日志分析系统ELK
ELK概述
 ELK是什么?
ELK是什么?
- EIasticsearch:负责日志检索和储存
- Logstash:负责日志的收集和分析、处理
- Kibana:负责日志的可视化
- ELK是一整套解决方案,是三个软件产品的首字母缩写,很多公司都在使用,如:Sina、携程、华为、美团等
- 这三款软件都是开源软件,通常是配合使用,而且又先后归 于Elastic.co公司名下,故被简称为ELK
ELK组件在海量日志系统的运维中,可用于解决
- 分布式日志数据集中式查询和管理
- 系统监控,包含系统硬件和应用各个组件的监控
- 故障排查
- 安全信息和事件管理
-
EIasticsearch 概述
ElasticSearch是一个基于Lucene的搜索服务器。它提供 了一个分布式多用户能力的全文搜索引擎,基于RESTful API 的Web接口
Elasticsearch是用Java开发的,使用Apache许可条款的 开源软件,是当前流行的企业级搜索引擎。设计用于云计 算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便主要特点
实时分析,文档导向,分布式实时文件存储
- 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards和RepIicas)
- 接口友好,支持JSON
- 没有典型意义的事务
-
名词解释
Node:装有一个ES服务器的节点
- CIuster: 有多个Node组成的集群
- Document: 一个可被搜索的基础信息单元
- Index: 拥有相似特征的文档的集合
- Type:一个索引中可以定义一种或多种类型
- Filed:是ES的最小单位,相当于数据的某一列
- Shards:索引的分片,每一个分片就是一个Shard
- RepIicas: 索引的拷贝
部署EIasticsearch
配置ELK软件仓库
[root@ecs-proxy ~]# cp -a elk /var/ftp/localrepo/elk[root@ecs-proxy ~]# cd /var/ftp/localrepo/[root@ecs-proxy localrepo]# createrepo --update .
单机安装
[root@es-0001 ~]# vim /etc/hosts
192.168.1.41 es-0001
[root@es-0001 ~]# yum install -y java-1.8.0-openjdk elasticsearch
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml
55: network.host: 0.0.0.0
[root@es-0001 ~]# systemctl enable --now elasticsearch
[root@es-0001 ~]# curl http://192.168.1.41:9200/ # 服务默认监听9200、9300端口
{
"name" : "War Eagle",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
集群安装
es-0001 … es-0005 所有主机,都要执行以下操作
集群需要在每一台机器上都安装EIasticsearch,过程与单机一样,只有配置文件区别(注意启动顺序)
[root@es-0001 ~]# vim /etc/hosts
192.168.1.41 es-0001
192.168.1.42 es-0002
192.168.1.43 es-0003
192.168.1.44 es-0004
192.168.1.45 es-0005
[root@es-0001 ~]# yum install -y java-1.8.0-openjdk elasticsearch
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml
17: cluster.name: my-es # 集群名字
23: node.name: es-0001 # 本机主机名
55: network.host: 0.0.0.0
68: discovery.zen.ping.unicast.hosts: ["es-0001", "es-0002"]
[root@es-0001 ~]# systemctl enable --now elasticsearch
[root@es-0001 ~]# curl http://192.168.1.41:9200/_cluster/health?pretty
{
"cluster_name" : "my-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 5,
"number_of_data_nodes" : 5,
... ...
}
status: green
- 集群状态,绿色为正常
- 黄色表示有问题但不是很严重,红色表示严重故障
number_of_nodes: 5
- 表示集群中节点的数量
number_of_data_nodes: 5
-
集群配置管理
head插件
它展现ES集群的拓扑结构,并且可以通过它来进行索引 (Index)和节点(Node)级别的操作
- 它提供一组针对集群的查询API,并将结果以json和表格形式返回
- 它提供一些快捷菜单,用以展现集群的各种状态
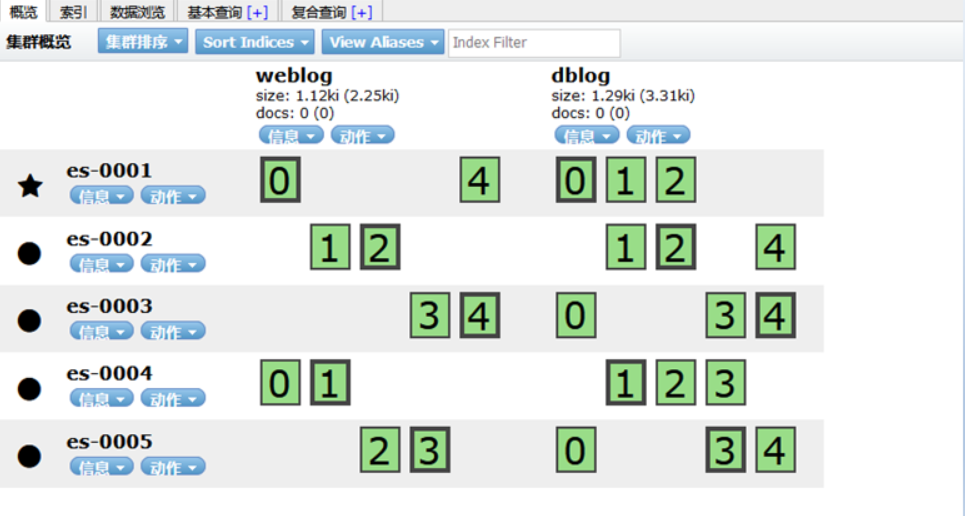
安装 apache,并部署 head 插件
[root@web ~]# yum install -y httpd
[root@web ~]# tar zxf head.tar.gz
[root@web ~]# mv elasticsearch-head /var/www/html/head
[root@web ~]# systemctl enable --now httpd
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
[root@web ~]#
使用华为 ELB, 把 web 服务和 es-0001 的 9200 端口发布到互联网,并通过浏览器访问
es-0001 访问授权
[root@es-0001 ~]# vim /etc/elasticsearch/elasticsearch.yml
# 配置文件最后追加
http.cors.enabled : true
http.cors.allow-origin : "*"
http.cors.allow-methods : OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length
[root@es-0001 ~]# systemctl restart elasticsearch.service
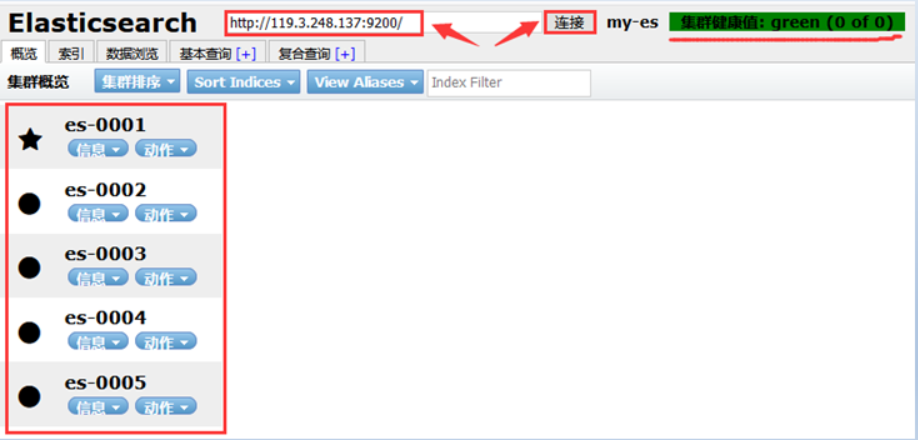
集群API管理
Elasticsearch是用http协议访问
http请求由三部分组成
- 分别是:请求行、消息报头、请求正文
- 请求行:Method Request-URI HTTP-Version CRLF
http请求方法
- 常用方法 GET, POST, HEAD
- 其他方法 OPTIONS, PUT, DELETE, TRACE 和 CONNECT
Elasticsearch使用的请求方法
- 增 —- PUT
- 删 —- DELETE
- 改 —- POST
- 查 —- GET
与EIasticsearch交互的数据需使用json格式
在Iinux中curl是一个利用URL规则在命令行下工作的 文件传输工具,可以说是一款很强大的http命令行工具。
它支持多种请求模式,自定义请求头等强大功能,是一款综合工具
使用格式:
- curI -X请求方法 http://请求地址
- curl -H自定义请求头http://请求地址
_cat关键字用来查询集群状态,节点信息等
- 显示详细信息(?v),显示帮助信息(?help)
例如:查询集群中的master是谁
# 查询支持的关键字 [root@es-0001 ~]# curl -XGET http://es-0001:9200/_cat/ # 查具体的信息 [root@es-0001 ~]# curl -XGET http://es-0001:9200/_cat/master # 显示详细信息 ?v [root@es-0001 ~]# curl -XGET http://es-0001:9200/_cat/master?v # 显示帮助信息 ?help [root@es-0001 ~]# curl -XGET http://es-0001:9200/_cat/master?help创建索引
指定索引的名称,指定分片数量,指定副本数量
创建索引使用 PUT 方法,创建完成以后通过 head 插件验证[root@es-0001 ~]# curl -XPUT -H "Content-Type: application/json" http://es-0001:9200/tedu -d \ '{ "settings":{ "index":{ "number_of_shards": 5, "number_of_replicas": 1 } } }'增加数据
[root@es-0001 ~]# curl -XPUT -H "Content-Type: application/json" http://es-0001:9200/tedu/teacher/1 -d \ '{ "职业": "诗人", "名字": "李白", "称号": "诗仙", "年代": "唐" }'查询数据
[root@es-0001 ~]# curl -XGET http://es-0001:9200/tedu/teacher/1?pretty修改数据
[root@es-0001 ~]# curl -XPOST -H "Content-Type: application/json" \ http://es-0001:9200/tedu/teacher/1/_update -d '{ "doc": {"年代":"公元701"}}'删除数据
# 删除一条 [root@es-0001 ~]# curl -XDELETE http://es-0001:9200/tedu/teacher/1 # 删除索引 [root@es-0001 ~]# curl -XDELETE http://es-0001:9200/tedukibana
kibana是什么
数据可视化平台工具
特点:
- 灵活的分析和可视化平台
- 实时总结流量和数据的图表
- 为不同的用户显示直观的界面
-
kibana安装配置
安装kibana
[root@kibana ~]# vim /etc/hosts 192.168.1.41 es-0001 192.168.1.42 es-0002 192.168.1.43 es-0003 192.168.1.44 es-0004 192.168.1.45 es-0005 192.168.1.46 kibana [root@kibana ~]# yum install -y kibana [root@kibana ~]# vim /etc/kibana/kibana.yml 02 server.port: 5601 07 server.host: "0.0.0.0" 28 elasticsearch.hosts: ["http://es-0002:9200", "http://es-0003:9200"] 37 kibana.index: ".kibana" 40 kibana.defaultAppId: "home" 113 i18n.locale: "zh-CN" [root@kibana ~]# systemctl enable --now kibanakibana绘制图表
