一. Set
1. HashSet的底层实现?
HashSet底层由HashMap实现, 将元素存在HashMap的key上, 而对应的value则是一个空对象.如下图: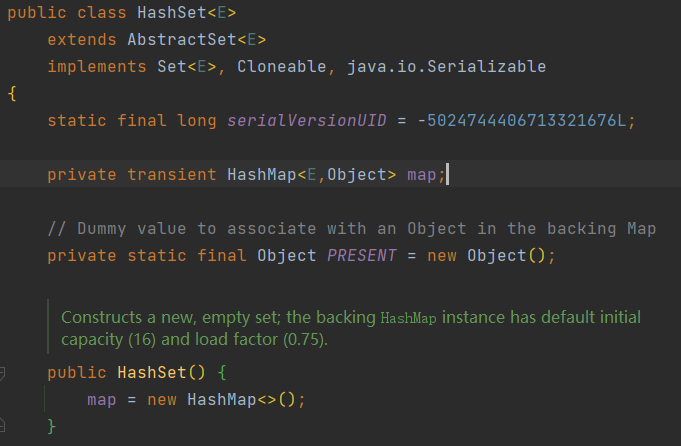
存储数据的map声明了transient关键字, 防止序列化, 这是由于值只存于key上, 整个map序列化会浪费空间影响性能, 因此HashSet重写了序列化方法writeObject(), 如下: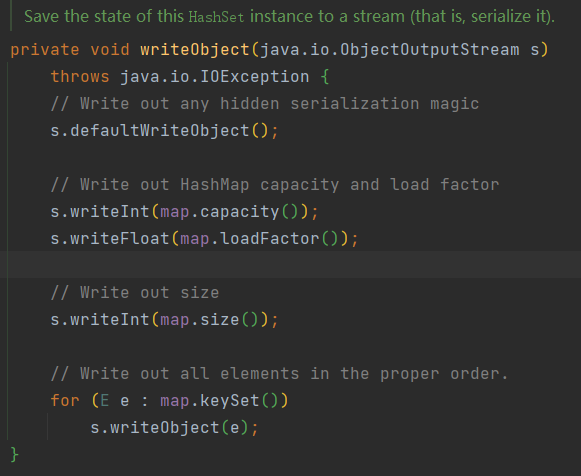
2. TreeSet的底层实现?
TreeSet可以确保集合元素处于排序状态, TreeSet支持自然排序和定制排序, 它的底层是由TreeMap实现的. 与HashSet的另一个区别是, TreeSet不能存入null值.
二. List
1. ArrayList的底层实现?
ArrayList是基于数组实现的List, 所以ArrayList封装了一个动态的, 允许再分配的Object[]数组. ArrayList对象使用initialCapacity参数来设置该数组长度, 若初始化时不指定长度, 则默认长度为10, 当添加元素超出数组容量时, ArrayList会自动扩容, 如果需要对ArrayList缩容, 则需要主动调用trimToSize().
扩容策略如下: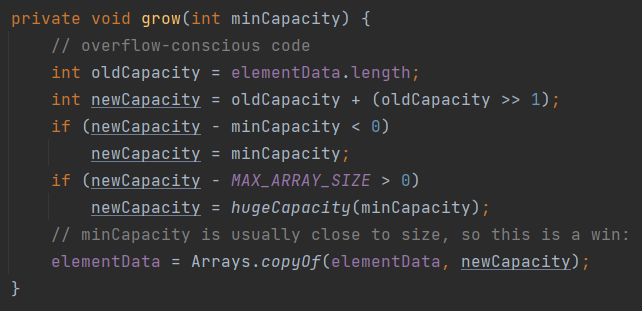
从上面代码可知, 如果需要扩容, 则每次扩容到原来的1.5倍, 如果1.5倍还不够, 则直接将容量扩充到真实需要的长度.
注意:每次扩容都涉及到旧数组拷贝到新数组,比较耗时,因此建议初始化时设置好大致需要的容量,避免扩容带来的性能损失。
2. LinkedList
LinkedList是基于双向链表实现的List. 它内部的元素可以为null.
三. Map
1. HashMap的底层实现?
在JDK1.8中, HashMap的底层采用了”数组+链表+红黑树”实现.
重点关注它的数据结构, put的过程, 扩容机制.
