常用函数
文本处理函数
- SUBSTR(str FROM pos FOR len) 或SUBSTRING
截取字符串
- UPPER(str)
字符串大写
- LOWER(str)
字符串小写
- RTRIM(str)
去右侧空格
- LTRIM(str)
去左侧空格
- TRIM([remstr FROM] str)
去左右空格
- LENGTH(str)
求字符串长度
时间日期处理函数
- CURDATE() 和 CURTIME()
取当前系统时间
- YEAR(date)、MONTH(date)、DAY(date)、HOUR(time)、MINUTE(time)、SECOND(time)
提取时间日期特定部分
数值处理函数
- ABS(X)
取绝对值
- EXP(X)
求e^X指数值
- ROUND(X) 四舍五入, round(1.55,1)=1.6
- floor() 向下取整
- ceiling() 向上取整
聚合函数
- AVG([DISTINCT] expr)
- COUNT(DISTINCT expr,[expr…])
对特定列中具有值的行进行计数, 忽略NULL值, COUNT(*) 不管是否有空值都计数
- MAX(expr)
- MIN(expr)
- SUM(expr)
MYSQL语句
DDL : Data Define Language 数据定义语言
主要用来对数据库、表进行一些管理操作。如:建库、删库、建表、修改表、删除表、对列的增删改等等。
创建库
create database [if not exists] 库名;
删除库
drop databases [if exists] 库名;
创建表
create table 表名(字段名1 类型[(宽度)] [约束条件] [comment '字段说明'],字段名2 类型[(宽度)] [约束条件] [comment '字段说明'],字段名3 类型[(宽度)] [约束条件] [comment '字段说明'])[表的一些设置];
create table test2(a int not null AUTO_INCREMENT PRIMARY KEY comment '字段a',b int not null default 0 comment '字段b',c varchar(20) not null comment '字段c',unique key(c),index index_b_c(b, c) using btree)ENGINE = InnoDB CHARACTER SET = utf8mb4;
DML : Data Manipulation Language 数据操作语言
以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入、更新与删除
插入
插入单行
INSERT INTO 表名称 VALUES (值1, 值2,....)或INSERT INTO 表名称 (列1, 列2,...) VALUES (值1, 值2,....)如INSERT INTO Persons VALUES ('Gates', 'Bill', 'Xuanwumen 10', 'Beijing')INSERT INTO Persons (LastName, Address) VALUES ('Wilson', 'Champs-Elysees')
插入多行
insert into 表名 (列1, 列2) values (值1,值2),(值1,值2),(值1,值2);如insert into test values (100,101,102),(200,201,202),(300,301,302),(400,401,402);
更新
单表更新
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值如UPDATE Person SET Address = 'Zhongshan 23', City = 'Nanjing' WHERE LastName = 'Wilson
多表更新
update 表1名称 [[as] 别名1], 表2名称 [[as] 别名2] set [别名.]字段 = 值,[别名.]字段 = 值 [where条件]如update test1 as t1, test2 t2 set t1.a = 2 ,t1.b = 2, t2.c1 = 10 where t1.a = t2.c1;
删除
DELETE FROM 表名称 WHERE 列名称 = 值如DELETE FROM Person WHERE LastName = 'Wilson'
常见面试题
如何设计一个关系型数据库?
答:
设计一个关系型数据库如图设计一款软件, 首先需要对软件功能模块进行划分, 大致可分为以下模块:
索引是建立的越多越好吗?
答:
不是
- 数据量小的表不需要建立索引, 建立会增加额外的索引开销
- 数据变更需要维护索引, 因此更多的索引意味着更多的维护成本
- 更多的索引意味着也需要更多空间
创建索引的原则是什么?
- 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
- 较频繁作为查询条件的字段才去创建索引
- 更新频繁字段不适合创建索引
- 若是不能有效区分数据的列不适合做索引列(联合索引应将区分度越大的列排在越前面)
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 对于定义为text、image和bit的数据类型的列不要建立索引。
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
如何创建索引?
ALTER TABLE table_name ADD INDEX index_name (column_list);
MyISAM与InnoDB关于锁方面的区别是什么?
答:
- MyISAM默认用的是表级锁, 不支持行级锁
- InnoDB默认用的是行级锁, 也支持表级锁
- InnoDB引擎操作不走索引时, 使用的是表级锁, 会锁住整张表, 走索引时会使用行级锁
- 行级锁比表级锁上锁代价高
mysql中发生查询操作时会上读锁, 修改操作时会上写锁, 读锁也称为共享锁, 写锁也称为排他锁, 当上了共享锁时, 依然支持再上共享锁, 不支持上排他锁; 而上了排他锁时, 不支持再上锁
数据库锁的分类
- 按照锁的粒度划分, 可分为表级锁, 行级锁, 页级锁
- 按照锁级别划分, 可分为共享锁, 排他锁
- 按照锁方式划分, 可分为自动锁, 显示锁
- 按操作划分, 可分为DML锁, DDL锁
- 按使用方式划分, 可分为乐观锁, 悲观锁
- 悲观锁,具有强烈的独占和排他特性。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
- 乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量。乐观锁不会刻意使用数据库本身的锁机制, 乐观锁的实现方式有两种:
- CAS 实现:Java 中java.util.concurrent.atomic包下面的原子变量使用了乐观锁的一种 CAS 实现方式。
- 版本号控制:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会 +1。当线程 A 要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值与当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
数据库事务的四大特性 ACID
- 原子性 (Atomic)
- 一致性 (Consistency)
- 隔离性 (Isolation)
- 持久性 (Durability)
事务并发访问引起的问题
- 更新丢失
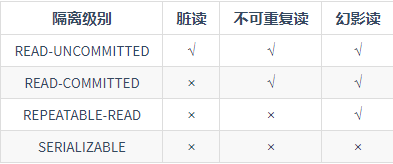
- 脏读 : 隔离级别为READ-UNCOMMITTED时会产生, 将隔离级别上调到READ-COMMITTED以上可避免.
- 不可重复读 : 隔离级别低于REPEATABLE-READ时会产生, 上调到REPEATABLE-READ以上可避免
- 幻读 : InnoDB 存储引擎在 REPEATABLE-READ(可重读) 事务隔离级别下,允许应用使用 Next-Key Lock 锁算法来避免幻读的产生
如何定位并优化慢查询SQL?
大致思路是:
- 根据慢查询日志定位慢查询sql
- 可以使用long_query_time变量指定多长时间算作慢查询, 一般设置为1s
- 慢日志存在硬盘上
- 使用explain工具分析sql, explain 命令执行结果中有两列比较重要
- Type字段, 该字段性能从优到差如下 : system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index _subquery > _range > index > all (最后两个表示走的全表扫描, 需要优化)
- Extra字段
- Using where
- Using index
- Using filesort :使用了外部排序 (性能很差)
- Using temporary : 使用了临时表(性能很差)
- Using index condition
- 修改sql尽量走索引

若有收获,就点个赞吧
0 人点赞