数据导入条件:
必须指定 json 格式 Content-Type: appIication/json
- 导入关键字:_buIk
- HTTP方法:POST
- urI 编码格式:data-binary (二进制)
导入日志数据
拷贝云盘 logs.jsonl.gz 到跳板机
[root@ecs-proxy ~]# gunzip logs.jsonl.gz
[root@ecs-proxy ~]# curl -XPOST -H "Content-Type: application/json" http://192.168.1.41:9200/_bulk --data-binary @logs.jsonl
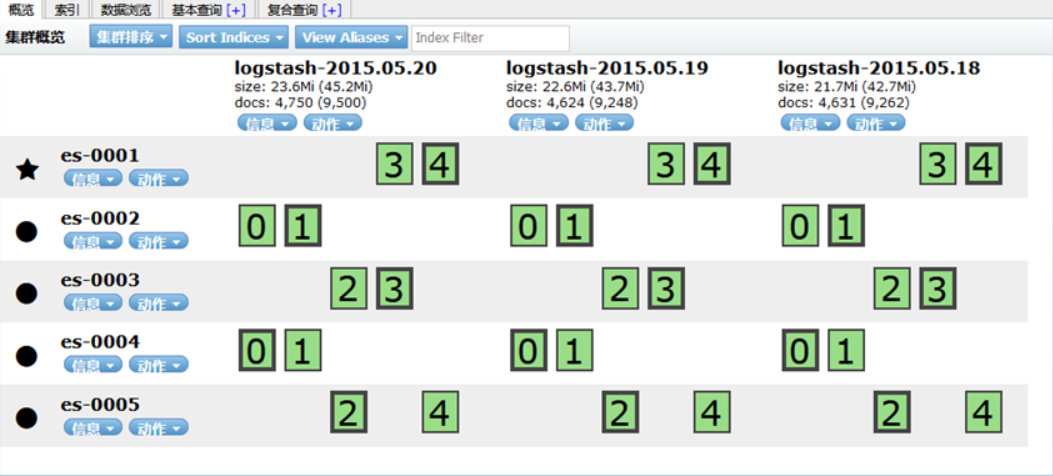
绘制流量图
成功创建会有logstash-*,如图-7所示: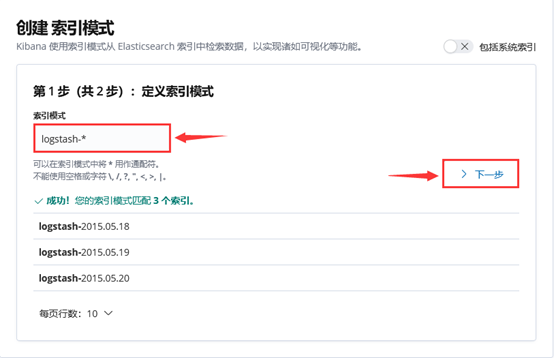
图-7
注意: 这里没有数据的原因是导入日志的时间段不对,默认配置是最近15分钟,在这可以修改一下时间来显示
5)kibana修改时间,选择Lsat 15 miuntes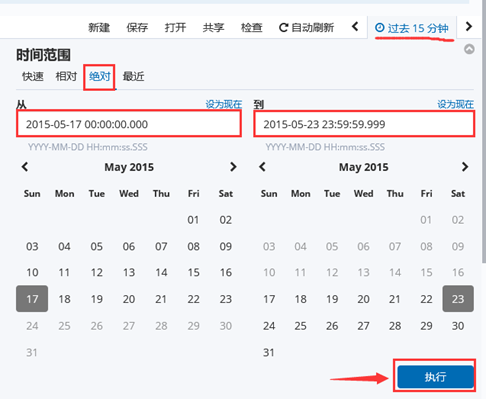
图-8
7)选择时间2015-5-15到2015-5-22,如图-12所示:
8)查看结果,如图-9所示: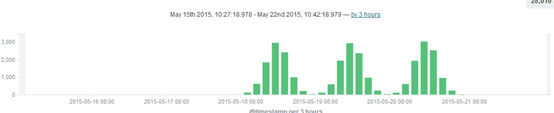
图-9
9)除了柱状图,Kibana还支持很多种展示方式 ,如图-10所示: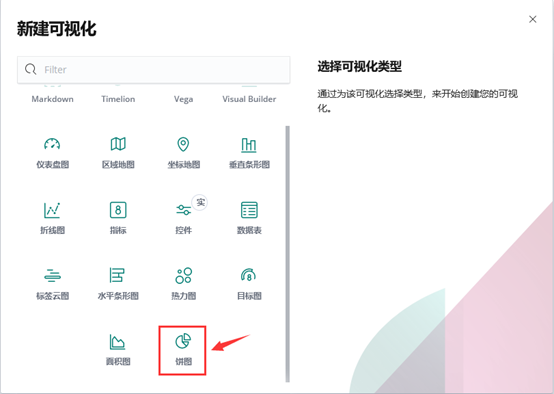
图-10
10)做一个饼图,选择Pie chart,如图-11所示:
11)结果,如图-11所示: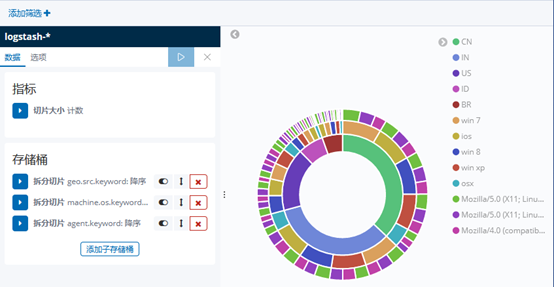
图-11
logstash
logstash安装部署
什么是logstash
- 是一个数据采集、加工处理以及传输的工具
特点
- 所有类型的数据集中处理
- 不同模式和格式数据的正常化
- 自定义日志格式的迅速扩展
- 为自定义数据源轻松添加插件
LogstashI作结构
- input负责收集数据
- filter负责处理数据
-
数据类型和语法
logstash里面的类型
布尔值类型: ss l_enab I e => true
- 字节类型: bytes => “1MiB”
- 字符串类型: name => “xkops”
- 数值类型: port=> 22
- 数组: match => [“datetime”, “UNIX”]
- 哈希(键值对):options => (k => “v”,k2 => “v2”}
- 注释: #
- 等于: ==
- 不等于: !=
- 小于: <
- 大于: >
- 小于等于: <=
- 大于等于: >=
- 匹配正则: =~
- 不匹配正则: !~
- 包含: in
- 不包含: not in
- 与: and
- 或: or
- 非与: nand
- 非或: xor
- 编码类型:codec => “json”
logstash安装
购买云主机
| 主机 | IP地址 | 配置 |
|---|---|---|
| logstash | 192.168.1.47 | 最低配置2核2G |
logstash云主机安装
- Iogstash依赖Java环境,需要安装java-openjdk
- logstash没有默认的配置文件,需要手动配置
- Iogstash安装在/usr/share/1 ogstash 目录下
配置好yum源以后直接使用yum进行安装
Iogstash安装路径 /usr/share/logstash(默认路径)
- 配置文件安装路径/etc/logstash
配置文件格式
vim /etc/logstash/conf. d/my. conf
input {数据输入}
filter {过滤规则}
output {数据导出}
启动命令logstash
- /usr/share/logstash/bin/logstash
基础配置样例
[root@logstash ~]# ln -s /etc/logstash /usr/share/logstash/config
[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
stdin {} # 标准输入,键盘写入
}
filter{ }
output{
stdout{} # 标准输出
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
插件管理
使用插件
- 上面的配置文件使用了 Iogstash- input-stdin和Iogstash-output-stdout 两个插件,logstash 对数据的处 理依赖插件
管理命令 /usr/share/logstash/bin/logstash-pIugin
- 安装插件install
- 删除插件uninstall
- 查看插件Iist
只能用于input段的插件:Iogstash-input-xxx
只能用于output段的插件:Iogstash-output-xxx
只能用于fiIter段的插件:logstash-filter-xxx
编码格式插件:logstash-codec-xxx (字符编码)可以用于所有区域
例如:标准输入的数据是json格式编码
input (
stdin { codec => “json”}
}
在调试软件的时候我们经常把数据输出到标准输出
由于数据是json格式,为了便于阅读我们一般采用 rubydebug格式来查看数据
input{
stdin{ codec => “json” }
}
filter{}
output{
stdout{ codec => “rubydebug” }
}
插件与调试格式
使用json格式字符串测试 {“a”:”1”, “b”:”2”, “c”:”3”}
[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
stdin { codec => "json" } # json格式
}
filter{ }
output{
stdout{ codec => "rubydebug" } # 调试模式格式
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
logstash里面插件众多,不同的插件参数也不同
迅速了解掌握插件的使用方法:参考插件手册
官方手册地址
input插件配置管理
file插件是我们平常应用非常多的插件,他的主要用途是 从本地文件中获取数据,并实时监控文件的变化
文件插件语法格式

[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"] # 必要选项,读取文件路径
type => "test"
start_position => "beginning" # 默认为end,不读取旧的数据,beginnig从头读取
sincedb_path => "/var/lib/logstash/sincedb" #书签文件,下次读取时从书签处读取
}
}
filter{ }
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# rm -rf /var/lib/logstash/plugins/inputs/file/.sincedb_*
[root@logstash ~]# /usr/share/logstash/bin/logstash
filter插件配置管理
grok插件
- 解析各种非结构化的日志数据插件
- grok使用正则表达式把非结构化的数据结构化在分组匹配
- 正则表达式需要根据具体数据结构编写
- 虽然编写困难,但适用性极广
- 几乎可以应用于各类数据
正则表达式分组匹配格式
- 调用格式:(?〈名字〉正则表达式)
调用宏表达式的格式
- 调用格式:%{宏名称:名字}
grok自带的宏定义在:
- /usr/share/logstash/vendor/bundIe/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns

复制一条web日志进行匹配分析
- 小技巧:把日志位置指针文件指向/dev/null可以反复读取测试
- sincedb path => “/dev/null”
使用宏解析Apache默认日志格式样例:
grok {
match => {“message” => “%{HTTPD_COMBINEDLOG}”}
}
[root@logstash ~]# echo '192.168.1.252 - - [29/Jul/2020:14:06:57 +0800] "GET /info.html HTTP/1.1" 200 119 "-" "curl/7.29.0"' >/tmp/c.log
[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
file {
path => ["/tmp/c.log"]
type => "test"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter{
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
output插件配置管理
elasticsearch插件是我们日志分析系统的数据输出插件, 他的主要用途是把通过filter处理过的json数据写入到 eIasticsearch 集群中
elasticsearch插件语法格式
output {
elasticsearch { 参数=> “参数值”
}
核心参数
- hosts eIasticsearch节点的地址,数组格式
- hosts => [“es-0004:9200”, “es-0005:9200”]
- index存储数据索引的名称
- index => “weblog”
index还支持安日期生成索引,其中YYYY表示年,MM表示月份,dd表示日期
- index => “weblog-%(+YYYY.MM.dd)”
浏览器打开 head 插件,通过 web 页面浏览验证http://公网IP:9200/_plugin/head/[root@logstash ~]# vim /etc/logstash/conf.d/my.conf input { file { path => ["/tmp/c.log"] type => "test" start_position => "beginning" sincedb_path => "/dev/null" } } filter{ grok { match => { "message" => "%{HTTPD_COMBINEDLOG}" } } } output{ stdout{ codec => "rubydebug" } elasticsearch { hosts => ["es-0004:9200", "es-0005:9200"] index => "weblog-%{+YYYY.MM.dd}" } } [root@logstash ~]# /usr/share/logstash/bin/logstash远程获取WEB日志
beats插件
如何收集日志?