数据结构
HashMap中每一个元素被封装成一个Node类型的对象, 结构如下: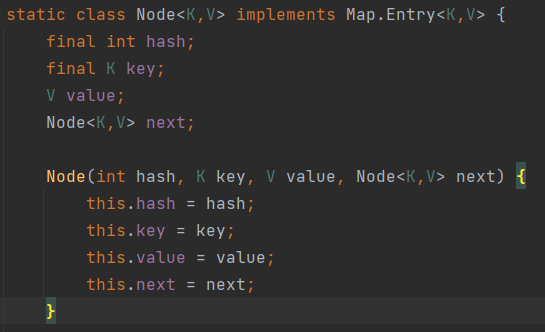
它除了存储了元素的hash值, key和value, 还有一个指向next节点的指针, 因此它是一个单向链表.
一定条件下, 存储节点会转换为TreeNode, 即使用红黑树来存储数据, 树节点结构如下: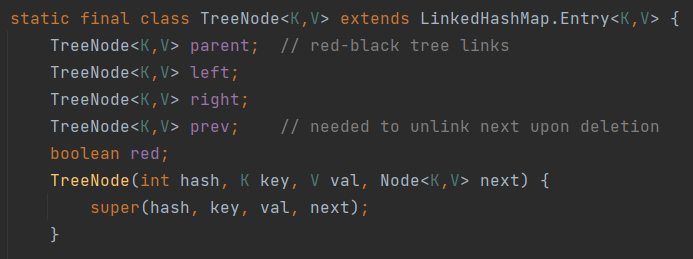
put的过程
- 先根据key通过哈希算法和与运算得出要存储的数组下标
- 如果该数组下标元素为空, 则将key和value封装为Entry ( jdk1.7 ) 或Node ( jdk1.8 ) 对象, 存入该数组下标位置
- 如果数组下标位置不空, JDK1.7 和 1.8 处理流程略有区别, 区别如下:
- 如果是1.7 : 会先判断是否需要扩容, 如果需要扩容, 则先进行扩容, 如果不需要扩容, 则生成Entry对象, 使用头插法插入到当前位置的链表当中
- 如果是1.8 : 会先判断当前位置上的Node的类型, 可能是红黑树Node类型, 也可能是链表Node类型
- 如果是红黑树Node类型, 则将key和value封装为一个红黑树节点并添加到该红黑树中去, 在红黑树中如果存在该key(判断两个对象是否相等的方法参考3), 则只做更新
- 如果该位置是链表Node类型, 则将key和value封装为一个链表Node, 并通过尾插法插入到当前链表当中, 尾插法的过程中, 需要遍历链表, 如果链表中已经存在该key, 则只更新, 如果不存在,则插到链尾, 过程中记录链表长度, 如果插入后, 链表长度达到8(有个前提, 即数组长度达到64才会转换为红黑树, 见下文), 则会将该链表转换成红黑树(当移除节点或扩容导致红黑树中节点数量少于等于6个时, 又会重新转换回链表结构)
- 在将key和value插入完成后, 再去判断是否需要扩容, 如果需要扩容, 则进行扩容
扩容机制
- HashMap的默认容量是16, 容量必须是2的n次方, 这是为了扩容后元素移动更加快速. 如果初始化指定的容量不是2的n次方, 则内部初始化时会自动扩充到2的n次方.
- 当map中的元素个数超过阈值(阈值决定了HashMap何时扩容,以及扩容后的大小,等于table大小乘以loadFactor), 则会扩容, 每次扩容时会将容量翻倍.
- 默认负载因子loadFactor为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
- 需要注意的是HashMap中还有一个属性MIN_TREEIFY_CAPACITY=64, 它表示最小树形化阈值, 即只有当数组长度超过64时, 才会在链表长度大于8时转换成红黑树; 如果数组长度小于64, 则认为是由于数组长度太小导致冲突过多, 会优先采取扩容措施.
