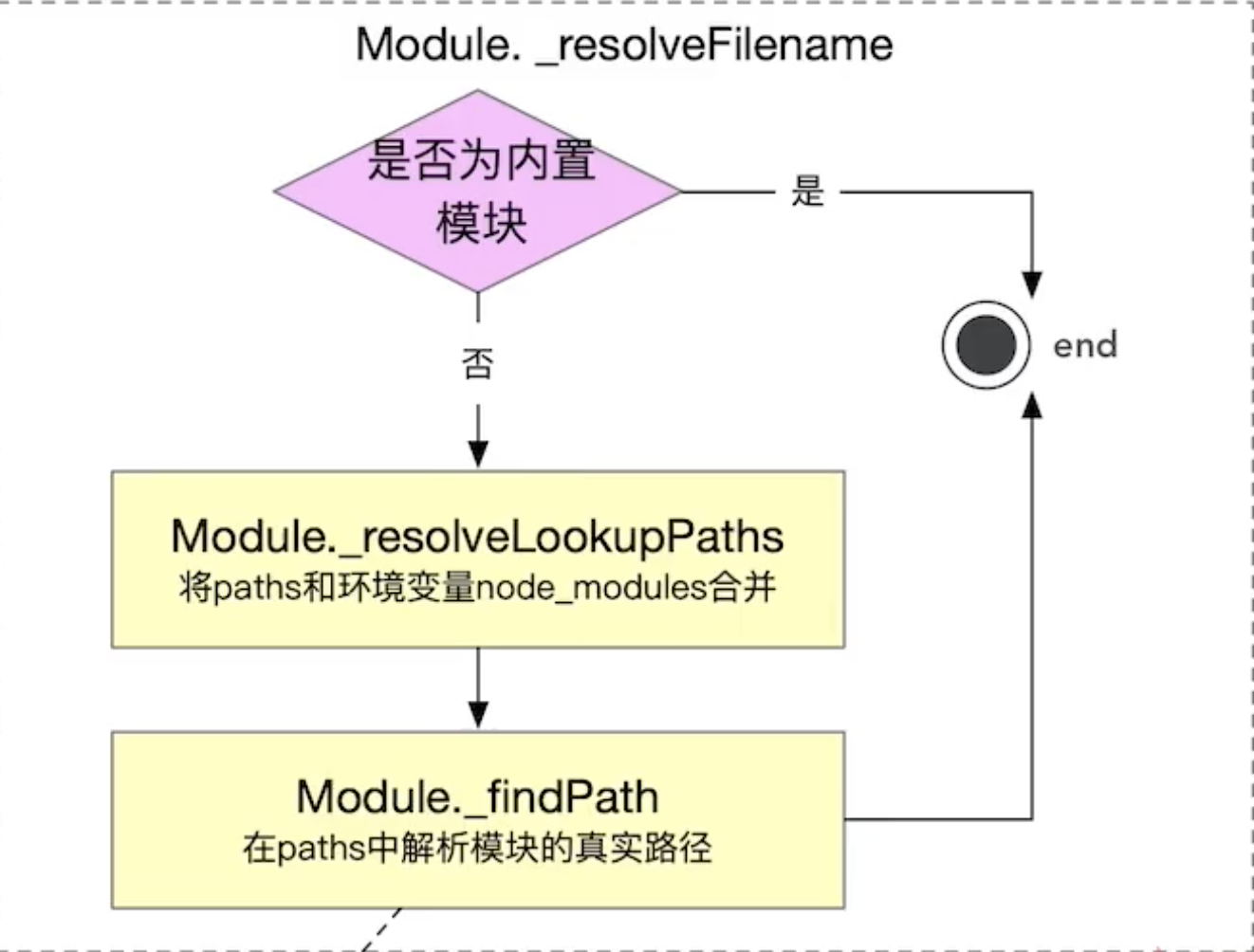
4-14 Node模块加载核心方法_resovleFileName源码深入解析
首先,关于Module._resolveFileName的源码分析要更为复杂,这是因为算法部分较多。
Module._resolveFilename这个方法的源码为如下(代码逻辑添加注释):
Module._resolveFilename = function(request, parent, isMain, options) {if (NativeModule.canBeRequiredByUsers(request)) { //判断是否为可加载的内置模块return request;}let paths;if (typeof options === 'object' && options !== null) { //我们在这传入的options是 undefined,因此之间跳过到else中---即执行Module._resolveLookupPaths(request, parent);if (ArrayIsArray(options.paths)) {const isRelative = request.startsWith('./') ||request.startsWith('../') ||((isWindows && request.startsWith('.\\')) ||request.startsWith('..\\'));if (isRelative) {paths = options.paths;} else {const fakeParent = new Module('', null);paths = [];for (let i = 0; i < options.paths.length; i++) {const path = options.paths[i];fakeParent.paths = Module._nodeModulePaths(path);const lookupPaths = Module._resolveLookupPaths(request, fakeParent);for (let j = 0; j < lookupPaths.length; j++) {if (!paths.includes(lookupPaths[j]))paths.push(lookupPaths[j]);}}}} else if (options.paths === undefined) {paths = Module._resolveLookupPaths(request, parent);} else {throw new ERR_INVALID_OPT_VALUE('options.paths', options.paths);}} else {paths = Module._resolveLookupPaths(request, parent); // 然后就进入了_resolveLookPaths,进行了paths的一些合并,拿到合并的数组}if (parent && parent.filename) { // 我们这里是有filename的const filename = trySelf(parent.filename, isMain, request);if (filename) {emitExperimentalWarning('Package name self resolution');const cacheKey = request + '\x00' +(paths.length === 1 ? paths[0] : paths.join('\x00'));Module._pathCache[cacheKey] = filename;return filename;}}// Look up the filename