由于logstash依赖JAVA环境,而且占用资源非常大,因此 在每一台web服务器上部署logstash非常不合适
我们可以使用更轻量的filebeat收集日志,通过网络给 logstash发送数据
logstash使用beats接收日志,完成分析
logstash接收日志
- index => “weblog-%(+YYYY.MM.dd)”
如果想接收数据,必须监听网络服务。logstash可以通过beats插件接收fiIebeats发送过来的数据
beats插件配置样例
input {
beats {
port => 5044
}
}
[root@logstash ~]# vim /etc/logstash/conf.d/my.conf
input {
stdin { codec => "json" }
file{
path => ["/tmp/c.log"]
type => "test"
start_position => "beginning"
sincedb_path => "/var/lib/logstash/sincedb"
}
beats {
port => 5044
}
}
filter{
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output{
stdout{ codec => "rubydebug" }
elasticsearch {
hosts => ["es-0004:9200", "es-0005:9200"]
index => "weblog-%{+YYYY.MM.dd}"
}
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
filebeat安装配置
web服务器安装fiIebeat
- yum -y install filebeat
设置开机运行/启动服务
- systemctl enable filebeat
配置文件路径
- /etc/fiIebeat/fiIebeat.yml
修改配置文件 /etc/fiIebeat/fiIebeat.yamI
-注意:配置文件采用yamI语法,注意空格缩进
- 24: enabled: true #打开收集模块
- 28: - /var/log/httpd/access_log # 定义日志路径
- 45: fields:
- 46: my type: apache # 自定义标签
- 148, 150注释掉
- 161: output.logstash: # 设置输出模块
- 163: hosts: [ “logstash主机IP5044” ] # 输出给logstash
- 180, 181, 182注释掉 #收集的其他信息

[root@web ~]# yum install -y filebeat
[root@web ~]# vim /etc/filebeat/filebeat.yml
24: enabled: true
28: - /var/log/httpd/access_log
45: fields:
46: my_type: apache
148, 150 注释掉
161: output.logstash:
163: hosts: ["192.168.1.47:5044"]
180, 181, 182 注释掉
[root@web ~]# grep -Pv "^\s*(#|$)" /etc/filebeat/filebeat.yml
[root@web ~]# systemctl enable --now filebeat
web日志实时数据分析
目标:
- 实现web日志流量实时分析
- 通过kibana绘制图表展示web访问情况
实施步骤:
步骤1 :
- 在web服务器上安装fiIebeat,并把日志发送给logstash
- logstash使用beats模块接收日志
步骤2:
- Iogstash — input 配置 beats 收集日志
- Iogstash — fiIter对日志格式化
- logstash — output 写入日志到 eIasticsearch
步骤3:
- kibana从eIasticsearch读取日志图表展示
1、停止 kibana 服务
[root@kibana ~]# systemctl stop kibana
2、清空 elasticsearch 中日志数据
[root@kibana ~]# curl -XDELETE http://es-0001:9200/weblog-*
访问 web 页面,浏览器打开 head 插件,通过 web 页面浏览验证
3、配置 web 日志,获取用户真实IP
通过 ELB 把 web 服务发布公网
https://support.huaweicloud.com/elb_faq/elb_faq_0090.html
4、配置 filebeat
详见配置文件 filebeat.yml
重启服务
[root@web ~]# systemctl restart filebeat
5、配置 logstash
详见配置文件 logstash.conf
启动服务
[root@logstash ~]# cat /etc/logstash/conf.d/my.conf
input {
beats {
port => 5044
}
}
filter{
if [fields][my_type] == "apache" {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}}
}
output{
#stdout{ codec => "rubydebug" }
if [fields][my_type] == "apache" {
elasticsearch {
hosts => ["es-0004:9200", "es-0005:9200"]
index => "weblog-%{+YYYY.MM.dd}"
}}
}
[root@logstash ~]# /usr/share/logstash/bin/logstash
6、配置 kibana
启动服务,通过web页面配置 kibana
[root@kibana ~]# systemctl start kibana
常见错误
使用通配符删除报错
[root@es-0001 ~]# curl -XDELETE http://localhost:9200/*
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"Wildcard expressions or all indices are not allowed"}],"type":"illegal_argument_exception","reason":"Wildcard expressions or all indices are not allowed"},"status":400}
# 由于设置了destructive_requires_name 参数,不允许使用通配符
# 查看及解决方式
[root@es-0001 ~]# curl -XGET http://es-0001:9200/_cluster/settings?pretty
{
"persistent" : {
"action" : {
"destructive_requires_name" : "true"
}
},
"transient" : { }
}
[root@es-0001 ~]# curl -XPUT http://localhost:9200/_cluster/settings -d '
{
"persistent": {
"action": {
"destructive_requires_name": "false"
}
}
}'
[root@es-0001 ~]# curl -XDELETE http://localhost:9200/*
{"acknowledged":true}
大数据与Hadoop
大数据简介
随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快,随着互联网、物联网建设的加快,信息更是爆炸是增长,收集、检索、统计这些信息越发困难,必须使用新的技术来解决这些问题
什么大数据
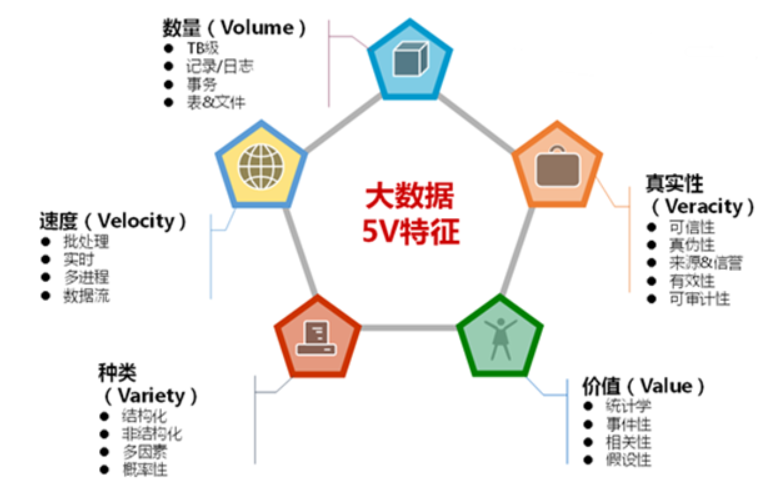
- 大数据指无法在一定时间范围内用常规软件工具进行捕捉、 管理和处理的数据集合,需要新处理模式才能具有更强的决 策力、洞察发现力和流程优化能力的海量、高增长率和多样 化的信息资产
是指从各种各样类型的数据中,快速获得有价值的信息
大数据能做什么
- 企业组织利用相关数据分析帮助他们降低成本、提高效率、 开发新产品、做出更明智的业务决策等
- 把数据集合并后进行分析得出的信息和数据关系性,用来察 觉商业趋势、判定研究质量、避免疾病扩散、打击犯罪或测定即时交通路况等
- 大规模并行处理数据库,数据挖掘电网,分布式文件系统或数据库,云计算平和可扩展的存储系统等
Hadoop概述
Hadoop是什么
- Hadoop是一种分析和处理海量数据的软件平台
- Hadoop是一款开源软件,使用JAVA开发
- Hadoop可以提供一个分布式基础架构
Hadoop特点
- 高可靠性、高扩展性、高效性、高容错性、低成本
2003年开始GoogIe陆续发表了3篇论文
- GFS, MapReduce, BigTabIe
GFS
- GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用
- 可以运行于廉价的普通硬件上,提供容错功能
MapReduce
- MapReduce是针对分布式并行计算的一套编程模型,由Map和 Reduce组成,Map是映射,把指令分发到多个worker上, Reduce是规约,把worker计算出的结果合并
BigTable
- BigTable是存储结构化数据的数据库
- BigTable 建立在 GFS, Scheduler, Lock Service 和 MapReduce 之上
GFS、 MapReduce 和 BigTabIe 三大技术被称为 Google 的三驾马车,虽然没有公布源码,但发布了这三个产品的 详细设计论