- 扩容后, 元素移动策略:
如, 原容量=16=00010000, 扩容后=32=00100000
hash & (16-1) = hash & 00001111
hash & (32-1) = hash & 00011111
对n取模相当于对与n-1做与运算 A % n == A & (n-1)
翻倍扩容后, 只要判断map中元素的hash值和新容量与运算后的第5位是0还是1, 如果是0则不需要移动, 如果是1则将该元素的位置+16即可(以16扩容为32为例)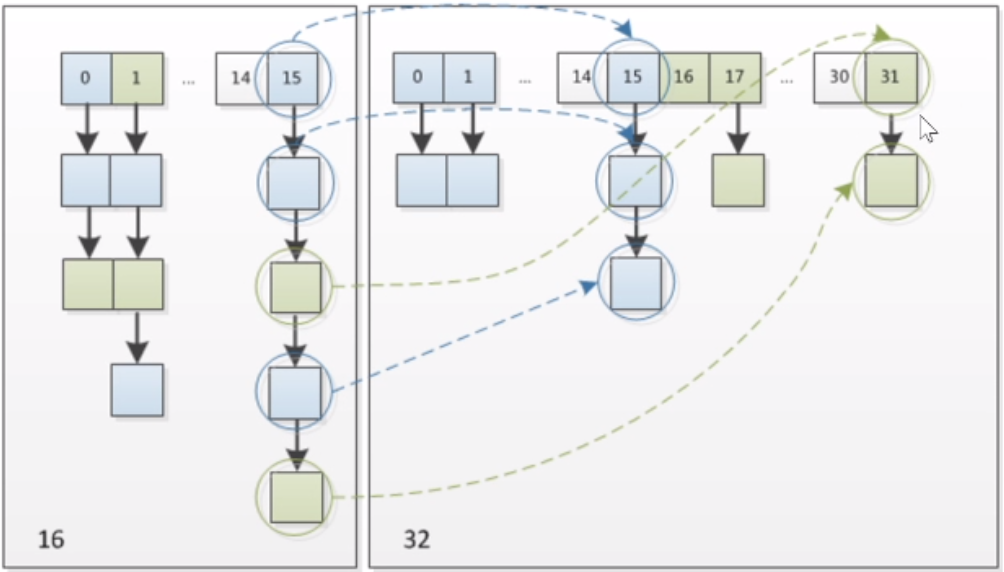
2. TreeMap的底层实现
TreeMap底层采用红黑树结构来实现, 在插入元素时, 需要进行比较. TreeMap允许通过默认比较器或指定比较器对元素进行比较. 元素节点结构如下: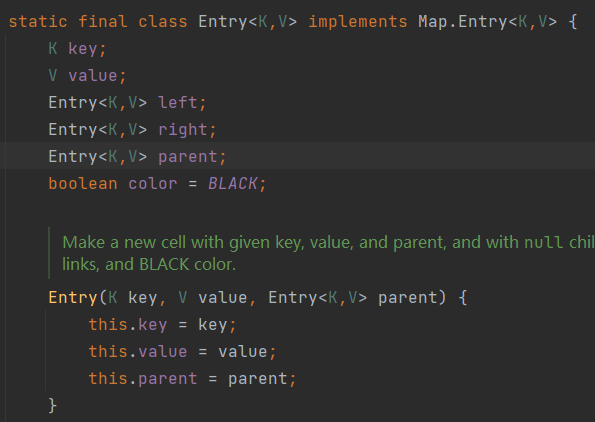
四. CopyOnWriteXXX
以CopyOnWriteArrayList为例, 正如名字所暗示, 底层采用的是写时复制的方式, 当线程对CopyOnWriteXXX集合执行读取操作时, 线程将会直接读取, 无须加锁或阻塞. 当线程对CopyOnWriteXXX集合执行写入操作时, 该集合会在底层复制一份新的数组, 接下来对新的数组执行写入操作, 因此它是线程安全的.
需要知道的是, 由于CopyOnWriteXXX执行写入操作时需要频繁地复制数组, 性能比较差, 但读操作因为无须加锁因此会很快且安全. 由此可见, CopyOnWriteXXX适合用于读取操作远远大于写入操作的场景, 如缓存等.
五. ConcurrentHashMap
JDK7
为了提高并发度,在JDK7中,一个ConcurrentHashMap被拆分为多个子HashMap。每一个子HashMap称作一个
Segment,多个线程操作多个Segment相互独立。在JDK7中的分段锁,有三个好处:
- 减少Hash冲突,避免一个槽里有太多元素。
- 提高读和写的并发度,段与段之间相互独立。
- 提高了扩容的并发度,它不是整个ConcurrentHashMap一起扩容,而是每个Segment独立扩容
缺点是并发度低, 并发度取决于分多少个段.
JDK8
在JDK8中, 并没有对ConcurrentHashMap分段, 而是沿用的HashMap红黑树的结构, 不同的是加锁的粒度不一样, 并非对整个ConcurrentHashMap加锁, 而是对每个头结点分别加锁, 并发度很高.
缺点是并发扩容的难度非常大, 不想JDK7中可以单独对Segment扩容, JDK8相当于只有一个Segment, 当一个线程要扩容数组时, 其他线程还要读写, 处理过程很复杂.

若有收获,就点个赞吧
0 人点赞