first, since that's the cache key.const filename = Module._findPath(request, paths, isMain, false); //另一非常有难度的方法,源代码见下面的下面if (filename) return filename;const requireStack = [];for (let cursor = parent;cursor;cursor = cursor.parent) {requireStack.push(cursor.filename || cursor.id);}let message = `Cannot find module '${request}'`;if (requireStack.length > 0) {message = message + '\nRequire stack:\n- ' + requireStack.join('\n- ');}// eslint-disable-next-line no-restricted-syntaxconst err = new Error(message);err.code = 'MODULE_NOT_FOUND';err.requireStack = requireStack;throw err;};
Module._resolveLookupPaths这个方法的源码为如下(代码逻辑添加注释):
主要功能就是将paths和环境变量node_modules合并
Module._resolveLookupPaths = function(request, parent) {if (NativeModule.canBeRequiredByUsers(request)) { // 先判断是否为内置模块debug('looking for %j in []', request);return null;}// Check for node modules paths.if (request.charAt(0) !== '.' ||(request.length > 1 &&request.charAt(1) !== '.' &&request.charAt(1) !== '/' &&(!isWindows || request.charAt(1) !== '\\'))) {let paths = modulePaths; //环境变量中存储的一些node_modules目录if (parent != null && parent.paths && parent.paths.length) {paths = parent.paths.concat(paths); // 与之前传进来的paths进行合并}debug('looking for %j in %j', request, paths);return paths.length > 0 ? paths : null; // 将合并的paths返回}// In REPL, parent.filename is null.if (!parent || !parent.id || !parent.filename) {// Make require('./path/to/foo') work - normally the path is taken// from realpath(__filename) but in REPL there is no filenameconst mainPaths = ['.'];debug('looking for %j in %j', request, mainPaths);return mainPaths;}debug('RELATIVE: requested: %s from parent.id %s', request, parent.id);const parentDir = [path.dirname(parent.filename)];debug('looking for %j', parentDir);return parentDir;};