Yahoo资助的一个组织按照这三篇论文使用Java做了开 源的hadoop,但在性能上Hadoop比Google要差很多
- GFS > HDFS
- MapReduce > MapReduce
- BigTable > Hbase
Hadoop组件介绍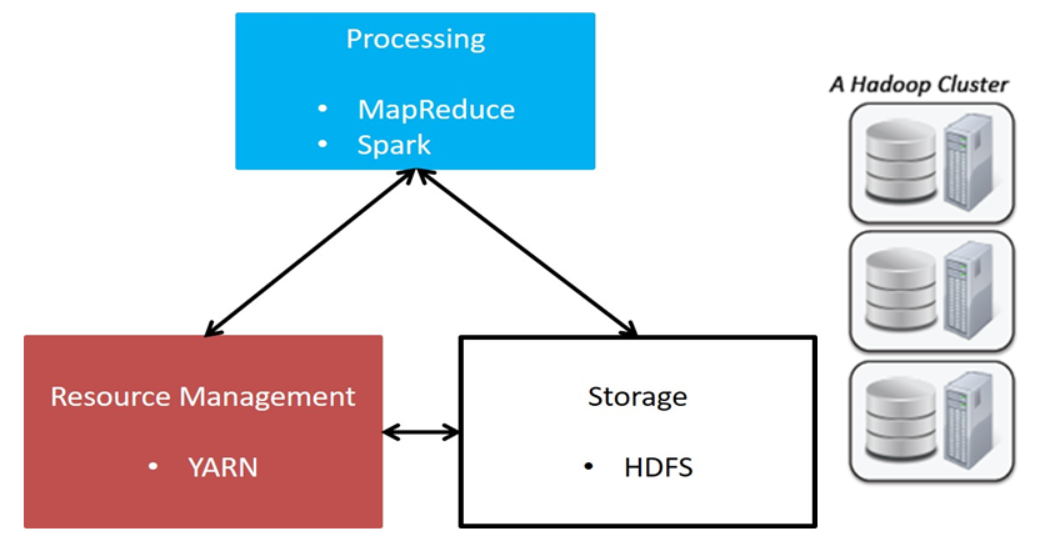
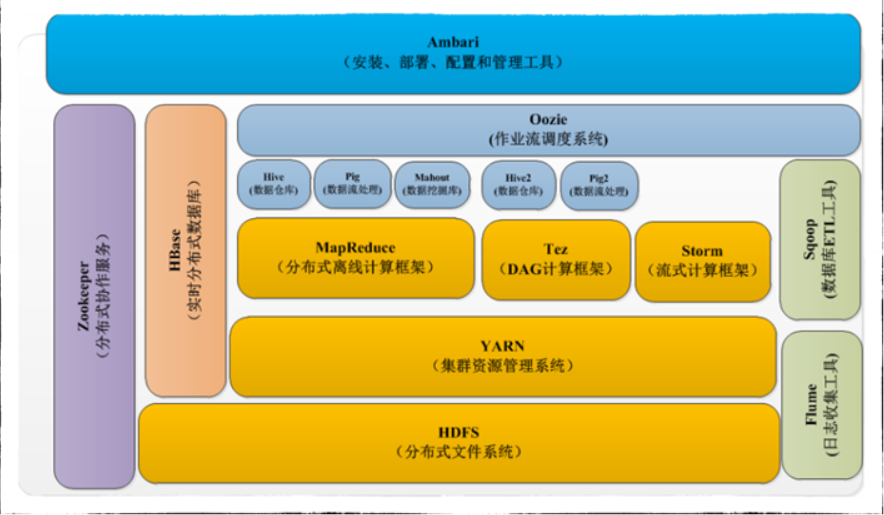
- HDFS:分布式文件系统(核心组件)
- MapReduce:分布式计算框架(核心组件)
- Yarn:集群资源管理系统(核心组件)
- Zookeeper :分布式协作服务
- kafka:分布式消息队列
- Hive:基于Hadoop的数据仓库
-
简单数据分析
单机安装部署
Hadoop的部署模式有三种
单机 在一台机器上安装部署
- 伪分布式 在一台机器上安装部署,但区分角色
- 完全分布式 多机部署,不同角色服务安装在不同的机器上
1、安装配置Java环境及jps工具
- 安装 Openjdk 和 Openjdk-deveI
- yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
2、获取软件、解压拷贝到指定位置
- 官网地址:http://hadoop. apache.org
- tar -zxf hadoop-2.7.6.tar.gz
- mv hadoop-2.7.6 /usr/local/hadoop
hadoop使用java执行,必须要配置java安装路径
hadoop 配置文件路径 /usr/local/hadoop/etc/hadoop
hadoop-env. sh是启动hadoop的默认环境变量配置文件
- JAVA_HOME=”JAVA 安装路径”
- HADOOP_CONF_DIR=”hadoop 配置文件路径”
验证
- /usr/local/hadoop/bin/hadoop version
hadoop安装
拷贝云盘 public/hadoop/hadoop-2.7.7.tar.gz 到 hadoop1 上
[root@hadoop1 ~]# yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
[root@hadoop1 ~]# tar -zxf hadoop-2.7.7.tar.gz
[root@hadoop1 ~]# mv hadoop-2.7.7 /usr/local/hadoop
[root@hadoop1 ~]# chown -R 0.0 /usr/local/hadoop
配置JAVA运行环境
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
25: export JAVA_HOME="/usr"
33: export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop version
单机数据分析
1、收集数据
2、分析
3、查看分析结果
热点词汇分析
[root@hadoop1 ~]# cd /usr/local/hadoop
[root@hadoop1 hadoop]# mkdir input
[root@hadoop1 hadoop]# cp *.txt input/
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount ./input ./output
[root@hadoop1 hadoop]# cat ./output/*
分布式文件系统-HDFS安装部署
HDFS架构图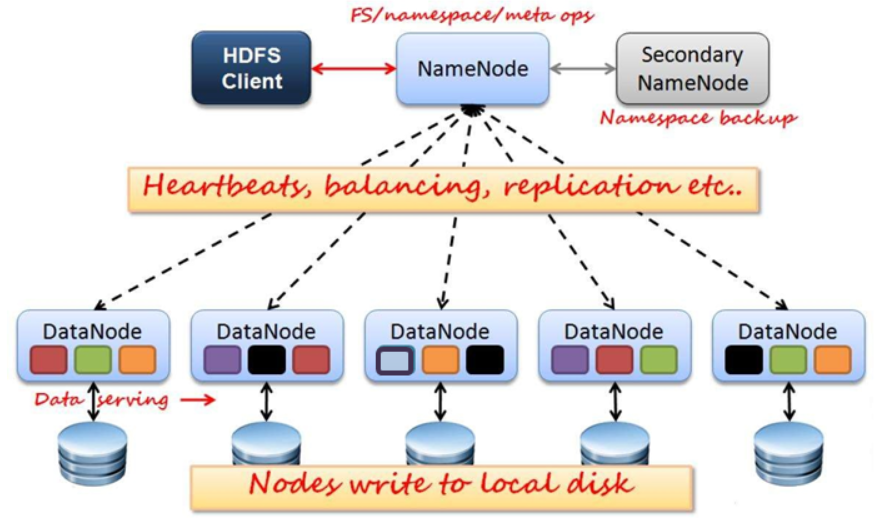
HDFS角色介绍
HDFS是Hadoop体系中数据存储管理的基础,是一个高度容错的系统,用于在低成本的通用硬件上运行
HDFS角色和概念
- CIient
- Namenode
- Secondarynode
- Datanode
CIient角色:
- CIient
- 切分文件,访问HDFS
- 与NameNode交互,获取文件位置信息
- 与DataNode交互,读取和写入数据
- BIock
- 每块缺省128MB大小
- 每块可以多个副本
namenode与datanode
- NameNode
- Master节点
- 管理HDFS的名称空间和数据块映射信息(fsimage)
- 配置副本策略,处理所有客户端请求
- DataNode
- 数据存储节点,存储实际的数据
- 汇报存储信息绐NameNode
Secondary NameNode
- 定期合并fsimage和fsedits,推送给NameNode
- fsimage:名称空间和数据库的映射信息
- fsedits:数据变更日志
- 紧急情况下,可辅助恢复NameNode
但Secondary NameNode并非NameNode的热备
系统环境部署
禁用 seIinux
修改配置文件(/etc/seIinux/config)以后重启机器生效
- SELINUX=disabled
禁用 firewal Id
- systemctl stop firewalId
- systemctl mask firewalId
安装 java-1.8. 0-openjdk-devel
- yum install -y java-1.8.0-openjdk-devel
主机名配置
- hadoop非常依赖主机名的解析,如果配置dns解析主机名, 不光需要正向解析,还需要添加反向解析,这里我们使用 /etc/hosts文件来解析主机名
- /etc/hosts所有主机都需要修改
以下操作所有机器都要执行
[root@hadoop1 ~]# yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.51 node-0001
192.168.1.52 node-0002
192.168.1.53 node-0003
以下操作仅在 hadoop1 上执行
ssh密钥
hadoop是远程在其他节点上启动角色的
每台机器都要能免密登录,包括本机! ! !
- ssh-keygen -t rsa -b 2048 -N ‘’ -f /root/.ssh/id rsa
- ssh-copy-id /root/.ssh/id rsa.pub 集群所有主机
-第一次使用ssh登陆远程主机的时候需要输入yes,造成主机 不能继续执行,禁用ssh key检测
—/etc/ssh/ssh_conf i g (NameNode主机增加配置)
StrictHostKeyChecking no
[root@hadoop1 ~]# vim /etc/ssh/ssh_config
# 60行新添加
StrictHostKeyChecking no
[root@hadoop1 ~]# ssh-keygen -t rsa -b 2048 -N '' -f /root/.ssh/id_rsa
[root@hadoop1 ~]# for i in hadoop1 node-{0001..0003};do
ssh-copy-id -i /root/.ssh/id_rsa.pub ${i}
done
HDFS安装部署
HDFS配置文件
- 环境配置文件: hadoop-env. sh
- 核心配置文件: core-site. xml
- HDFS配置文件: hdfs-site. xml
- 节点配置文件: slaves
环境配置文件
修改 hadoop-env. sh
- JAVA_HOME= “JAVA安装路径”
HADOOP_CONF_DIR=”hadoop 配置文件路径”
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh 25: export JAVA_HOME="/usr" 33: export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"验证
/usr/local/hadoop/bin/hadoop vers ion
节点配置文件
- slaves是datanode节点的配置文件,声明的主机都会运行 datanode守护进程
slaves格式:每行一个主机名(必须能ping通)
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/slaves node-0001 node-0002 node-0003xml语法格式官方手册
XML 指可扩展标记语言(Extensible Markup Language)
- XML中的每个元素名都是成对出现的。结束标签前加一个/
hadoop配置语法
<property> <name></name> <value></value> </property>核心配置文件core-site. xml
fs.defaultFS:文件系统配置参数
hadoop.tmp.dir:数据目录配置参数
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop</value> </property> </configuration>HDFS配置文件 hdfs-site. xml
dfs.namenode.http-address: namenode 地址
- secondarynamenode: secondary namenode 地址
dfs.repIication:副本数量
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.namenode.http-address</name> <value>hadoop1:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop1:50090</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>同步配置文件
hdfs集群所有节点配置文件是相同的! ! !
- 我们在namenode上配置完成以后,把hadoop文件夹拷贝 到其他主机即可
- 拷贝 hadoop 文件夹到 node- {0001. . 0003}
创建数据目录,只在namenode上创建即可,其他 datanode主机可自动创建
- mkdir /var/hadoop
格式化hdfs (只在namenode做)
- /usr/local/hadoop/bin/hdfs namenode -format
启动集群(只在namenode做)
- /usr/local/hadoop/sbin/start-dfs.sh
验证集群配置 ```shell[root@hadoop1 ~]# for i in node-{0001..0003};do rsync -aXSH --delete /usr/local/hadoop ${i}:/usr/local/ done # a归档模式 X权限 SH软硬连接 [root@hadoop1 ~]# mkdir /var/hadoop [root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs namenode -format # 格式化,重复格式化需要清空目录 [root@hadoop1 ~]# /usr/local/hadoop/sbin/start-dfs.sh验证角色
[root@hadoop1 ~]# for i in hadoop1 node-{0001..0003};doecho ${i}; ssh ${i} jps; echo -e "\n"; done验证集群
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report … …
Live datanodes (3):

<a name="cNgJk"></a>
### 日志与拍错
日志文件夹在系统启动时会被自动创建
- /usr/local/hadoop/logs
日志名称
- 服务名-用户名-角色名-主机名.out 标准输出
- 服务名-用户名-角色名-主机名. log 日志信息
<a name="OsRuc"></a>
## 分布式计算框架-Mapreduce
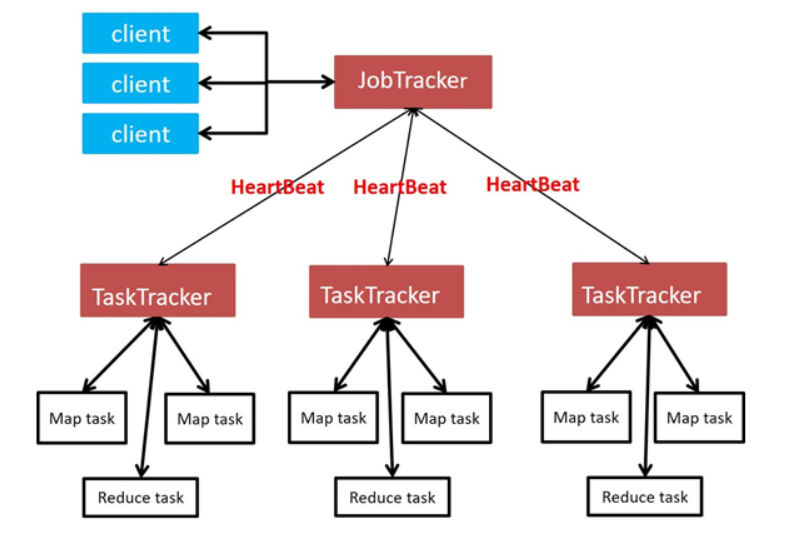<br />**Mapreduce角色**
- Job Tracker
- Task Tracker
- Map Task
- Reducer Task
**JobTracker**
- Master节点只有一个
- 管理所有作业/任务的监控、错误处理等
- 将任务分解成一系列任务,并分派给TaskTracker
**TaskTracker**
- Slave节点,一般是多台
- 运行Map Task和Reduce Task
- 并与JobTracker交互,汇报任务状态
**Map Task**
- -解析每条数据记录,传递给用户编写的map()并执行,
- -将输出结果写入本地磁盘,如果为map-only作业,直接写入 HDFS
**Reducer Task**
- 从Map Task的执行结果中,远程读取输入数据,对数据进行 排序,将数据按照分组传递给用户编写的reduce函数执行
<a name="nRnKZ"></a>
### 配置计算框架
计算框架有多种,例如Mapreduce、storm、spark,—般 由开发人员根据企业需求编写<br />我们使用官方提供的模板案例<br />拷贝Mapreduce模板
```shell
[root@hadoop1 ~]# cd /usr/local/hadoop/etc/hadoop/
[root@hadoop1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hadoop1 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
资源管理组件-Yarn
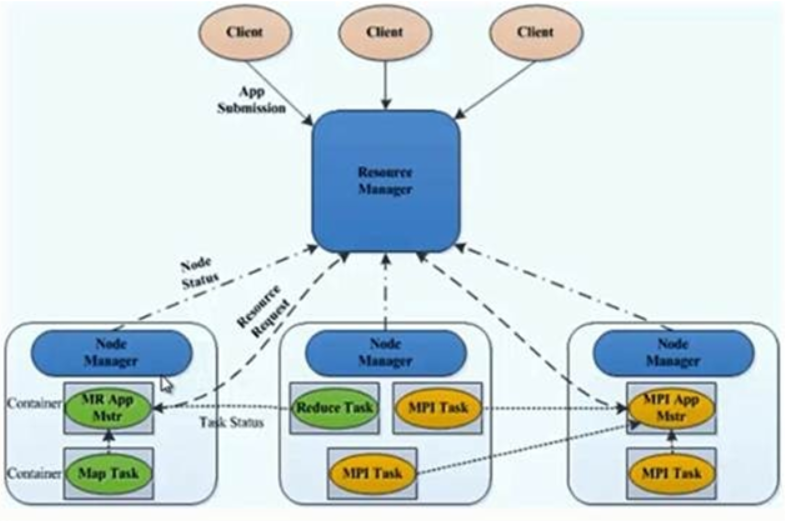
Yarn角色
Resourcemanager
- AppIicationMaster
- Container
Nodemanager
ResourceManager
- 处理客户端请求,资源分配与调度
- 启动/监控 ApplicationMaster
- 监控 NodeManager
NodeManager
- 单个节点上的资源管理
- 处理来自ResourceManager的命令
-
安装部署Yarn
资源调配
Container
- 对任务运行行环境的抽象,封装了CPU、内存等 启动命令等I壬务运行相关的信息资源分配与调度
- AppIicationMaster
- 数据切分
- 为应用程序申请资源,并分配给内部任务
- 任务监控与容错
系统规划
配置yarn-site.xml
- yarn.resourcemanager.hostname 管理主机
yarn.nodemanager.aux-services 计算框架
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop1</value> </property> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>验证集群配置
同步配置到所有node主机,并启动服务[root@hadoop1 ~]# for i in hadoop1 node-{0001..0003};do echo ${i}; ssh ${i} jps; echo -e "\n"; done [root@hadoop1 ~]# /usr/local/hadoop/bin/yarn node -list Total Nodes:3 Node-Id Node-State Node-Http-Address Number-of-Running-Containers node-0003:33212 RUNNING node-0003:8042 0 node-0001:40201 RUNNING node-0001:8042 0 node-0002:38830 RUNNING node-0002:8042 0web页面访问
namenode: http://hadoop1:50070
secondarynamenode: http://hadoop1:50090
resourcemanager: http://hadoop1:8088/cluster重新初始化集群
警告:该方法会丢失所有数据
1、停止集群 /usr/local/hadoop/sbin/stop-all.sh
2、删除所有节点的 /var/hadoop/*
3、在 hadoop1 上重新格式化 /usr/local/hadoop/bin/hdfs namenode -format
4、启动集群 /usr/local/hadoop/sbin/start-all.sh[root@hadoop1 ~]# /usr/local/hadoop/sbin/stop-all.sh [root@hadoop1 ~]# for i in hadoop1 node-{0001..0003};do ssh ${i} 'rm -rf /var/hadoop/*' done [root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs namenode -format [root@hadoop1 ~]# /usr/local/hadoop/sbin/start-all.sh数据分析
HDFS文件系统管理
访问文件系统
web页面能查看,能读取,不能写入
命令行
- 能查看,能读取,能写入
- /usr/local/hadoop/bin/hadoop fs -命令
hdfs管理命令
查看文件和目录
- 如果访问路径不指定前缀默认读取fs.defaultFS参数
- 访问本地文件系统请使用file://
- /usr/local/hadoop/bin/hadoop fs -Is hdfs://hadoop1:9000/
- /usr/local/hadoop/bin/hadoop fs -Is /
创建文件夹
- /usr/local/hadoop/bin/hadoop fs -mkdir /input
创建文件
- /usr/local/hadoop/bin/hadoop fs -touchz /input/tfile
上传文件
- /usr/local/hadoop/bin/hadoop fs -put *.txt /input/
下载文件
- /usr/local/hadoop/bin/hadoop fs -get /tfile /tmp/tfile
删除文件
- /usr/local/hadoop/bin/hadoop fs -rm /tmp/tfile
删除文件夹
/usr/local/hadoop/bin/hadoop fs -rmdir /dir1
使用集群分析数据
调用集群分析数据
创建了目录,并上传文件/usr/local/hadoop/bin/hadoop fs -mkdir /input
- /usr/local/hadoop/bin/hadoop fs -put *.txt /input/
分析上传的文件,找出出现次数最多的单词
- /usr/local/hadoop/bin/Hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
查看结果
/usr/local/hadoop/bin/hadoop fs -cat /output/*
节点管理
增加与修复节点
新增datanode
HDFS新增节点(运行环境)
启动一个新的系统,设置SSH免密码登录
- 在所有节点修改/etc/hosts,增加新节点的主机信息
- 安装 java 运行环境(java-1.8.0-openjdk-devel )
- 拷贝NamNode的/usr/local/hadoop到新节点
- 同步配置文件到所有机器
在新节点启动DataNode
- /usr/local/hadoop/sbin/hadoop-daemon.sh start datanode
设置带宽,平衡数据
- /usr/local/hadoop/bin/hdfs dfsadmin -setBalancerBandwidth 500000000
- /usr/local/hadoop/sbin/start-balancer.sh
查看状态
- /usr/local/hadoop/bin/hdfs dfsadmin -report
在hadoop1执行
[root@hadoop1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.1.54
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.51 node-0001
192.168.1.52 node-0002
192.168.1.53 node-0003
192.168.1.54 newnode
[root@hadoop1 ~]# for i in node-{0001..0003} newnode;do
rsync -av /etc/hosts ${i}:/etc/
done
[root@hadoop1 ~]# rsync -aXSH /usr/local/hadoop newnode:/usr/local/
在 newnode 节点执行
[root@newnode ~]# yum install -y java-1.8.0-openjdk-devel
[root@newnode ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh start datanode
[root@newnode ~]# /usr/local/hadoop/bin/hdfs dfsadmin -setBalancerBandwidth 500000000
[root@newnode ~]# /usr/local/hadoop/sbin/start-balancer.sh
[root@newnode ~]# /usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager
[root@newnode ~]# jps
1186 DataNode
1431 NodeManager
1535 Jps
验证集群(hadoop1上执行)
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
... ...
-------------------------------------------------
Live datanodes (4):
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn node -list
... ...