Module._findPath要解决的问题是在paths中解析模块的真实路径,
同样在对这个方法源码进行学习前,我们也预先从老师那了解到了这个方法的实现逻辑: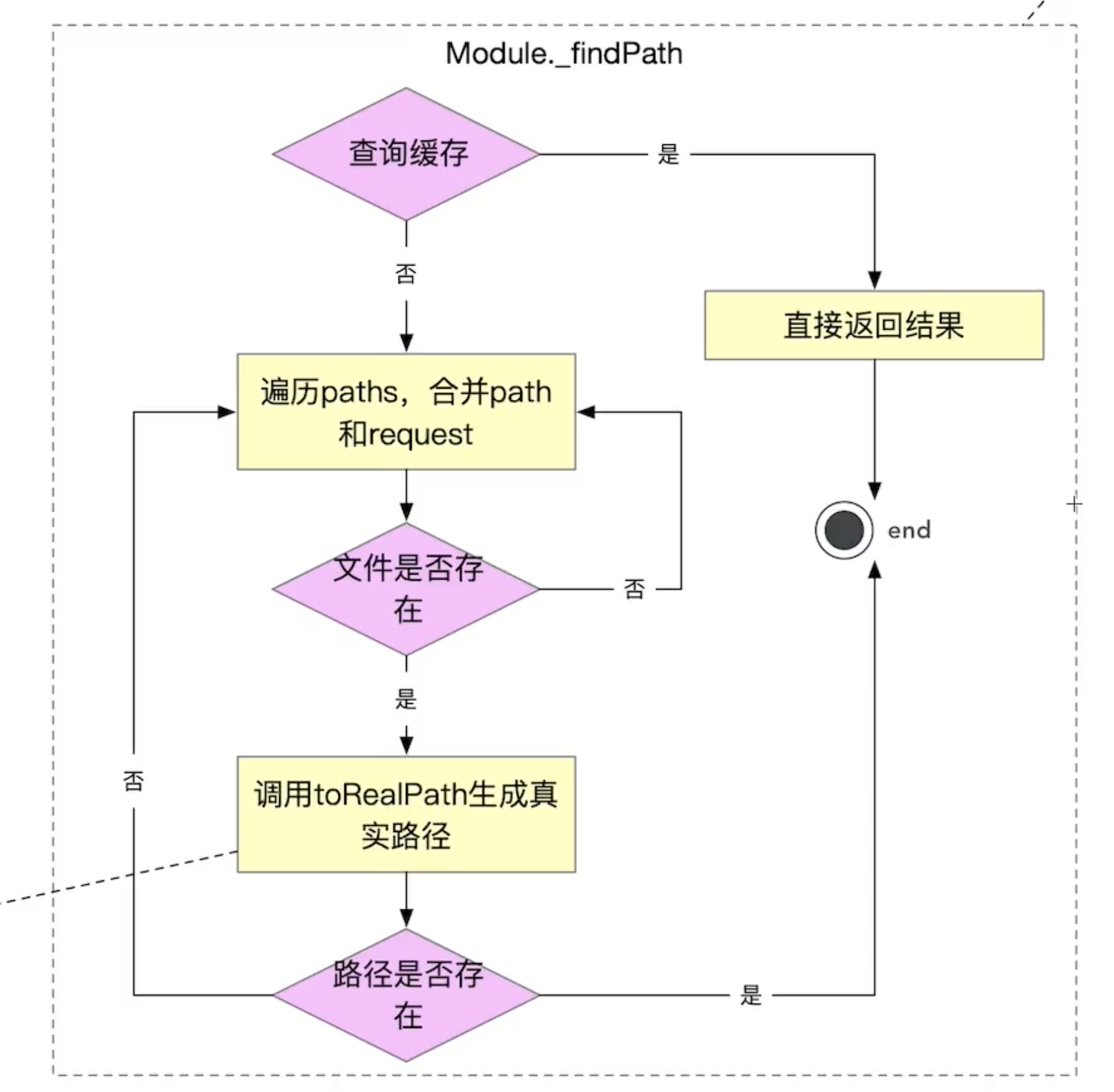
源码如下:
Module._findPath = function(request, paths, isMain) {const absoluteRequest = path.isAbsolute(request); //判断是否为绝对路径if (absoluteRequest) {paths = [''];} else if (!paths || paths.length === 0) {return false;}// 通过 \x00 生成一大段的cacheKeyconst cacheKey = request + '\x00' +(paths.length === 1 ? paths[0] : paths.join('\x00'));const entry = Module._pathCache[cacheKey];if (entry)return entry;let exts;// trailingSlash判断request是否已 / 结尾的let trailingSlash = request.length > 0 &&request.charCodeAt(request.length - 1) === CHAR_FORWARD_SLASH;// 若不是以 / 结尾,if (!trailingSlash) {//会以正则进行匹配,这里的正则在下下节专门学习,这里暂时略过,这里的结论:该正则表示的结果为 是否是以“/..、/.、.. 、 . ”结尾trailingSlash = /(?:^|\/)\.?\.$/.test(request);}// For each pathfor (let i = 0; i < paths.length; i++) {// Don't search further if path doesn't exist//一次拿出paths中存储的值const curPath = paths[i];//stat(curPath)返回结果 1是文件夹,0为文件,我们这里第一个返回的是文件夹 1,因此,不会跳出循环,继续向下执行if (curPath && stat(curPath) < 1) continue;//这里的意思就是将我们的curPath与request做一个结合const basePath = resolveExports(curPath, request, absoluteRequest);let filename;//stat(basePath)看上面合成的文件是否存在,为0说明为文件且文件存在const rc = stat(basePath);// 判断结尾是不是一个 /if (!trailingSlash) {// 判断当前的basePath是否为一个文件if (rc === 0) { // File.// isMain是否传入if (!isMain) {//是否阻止去做超链接,根据我们的分析,这里不是 preserveSymlinks为falseif (preserveSymlinks) {filename = path.resolve(basePath);} else {// toRealPath:我们的分析 basePath在这里为软连接,然后通过此方法,找到真实的文件路径。