Total Nodes:4
新增nodemanager
由于nodemanager不负责保存数据,所以增加节点相对简单,环境配置与datanode—致
增加节点(newnode)
- /usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager
查看节点(ResourceManager)
如果旧节点数据丢失,新节点可以自动恢复数据
上线以后会自动恢复数据,如果数据量非常巨大,需要一 段时间
修复节点的过程与新增节点一致
删除节点
删除datanode
datanode删除步骤
- 迁移数据
- 删除节点
配置hdfs-site.xml
删除主机列表dfs. hosts.excIude
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml <property> <name>dfs.hosts.exclude</name> <value>/usr/local/hadoop/etc/hadoop/exclude</value> </property>编辑删除列表文件
[root@localhost~]# cat j/usr/local/hadoop/etc/hadoop/exclude
newnode
在namenode上更改完配置文件就可以迁移数据了,这里 不需要同步配置文件
- /usr/local/hadoop/bin/hdfs dfsadmin -refreshNodes
查看状态status
/usr/local/hadoop/bin/hdfs dfsadmin -report
# 在删除配置文件中添加 newnode [root@hadoop1 ~]# echo newnode >/usr/local/hadoop/etc/hadoop/exclude # 迁移数据 [root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -refreshNodes # 查看状态,仅当节点状态为 Decommissioned 时候才可以下线 [root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report三种状态
NormaI :正常状态
- Decommissioned in Progress: 数据正在迁移
- Decommissioned:数据迁移完成
注意:仅当状态变成Decommissioned才能down机下线
# 下线节点(newnode执行)
[root@newnode ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop datanode
[root@newnode ~]# /usr/local/hadoop/sbin/yarn-daemon.sh stop nodemanager
删除datamanager
在Hadoop2. x中yarn节点管理变得非常简单
nodemanager只负责计算,不保存数据,直接删除即可
- /usr/local/hadoop/sbin/yarn-daemon.sh stop nodemanager
NFS网关服务
NFS网关概述
NFS网关的用途
- 用户可以通过操作系统兼容的本地NFSv3客户端来浏览HDFS 文件系统
- 用户可以通过挂载点直接流化数据
- 允许HDFS作为客户端文件系统的一部分被挂载
- -支持文件附加,但是不支持随机写(nolock)
NFS网关目前只支持NFSv3和TCP协议(vers=3, proto=tcp)
 代理用户
代理用户代理用户是NFS网关访问集群的授权用户
- 在NameNode和NFSGW上添加代理用户
- 代理用户的UID, GID,用户名必须完全相同
- 如果因特殊原因用户UID、GID、用户名不能保持一致,需要 我们配置nfs. map的静态映射关系
例如:
在安全模式下,Kerberos keytab中的用户是代理用户
- 在非安全模式下,运行网关进程的用户必须是代理用户
在NameNode和NFSGW上代理用户的UID、GID、用户名必须完全相同
[root@hadoop1 ~]# groupadd -g 800 nfsuser [root@hadoop1 ~]# useradd -g 800 -u 800 -r -d /var/hadoop nfsuser #---------------------------------------------------------------- [root@nfsgw ~]# groupadd -g 800 nfsuser [root@nfsgw ~]# useradd -g 800 -u 800 -r -d /var/hadoop nfsuserHDFS集群授权
代理用户授权,配置core-site.xmlhadoop. proxyuser.{代理用户}.groups #挂载点组授权
- hadoop. proxyuser.{代理用户}.hosts #挂载点主机授权
停止hadoop集群
- /usr/local/hadoop/sbin/stop-all.sh
同步配置到所有node主机
- rsync -aXSH —delete /usr/local/hadoop node(X):/usr/local/
启动集群
- /usr/local/hadoop/sbin/start-dfs.sh
角色验证(所有集群机器)
- jps
集群验证(能看到3个node节点)
- /usr/local/hadoop/bin/hdfs dfsadmin -report
```shell
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
<name>fs.defaultFS</name> <value>hdfs://hadoop1:9000</value><name>hadoop.tmp.dir</name> <value>/var/hadoop</value><name>hadoop.proxyuser.nfsuser.groups</name> <value>*</value><name>hadoop.proxyuser.nfsuser.hosts</name> <value>*</value>
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-dfs.sh [root@hadoop1 ~]# jps 5925 NameNode 6122 SecondaryNameNode 6237 Jps [root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report … …rsync -avXSH /usr/local/hadoop/etc ${i}:/usr/local/hadoop/ done
Live datanodes (3):
<a name="S5Cvy"></a>
### 搭建NFS网关
nfsgw网关服务
- portmap服务(与系统rpcbind冲突)
- nfs3服务(与系统nfs冲突)
- 卸载NFSGW的rpcbind与nfs-utils
- yum remove -y rpcbind nfs-utils
NFS网关具有双重角色,他既是一个HDFS的客户端程序, 又是一个NFS服务器,所以NFS网关必须能访问到集群中的 所有节点,配置/etc/hosts<br />NFS网关配置
- NFS网关同样需要Hadoop的相关配置文件
- 同步NameNode的hadoop安装目录到NFSGW
- rsync -aXSH —delete hadoopl:/usr/local/hadoop /usr/local/
- 安装 JAVA 运行环境(java-1.8. 0-open jdk-devel )
- yum install -y java-1.8.0-openjdk-devel
```shell
[root@nfsgw ~]# yum remove -y rpcbind nfs-utils
[root@nfsgw ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.51 node-0001
192.168.1.52 node-0002
192.168.1.53 node-0003
192.168.1.55 nfsgw
[root@nfsgw ~]# yum install -y java-1.8.0-openjdk-devel
[root@nfsgw ~]# rsync -aXSH --delete hadoop1:/usr/local/hadoop /usr/local/
nfs.exports授权
- nfs. exports.allowed.hosts
- 默认情况下,export可以被任何客户端挂载。为了更好的控 制访问,可以设置属性。值和字符串对应机器名和访问策略, 通过空格来分割。机器名的格式可以是单一的主机、Java的 正则表达式或者IPv4地址
- 使用rw或ro可以指定导出目录的读写或只读权限。
- 默认设置为只读权限
nfs.dump配置
- nfs.dump.dir
- 用户需要更新文件转储目录参数。NFS客户端经常重新安排写操作,顺序的写操作会随机到达NFS网关。这个目录常用 于临时存储无序的写操作。对于每个文件,无序的写操作会 在他们积累在内存中超过一定阈值(如,1M)时被转储。需要确保有足够的空间的目录
- NFS网关在设置该属性后需要重启
修改hdfs配置文件hdfs-site. xml
- nfs.exports.allowed.hosts #访问策略及读写权限
nfs.dump.dir #文件转储目录
[root@nfsgw ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml <configuration> ..... <property> <name>nfs.exports.allowed.hosts</name> <value>* rw</value> </property> <property> <name>nfs.dump.dir</name> <value>/var/nfstmp</value> </property> </configuration>创建转储目录
mkdir /var/nfstmp
为代理用户授权
- chown nfsuser:nfsuser /var/nfstmp
在日志文件夹为代理用户授权
- rm -f /usr/local/hadoop/logs/*
setfacl -m user:nfsuser:rwx /usr/local/hadoop/logs
[root@nfsgw ~]# mkdir /var/nfstmp [root@nfsgw ~]# chown nfsuser:nfsuser /var/nfstmp [root@nfsgw ~]# rm -rf /usr/local/hadoop/logs/* [root@nfsgw ~]# setfacl -m user:nfsuser:rwx /usr/local/hadoop/logs [root@nfsgw ~]# getfacl /usr/local/hadoop/logs特别注意:
启动portmap需要使用root用户
- 启动nfs3需要使用core-site里面设置的代理用户
- 必须为代理用户授权
- /var/nfstmp不授权上传文件会出错
- /usr/locaI/hadoop/logs不授权看不到报错日志
- 必须先启动portmap之后再启动nfs3
- 如果portmap重启了,在重启之后nfs3也必须重启
启动NFS网关
启动RPC服务
- 检查系统rpcbind服务,确保该服务已经被停止并卸载
- 使用root用户启动portmap服务
- cd /usr/local/hadoop
- ./sbin/hadoop-daemon.sh —script ./bin/hdfs start portmap
- 角色验证
- jps
启动NFS3服务
- /tmp/. hdfs-nfs是不应该存在的
- 如果存在先删除在启动nfs3服务
使用代理用户启动nfs3
- sudo -u nfsuser ./sbin/hadoop-daemon.sh —script ./bin/hdfs start nfs3
角色验证
sudo -u nfsuser jps
[root@nfsgw ~]# cd /usr/local/hadoop/ [root@nfsgw hadoop]# ./sbin/hadoop-daemon.sh --script ./bin/hdfs start portmap [root@nfsgw hadoop]# jps 1376 Portmap 1416 Jps [root@nfsgw hadoop]# rm -rf /tmp/.hdfs-nfs [root@nfsgw hadoop]# sudo -u nfsuser ./sbin/hadoop-daemon.sh --script ./bin/hdfs start nfs3 [root@nfsgw hadoop]# sudo -u nfsuser jps 1452 Nfs3 1502 Jps挂载NFS网关
目前NFS只能使用v3版本
vers=3
仅使用TCP作为传输协议
- proto=tcp
不支持随机写NLM
- nolock
禁用access time的时间更新
- noatime
禁用acl扩展权限
- noacl
同步写入,避免重排序写入
- sync
安装依赖软件包(newnode)
yum install -y nfs-utils
挂载HDFS目录到本地/mnt文件夹
mount -t nfs -o vers=3,proto=tcp,noatime,nolock,sync,noacl 192.168.1.55:/ /mnt/
[root@newnode ~]# yum install -y nfs-utils
[root@newnode ~]# showmount -e 192.168.1.55
Export list for 192.168.1.55:
/ *
[root@newnode ~]# mount -t nfs -o vers=3,proto=tcp,nolock,noacl,noatime,sync 192.168.1.55:/ /mnt/
[root@newnode ~]# df -h
Filesystem Size Used Avail Use% Mounted on
192.168.1.55:/ 118G 15G 104G 13% /mnt
zookeeper 高可用集群
zookeeper 概述
Zookeeper 是什么
- Zookeeper是一个开源的分布式应用程序协调服务
Zookeeper能做什么
- Zookeeper是用来保证数据在集群间的事务一致性
Zookeeper应用场景
- 集群分布式锁
- 集群统一命名服务
-
Zookeeper角色与特性
Leader :接受所有Follower的提案请求并统一协调发起提案 的投票,负责与所有的Follower进行内部数据交换
- Follower:直接为客户端服务并参与提案的投票,同时与Leader进行数据交换