然后,我们进入下一节,看看这个toRealPath是如何实现的filename = toRealPath(basePath);}} else if (preserveSymlinksMain) {// For the main module, we use the preserveSymlinksMain flag instead// mainly for backward compatibility, as the preserveSymlinks flag// historically has not applied to the main module. Most likely this// was intended to keep .bin/ binaries working, as following those// symlinks is usually required for the imports in the corresponding// files to resolve; that said, in some use cases following symlinks// causes bigger problems which is why the preserveSymlinksMain option// is needed.filename = path.resolve(basePath);} else {filename = toRealPath(basePath);}}if (!filename) {// Try it with each of the extensionsif (exts === undefined)exts = ObjectKeys(Module._extensions);filename = tryExtensions(basePath, exts, isMain);}}if (!filename && rc === 1) { // Directory.// try it with each of the extensions at "index"if (exts === undefined)exts = ObjectKeys(Module._extensions);filename = tryPackage(basePath, exts, isMain, request);}if (filename) {Module._pathCache[cacheKey] = filename;return filename;}}return false;};
4-15 fs模块toRealPath源码深入解析
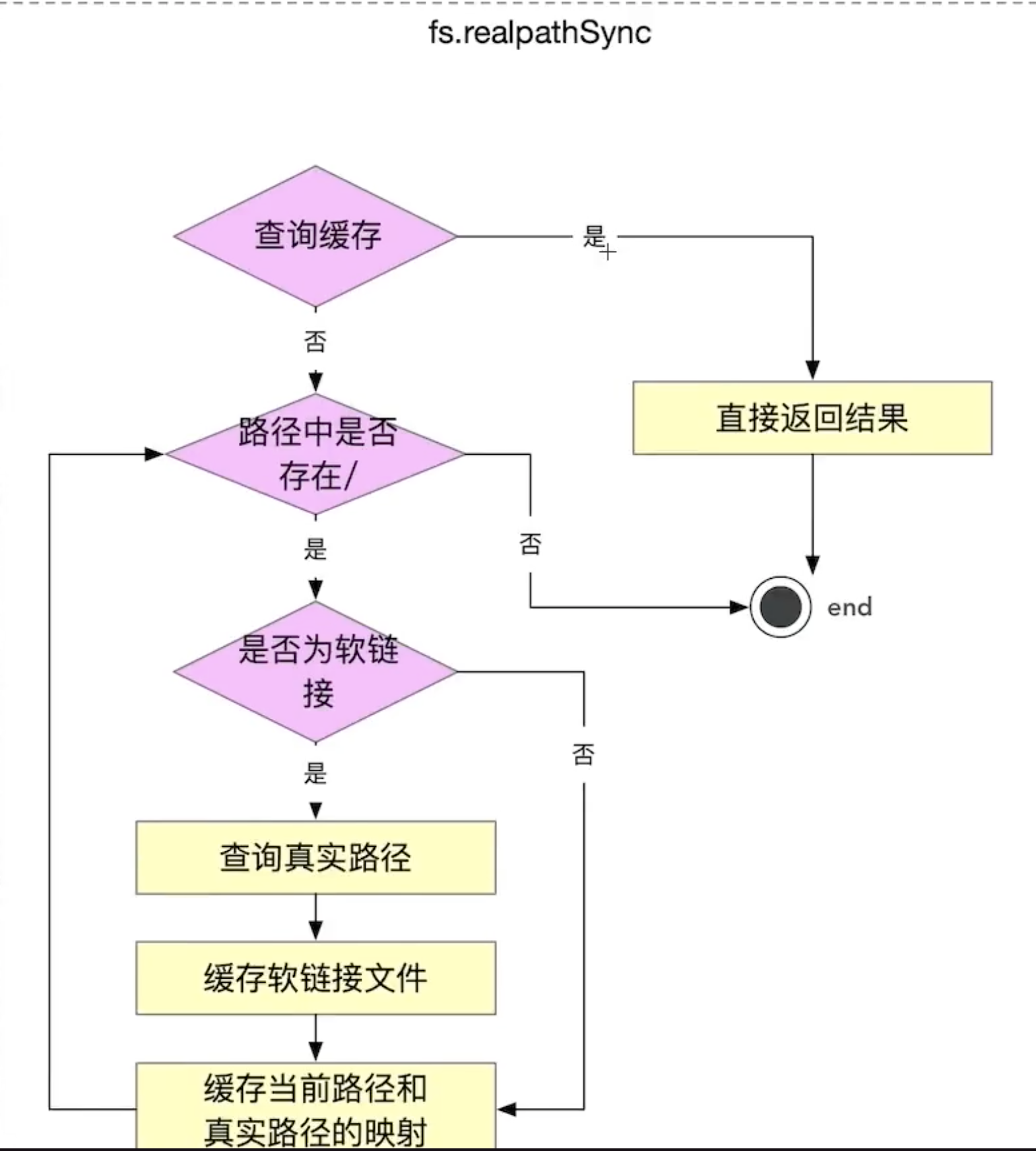
我们到toRealPath方法后,webStorm的node调试工具,点击继续 Step Into到该方法中,代码如下:
// 通过代码,我们知道toRealPath的方法实现,正如上面的逻辑图显示的,使用的是 fs.realpathSync这个模块。function toRealPath(requestPath) {// 该方法传入两个参数,一个路径地址 requestPath,以及一个options// realpathCache为一个chche,表示的是当前已经做过路径判断的所有路径缓存,绝大多数的key值与value值是一样的,并没有软链接,但是也存在少量的有软连接的:key与value值不同return fs.realpathSync(requestPath, {[internalFS.realpathCacheKey]: realpathCache});}
同样的,我们在进去toRealPath这个方法,看到fs.realpathSync实现之前,我们先从老师哪里有拿到逻辑图,并根据图进行分析学习该代码里面的逻辑:
然后我们继续 Step Into到fs.realpathSync这个方法中,源码如下:
// options 为Symbolfunction realpathSync(p, options) {if (!options)options = emptyObj;elseoptions = getOptions(options, emptyObj);p = toPathIfFileURL(p);// 如果不是string格式的,进行格式转换if (typeof p !== 'string') {p += '';}//判断该路径是否为有效路径validatePath(p);//pathModule 与我们直接引用的path模块没有区别:相对路径转为绝对路径p = pathModule.resolve(p);// cache为一个map对象const cache = options[realpathCacheKey];// 查找缓存const maybeCachedResult = cache && cache.get(p);// 是否查到了缓存,如果查到直接返回,如果没有查到,继续向后if (maybeCachedResult) {return maybeCachedResult;}// 定义所有软连接的缓存,ObjectCreate(null)创建的对象没有原型链,好处为它是一个纯粹的对象,节约内存空间const seenLinks = ObjectCreate(null);const knownHard = ObjectCreate(null);//将传入的path保存下来,做了一个缓存,这里的p相当于缓存中的key(若是软连接,则为软连接路径),original相当于value(实际路径),这么做的原因为:这里的p我们后面可能会发生改变const original = p;// 然后下面代码,进入到上图流程图中的路径是否存在/这个流程// Current character position in plet pos;// The partial path so far, including a trailing slash if anylet current;// The partial path without a trailing slash (except when pointing at a root)let base;// The partial path scanned in the previous round, with slashlet previous;// Skip over roots// 找到p中的根路径current = base = splitRoot(p);pos = current.length;// On windows, check that the root exists. On unix there is no need.// 这里是windows系统的逻辑,我们是mac的,所以可以先跳过if (isWindows && !knownHard[base]) {const ctx = { path: base };binding.lstat(pathModule.toNamespacedPath(base), false, undefined, ctx);handleErrorFromBinding(ctx);knownHard[base] = true;}// Walk down the path, swapping out linked path parts for their real// values// NB: p.length changes.// 然后开始循环 由上文得知,我们的pos长度为1,p的长度为传入的path的长度while (pos < p.length) {// find the next part// nextPart这里调用的就是p.indexOf('/',pos),这个方法举例如下:// "/xxx/yyy".indexOf('/') => 0 这里我们找到的是第一个“/”的位置,如果我们想找第二个“/”位置// "/xxx/yyy".indexOf('/',1) => 4,这里的1指的是跳过第一个元素,从第二个元素开始寻找const result = nextPart(p, pos);previous = current;if (result === -1) {const last = p.slice(pos);current += last;base = previous + last;pos = p.length;} else {current += p.slice(pos, result + 1);base = previous + p.slice(pos, result);pos = result + 1;}// 判断一下在cahe中是否存在// Continue if not a symlink, break if a pipe/socketif (knownHard[base] || (cache && cache.get(base) === base)) {// 判断是否为一个fileif (isFileType(statValues, S_IFIFO) ||isFileType(statValues, S_IFSOCK)) {break;}continue;}let resolvedLink;// 判断是不是软链接,从缓存中去拿const maybeCachedResolved = cache && cache.get(base);if (maybeCachedResolved) {resolvedLink = maybeCachedResolved;} else {// Use stats array directly to avoid creating an fs.Stats instance just// for our internal use.// 没有拿到,然后做处理const baseLong = pathModule.toNamespacedPath(base);const ctx = { path: base };// stats可以打印出 文件在操作系统下的各种信息/ dev_t:文件的设备编号 ino_t:文件在此设备的唯一标识const stats = binding.lstat(baseLong, false, undefined, ctx);handleErrorFromBinding(ctx);// 判断是否为一个软连接if (!isFileType(stats, S_IFLNK)) {// 如果不是软连接,将判断过的路径放入到 knowHard当中knownHard[base] = true;if (cache) cache.set(base, base);continue;}// 判断到该路径是一个软连接,然后继续执行下面的代码// Read the link if it wasn't read before// dev/ino always return 0 on windows, so skip the check.//linkTarget 软连接实际的路径地址let linkTarget = null;let id;// 判断是否为window操作系统if (!isWindows) {// 拿到stat的0号元素,即我们上面注释提到的文件设备编号const dev = stats[0].toString(32);// 拿到stat的7号元素,即我们上面注释提到的文件唯一标识//拿到这两个是想生成一个唯一键:这个文件在当下PC系统下的唯一键const ino = stats[7].toString(32);id = `${dev}:${ino}`;// 通过这两个唯一键生成的唯一键作为 seenLinks的唯一键// 下面代码为在seenLinks中查找是否有这个id,如果有就直接拿出来if (seenLinks[id]) {linkTarget = seenLinks[id];}}// 没有这个软连接的实际路径地址if (linkTarget === null) {const ctx = { path: base };binding.stat(baseLong, false, undefined, ctx);handleErrorFromBinding(ctx);// 拿到软连接的实际路径linkTarget = binding.readlink(baseLong, undefined, undefined, ctx);handleErrorFromBinding(ctx);}resolvedLink = pathModule.resolve(previous, linkTarget);if (cache) cache.set(base, resolvedLink);if (!isWindows) seenLinks[id] = linkTarget;}// Resolve the link, then start over// 将path真实路径重新生成p = pathModule.resolve(resolvedLink, p.slice(pos));// Skip over rootscurrent = base = splitRoot(p);pos = current.length;// On windows, check that the root exists. On unix there is no need.if (isWindows && !knownHard[base]) {const ctx = { path: base };binding.lstat(pathModule.toNamespacedPath(base), false, undefined, ctx);handleErrorFromBinding(ctx);knownHard[base] = true;}}if (cache) cache.set(original, p);return encodeRealpathResult(p, options);}
4-16 讲一个高难度的正则表达式(想挑战的点进来)
trailingSlash = /(?:^|\/).?.$/.test(request);
console.log(/(?:^|\/).?.$/.test(‘a’)) —> false console.log(/(?:^|\/).?.$/.test(‘..’)) —> true console.log(/(?:^|\/).?.$/.test(‘/..’)) —> true console.log(/(?:^|\/).?.$/.test(‘/Users’)) —> false
‘\’ 转译字符
在正则表达式中 ‘.‘ 是有含义的,表示匹配任意一个字符: const str = ‘a’; console.log(a.match(/./)) —> [‘a’, index:0, input:’a’, groups:undefined]
因此在正则表达式中要匹配 . 的话,需要加一个 反斜杠 ‘\’,因此‘.’ 匹配的就是一个点 console.log(a.match(/./)) —> null
‘?’:表示匹配0个或1个字符 ‘$’:表示最后的匹配样式 ():表示需要返回匹配结果,分组 (?: ) 表示非匹配分组,不把()中分组的内容显示出来 ^:表示非的符号:[!.]表示的是匹配没有. 符号的,需要加[],但是上文的正则没有[],上文表示的是匹配一个空格, ‘|’ : 或
4-17 大招:如何快速拿到面试“一血”
简历简介
简历中简介部分至关重要,因为它位于简历的第一屏,是面试官最容易关注的部分,所以我们应该在简介部分充分突出我们的个人特长和优势
认真学完本章内容后应该怎么修改简历?
- 熟悉yargs脚手架开发框架
- 熟悉多Package管理工具lerna的使用方法和使用原理
- 深入理解Node.js模块路径解析流程
面试官问起细节后如何回答?
- 如何通过yargs开发一个脚手架?