- Observer:直接为客户端服务但并不参与提案的投票,同时也与Leader进行数据交换
Zookeeper角色与选举
- 服务在启动的时候是没有角色的(LOOKING),角色是通过选举产生的
- 选举产生一个Leader,剩下的是Follower
选举Leader原则
- 集群中超过半数机器投票选择Leader
- 假如集群中拥有n台服务器,那么Leader必须得到(n/2+1)台服务器的投票
Zookeeper的高可用
- 如果Leader死亡,重新选举Leader
- 如果死亡的机器数量达到一半,则集群挂掉
- 如果无法得到足够的投票数量,就重新发起投票,如果参与投票的机器不足n/2+1,则集群停止工作
- 如果Follower死亡过多,剩余机器不足n/2+1,则集群也会停止工作
- Observer不计算在投票总设备数量里面
Zookeeper可伸缩扩展性原理与设计
- Leader所有写相关操作
- Follower读操作与响应Leader提议
- 在Observer出现以前,Zookeeper的伸缩性由Follower来实现,我们可以通过添加Follower节点的数量来保证 Zookeeper服务的读性能,但是随着FoIIower节点数量的增加,Zookeeper服务的写性能受到了影响
Zookeeper可伸缩扩展性原理与设计
客户端提交一个请求,若是读请求,则由每台Server的本地副本数据库直接响应。若是写请求,需要通过一致性协议(Zab)来处理
Zab协议
Zab协议规定:来自Client的所有写请求都要转发给集群中唯一的Leader
- 当Leader收到一个写请求时就会发起一个提案进行投票。然 后其他的Server对该提案进行投票。之后Leader收集投票的 结果,当投票数量过半时Leader会向所有的Server发送一个 通知消息。
最后当Client所连接的Server收到该消息时,会把该操作 更新并对Client的写请求做出回应
写性能问题
- ZooKeeper在上述协议中实际扮演了两个职能。一方面从客 户端接受连接与操作请求,另一方面对操作结果进行投票。 这两个职能在集群扩展的时候彼此制约
从Zab协议对写请求的处理过程中可以发现,增加 Follower的数量,则增加了协议投票过程的压力。因为 Leader节点必须等待集群中过半Server响应投票,是节点 的增加使得部分计算机运行较慢,从而拖慢整个投票过程的 可能性也随之提高,随着集群变大,写操作也会随之下降
Observer
Observer的扩展,给Zookeeper的可伸缩性带来了全新的 景象。加入很多Observer节点,无须担心严重影响写吞吐量。Observer提升读性能的可伸缩性,并且还提供了提供 了广域网能力
但Observer并非是无懈可击,因为协议中的通知阶段,仍然与服务器的数量呈线性关系。但是这里的串行开销非常低。因此,可以认为在通知服务器阶段不会成为瓶颈
zookeeper集群本身具有很好的高可用特性
Ieader死亡后会重新选举新的I eader,这个过程完全是自动的,不需要人工干预,fllower是多个节点,其中部分死亡后其他节点还可以继续工作
不管是leader还是fllower,死亡的总数不能达到(n/2) 台,否则集群挂起,observer不计算在高可用里面zookeeper集群部署
 1、重启云主机 hadoop1,node-0001,node-0002,node-0003
1、重启云主机 hadoop1,node-0001,node-0002,node-0003
2、在 hadoop1 上安装配置 zookeeper,并同步给其他主机
拷贝云盘 public/hadoop/zookeeper-3.4.13.tar.gz 到hadoop1
zoo. cfg默认是单机模式(standalone),如果组建集群, 在文件的末尾添加集群节点信server.运行id=主机名称:端口:范围:observer
[root@hadoop1 ~]# yum install -y java-1.8.0-openjdk-devel [root@hadoop1 ~]# tar zxf zookeeper-3.4.13.tar.gz [root@hadoop1 ~]# mv zookeeper-3.4.13 /usr/local/zookeeper [root@hadoop1 ~]# cd /usr/local/zookeeper/conf/ [root@hadoop1 conf]# cp zoo_sample.cfg zoo.cfg [root@hadoop1 conf]# vim zoo.cfg # 配置文件最后添加 server.1=node-0001:2888:3888 server.2=node-0002:2888:3888 server.3=node-0003:2888:3888 server.4=hadoop1:2888:3888:observer [root@hadoop1 ~]# for i in node-{0001..0003};do rsync -aXSH --delete /usr/local/zookeeper ${i}:/usr/local/ done创建datadir指定的目录
- 在目录下创建myid文件,文件内容为主机运行id
- myid文件中只有一个数字
- server.id中的id与myid中的id必须对应
- id的范围是1~255
- 请确保每个server的id都是唯一的
- 启动集群,查看验证(在所有集群节点执行)
- 查看角色,必须启动超过半数的机器才能选举角色
- 如果集群节点数量不足一半,集群的状态是:Error
所有节点手工启动服务
[root@hadoop1 ~]# mkdir /tmp/zookeeper
[root@hadoop1 ~]# grep -Po "\d+(?==${HOSTNAME})" /usr/local/zookeeper/conf/zoo.cfg >/tmp/zookeeper/myid # ?=正则表达式的零宽断言,类似于if判断,grep -o只显示匹配的内容
[root@hadoop1 ~]# /usr/local/zookeeper/bin/zkServer.sh start
[root@hadoop1 ~]# jps
1001 QuorumPeerMain
当所有节点启动完成以后使用命令验证:/usr/local/zookeeper/bin/zkServer.sh status
集群远程管理
zookeeper管理文档
http://zookeeper.apache.org/doc/r3.4.10/zookeeperAdmin.html
zookeeper提供了一些简单命令用来管理集群
例如:
- 健康状态:ruok
- 配置文件:conf
集群状态:mntr
[root@hadoop1 ~]# yum install -y socat [root@hadoop1 ~]# socat - TCP:node-0001:2181 ruok imok [root@hadoop1 bin]# ./zkstats hadoop1 node-{0001..0003} # zkstats 是手工编写的脚本 hadoop1 Mode: observer node-0001 Mode: follower node-0002 Mode: leader node-0003 Mode: followerkafka分布式消息队列
kafka概述
Kafka是什么
Kafka是由Linkedln开发的一个分布式的消息系统
- Kafka是使用Seala编写
- Kafka是一种消息中间件
为什么要使用Kafka
- 解耦、冗余、异步通信、提高扩展性
-
Kafka角色与集群结构
producer:生产者,负责发布消息
- consumer :消费者,负责读取处理消息
- topic:消息的类别
- Broker: Kafka集群包含一个或多个服务器
- Kafka将元数据信息保存在Zookeeper中
- broker会在zookeeper注册并保持相关的元数据更新
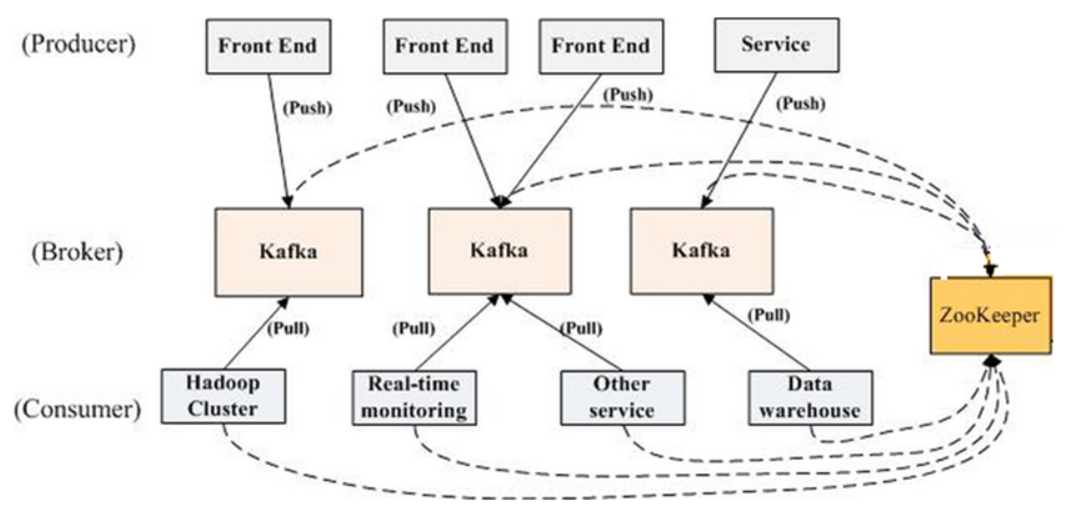
安装配置kafka
配置kafka集群之前必须有一个高可用的zookeeper集群
主机机必须安装java-openjdk运行环境
解压 kafka 到 /usr/locaI/kafka
编辑/usr/local/kafka/config/server. properties
- broker, id集群运行id
- zookeeper.connect 配置 zookeeper 集群地址
启动kafka服务(所有主机)
1、安装配置 kafka,并同步给其他主机
拷贝云盘 public/hadoop/kafka_2.12-2.1.0.tgz 到 hadoop1
[root@hadoop1 ~]# yum install -y java-1.8.0-openjdk-devel
[root@hadoop1 ~]# tar zxf kafka_2.12-2.1.0.tgz
[root@hadoop1 ~]# mv kafka_2.12-2.1.0 /usr/local/kafka
[root@hadoop1 ~]# for i in node-{0001..0003};do
rsync -aXSH --delete /usr/local/kafka ${i}:/usr/local/
done
2、修改 node-0001,node-0002,node-0003 配置文件并启动服务
[root@node-0001 ~]# vim /usr/local/kafka/config/server.properties
21 broker.id=1
123 zookeeper.connect=node-0001:2181,node-0002:2181,node-0003:2181
[root@node-0001 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@node-0001 ~]# jps
1400 Kafka
3、验证(在不同机器上执行)
# 创建一个topic
[root@node-0001 ~]# /usr/local/kafka/bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --zookeeper localhost:2181 --topic mymsg
# 生产者
[root@node-0002 ~]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mymsg
# 消费者
[root@node-0003 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mymsg
高可用hadoop集群
高可用概述
NameNode高可用
- 想实现Hadoop高可用就必须实现NameNode的高可用, NameNode是HDFS的核心,HDFS又是Hadoop核心组件, NameNode在Hadoop集群中至关重要
- NameNode宕机,将导致集群不可用,如果NameNode数据丢失 将导致整个集群的数据丢失,而NameNode的数据的更新又比 较频繁,实现NameNode高可用势在必行
官方提供了两种解决方案
- HDFS with NFS
- HDFS with QJM
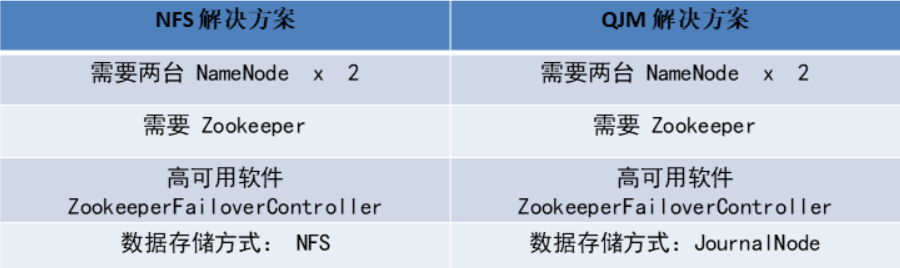
方案对比
- 都能实现热备
- 都是一个Active和一个Standby
- 都使用Zookeeper和ZKFC来实现高可用
- NFS方案:把数据存储在共享存储里,还需要考虑NFS的高可 用设计
QJM方案:不需要共享存储,但需要让每一个DN都知道两个 NameNode的位置,并把块信息和心跳包发送给Active和 Standby 这两个 NameNode
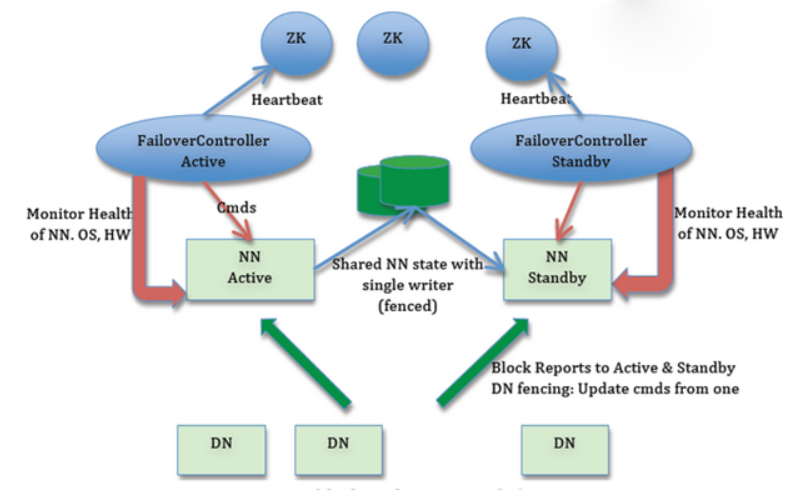
QJM方案解析
QJM方案
为HDFS配置两个NameNode,—个处于Active状态,另—处 于Standby状态。Active NameNode对外提供服务,而 Standby则仅同步Active的状态,以便能够在它失败时进行切换
- 在任何时候只能有一个NameNode处于活动状态,如果出现 两个Active NameNode,(这种情况通常称为”sp Iit-brain” 脑裂,三节点通讯阻断)会导致集群操作混乱,可能会导致数据丢失或状态异常
fsimage—致性
- NameNode更新很频繁,为了保持主备数据的一致性,为了支 持快速 Failover, Standby NameNode 持有集群中 blocks 的最新位置是非常必要的。为了达到这一目的,DataNodes 上需要同时配置这两个Namenode的地址,同时和它们都建 立心跳连接,并把block位置发送给它们
fsedit同步
- 为了让 Standby NameNode与Active NameNode 保持同步, 这两个NameNode都与一组称为JNS的互相独立的进程保持 通信(Journal Nodes)。
- 当Active NameNode更新了,它将记录修改日志发送给 Journal Node , Standby Node 将会从 Journal Node 中读 取这些日志,将日志变更应用在自己的数据中,并持续关注它们对日志的变更
主备切换
- 当Failover发生时,Standby首先读取Journal node中所有 的日志,并将它应用到自己的数据中
- 获取JournaI Node写权限:对于JournaI node而言,任何时 候只允许一个NameNode作为writer;在Failover期间,原来 的Standby NameNode将会接管Act i ve的所有职能,并负责向 Journa I node写入日志记录
- 提升自己为Active
高可用集群搭建
角色与配置
| 主机名 | IP地址 | 角色服务 |
|---|---|---|
| hadoop1 | 192.168.1.50 | namenode, resourcemanager, ZKFC |
| hadoop2 | 192.168.1.56 | namenode, resourcemanager, ZKFC |
| node-0001 | 192.168.1.51 | datanode, nodemanager, zookeeper, journalnode |
| node-0002 | 192.168.1.52 | datanode, nodemanager, zookeeper, journalnode |
| node-0003 | 192.168.1.53 | datanode, nodemanager, zookeeper, journalnode |
环境初始化
hadoop1 上执行
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.56 hadoop2
192.168.1.51 node-0001
192.168.1.52 node-0002
192.168.1.53 node-0003