答:比如vue-cli的脚手架为:vue create myProjectName
脚手架的构成一般由三个部分构成:
第一个部分就是: 主命令,也就是bin,它是在packag.json中配置的,通过npm link 进行本地安装 第二个部分 :command:命令 第三个部分:options 参数 然后需要的一点是主命令bin的配置指向的主文件中,需要在文件顶部加上 #!/usr/bin/env node,就是说在环境变量中找到node命令来执行。
脚手架的初始化流程
第一步:首先是直接调用Yargs的构造函数,直接去生成一个脚手架
第二步:会调用一系列的Yargs提供的常用方法,对脚手架功能进行一个增强。 比如 yargs.usage(用法)、 yargs.options(注册一些脚手架参数熟悉)、 可以调用yargs.group(来对脚手架参数熟悉进行分组)、 yargs.fail(对脚手架异常进行监听), 还有包括yargs尾部结语的设置yargs.elipogue()、 脚手架窗口设置yargs.wrap() 以及yargs.decomandrecommed(至少输入一个参数) 以及yargs.recommedCommands()推荐命令的提示等
第三步:需要对脚手架的参数进行一些解析:hideBin(process.argv),其实也就是直接取出从第三个开始的参数.调用的时候直接 yargs.argv 还有一种解析方式就是通过yargs.parse(argv,options)的方法
第四步:当脚手架的参数解析完成之后,我们要进行命令注册 命令注册我们使用的是yargs.command()方法。 command的注册方式有两种:第一种是一次传参(command,describe,builder,handler),还有一种方式就是传入一个对象,对象属性与第一种方式传入的相同。
- 熟悉多Package管理工具lerna的使用方法和使用原理
答:首先lerna是基于一个 git + npm的多package,也就是多包的项目管理工具,像一些开源的大型库:vue-vcli/create-react-app/babel等都是基于lerna进行多包管理的。他的作用就是降低包的管理操作成本,提高开发效率。像包的安装、依赖的添加、依赖的解除以及包的发布、打标签等功能。
实现原理: 首先就是通过 import-local这个库优先调用lerna的本地命令, 然后通过yargs生成一个脚手架、生成脚手架后生成一些全局参数、然后注册命令,通过yargs.parse方法进行参数解析。 需要注意的是lerna的命令注册过程中,需要传入builder以及handler两个方法,builder命令用于注册命令专属的options,而handelr用来处理命令的业务逻辑。 有一点非常值得学习的内容就是lerna它是通过配置本地依赖的方式进行开发的,具体写法就是在package.json的依赖当中通过file的格式书写,在lerna publish的时候再将该路径替换。
- 对Node.js模块路径解析流程的一个理解
第一:首先Node.js模块的路径解析是通过 require.resolve()方法来实现的 第二:这个resolve方法就是Module._resolveFileName()方法 它的作用就是我们给定一个模块名称的时候,查找处这个模块的真实路径。
然后,他的核心实现流程有三点:
- 在执行流程中判断当前路径是否为内置模块,若是内置模块直接返回
- 若不是内置模块,它会继续调用自身的Module._resolveLookupPaths()方法生成node_modules的所有可能路径
- 最后再通过Module._findPath()去查询模块的真实路径。
这里关于Module._findPaths()方法的核心实现流程有四步
- 查询缓存(将request[模块名称]和paths[上面返回的所有可生成的node_modules路径]通过\x00合并成cacheKey)
- 缓存查不到,就会遍历paths,将每一个path与request结合组成文件路径basePath
- 然后判断这个basePath路径是否存在,如果存在会调用 fs.realPathSync()方法获取文件的真实路径,不存在就会继续遍历。
- 同时,将文件的真实路径缓存到Module._pathcache()中。
这里关于fs.realPathsync()方法的核心流程有三点:
- 仍然是查询缓存,缓存的key就是我们的path,即basePath,
- 如果这个key没有找到,就会将这个key从左到右开始遍历,通过/进行循环遍历,拆分路径,然后判断这个路径是否为软链接,如果是软链接,就去查询它的真实路径,并生成新的path路径,这个新的path路径继续传入这个遍历函数,继续往后遍历,(这里有一个细节需要注意的是:遍历过程中生成的子路径base会缓存在knowHard和ache中,避免重复查询)。
- 遍历完成后,就会得到模块的真实路径,并且将原始路径,也就是我们说的软连接路径作为key值,将真实值作为值,保存在缓存中
在require中还有一个方法是 require.resolve.paths()方法,这个方法的作用是用于获取所有node_modules可能存在的路径,他的核心内容就是Module._resolveLookupPaths()
Module._resolveLookupPaths()的实现原理有两点 第一点,如果是 /路径,就在后面加入 node_modules 第二点,将路径从后往前遍历,如果查询到 / ,就拆分路径,在后面加上node_modules,一直遍历到查找不到 /路径,就会返回这个paths数组。

若有收获,就点个赞吧
0 人点赞