[root@hadoop1 ~]# rsync -aXSH --delete /root/.ssh hadoop2:/root/
[root@hadoop1 ~]# for i in hadoop2 node-{0001..0003};do
rsync -av /etc/hosts ${i}:/etc/
done
hadoop2 上执行
[root@hadoop2 ~]# yum install -y java-1.8.0-openjdk-devel
[root@hadoop2 ~]# vim /etc/ssh/ssh_config
# 60行新添加
StrictHostKeyChecking no
集群配置文件
在 hadoop1 上完成以下文件的配置
namenode高可用
1、配置 hadoop-env.sh
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
25: export JAVA_HOME="java-1.8.0-openjdk安装路径"
33: export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
2、配置 slaves
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/slaves
node-0001
node-0002
node-0003
3、配置 core-site.xml
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> # fs.defaultFS:文件系统配置参数
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name> # 数据目录配置参数
<value>/var/hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> # zookeeper服务地址
<value>node-0001:2181,node-0002:2181,node-0003:2181</value>
</property> # 同时配置多个主机防止单点故障
<property> # NFSGW相关授权配置没有影响,可以保持不动
<name>hadoop.proxyuser.nfsuser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.hosts</name>
<value>*</value>
</property>
</configuration>
4、配置 hdfs-site.xml
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name> # 服务名
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name> # 定义服务中的角色
<value>nn1,nn2</value>
</property>
<property> # 角色1的rpc地址及端口号
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:8020</value>
</property>
<property> # 角色2的rpc地址及端口号
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:8020</value>
</property>
<property> # Namenode 1 的地址及端口号
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:50070</value>
</property>
<property> # Namenode 2 的地址及端口号
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:50070</value>
</property>
<property> # JournalNode 的地址及端口号
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node-0001:8485;node-0002:8485;node-0003:8485/mycluster</value>
</property>
<property> # JournalNode 的数据存放地址
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/journal</value>
</property>
<property> # Failover类服务名
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property> # 远程管理方式,使用ssh远程管理
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property> # ssh私钥的位置
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property> # 自动实现故障切换
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property> # 文件副本数量
<name>dfs.replication</name>
<value>2</value>
</property>
<property> # 排除主机列表
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
</property>
</configuration>
resourcemanager高可用
5、配置 mapred-site.xml (计算框架配置文件)
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property> # 资源管理类
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6、配置 yarn-site.xml(资源管理配置文件)
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property> # 激活HA配置
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property> # 管理节点状态自动恢复
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property> # 数据状态保持介质
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property> # zookeeper服务器地址
<name>yarn.resourcemanager.zk-address</name>
<value>node-0001:2181,node-0002:2181,node-0003:2181</value>
</property>
<property> # 集群ID
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<property> # 定义两个 resourcemanager 角色
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property> # 角色1 对应主机地址
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<property> # 角色2 对应主机地址
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<!-- Site specific YARN configuration properties -->
<property> # 计算框架
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
高可用集群验证
初始化启动集群
1、重启机器、在 node-0001,node-0002,node-0003 启动 zookeeper
[root@node-0001 ~]# /usr/local/zookeeper/bin/zkServer.sh start
#----------------------------------------------------------------------------------------
[root@node-0002 ~]# /usr/local/zookeeper/bin/zkServer.sh start
#----------------------------------------------------------------------------------------
[root@node-0003 ~]# /usr/local/zookeeper/bin/zkServer.sh start
#----------------------------------------------------------------------------------------
[root@hadoop1 ~]# zkstats node-{0001..0003}
node-0001 Mode: follower
node-0002 Mode: leader
node-0003 Mode: follower
2、清空实验数据并同步配置文件(hadoop1 上执行)
[root@hadoop1 ~]# rm -rf /var/hadoop/* /usr/local/hadoop/logs
[root@hadoop1 ~]# for i in hadoop2 node-{0001..0003};do
rsync -av /etc/hosts ${i}:/etc/
rsync -aXSH --delete /var/hadoop ${i}:/var/
rsync -aXSH --delete /usr/local/hadoop ${i}:/usr/local/
done
3、在 node-0001,node-0002,node-0003 启动 journalnode 服务
[root@node-0001 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
[root@node-0001 ~]# jps
1037 JournalNode
#----------------------------------------------------------------------------------------
[root@node-0002 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
#----------------------------------------------------------------------------------------
[root@node-0003 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
4、初始化(hadoop1 上执行)
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs zkfc -formatZK # 初始化zookeeper集群
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs namenode -format # 格式化
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs namenode -initializeSharedEdits # 初始化JNS
[root@hadoop1 ~]# rsync -aXSH --delete /var/hadoop/dfs hadoop2:/var/hadoop/
5、停止在 node-0001,node-0002,node-0003 上的 journalnode 服务
[root@node-0001 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
#----------------------------------------------------------------------------------------
[root@node-0002 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
#----------------------------------------------------------------------------------------
[root@node-0003 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
6、启动集群(HDFS和Yarn)
#-------------------- 下面这条命令在 hadoop1 上执行 ------------------------
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-all.sh
#-------------------- 下面这条命令在 hadoop2 上执行 ------------------------
[root@hadoop2 ~]# /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
验证集群
# 获取NameNode状态
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2
# 获取Resourcemanager状态
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm2
# 获取节点信息
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn node -list
使用高可用集群分析数据实验
# 访问集群文件
[root@hadoop1 ~]# cd /usr/local/hadoop
[root@hadoop1 hadoop]# ./bin/hadoop fs -mkdir /input
[root@hadoop1 hadoop]# ./bin/hadoop fs -put *.txt /input/
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
[root@hadoop1 hadoop]# ./bin/hadoop fs -cat /output/*
常用管理命令


若有收获,就点个赞吧
0 人点赞
