使用 OpenACC 技术进行高性能计算(HPC)编程。
支持 OpenACC 的软件很多,使用英伟达公司提供的高性能计算套件最为方便。
环境:
- ubuntu18.04 64bit
- 2080 Ti
安装
【注意】:安装 HPC SDK 时需要首先安装 CUDA
首先列出需要用到的链接。
英伟达公司提供的 HPC SDK
官方安装教程
https://docs.nvidia.com/hpc-sdk/hpc-sdk-install-guide/index.html
使用手册:
https://docs.nvidia.com/hpc-sdk/compilers/hpc-compilers-user-guide/index.html
- 下载 HPC SDK
在第一个链接中注册下载 HPC 套件,选择本地安装包,约5G,较大。记下下载的版本号,这里下载的是 20.9
下面给出了安装命令
wget https://developer.download.nvidia.com/hpc-sdk/20.11/nvhpc_2020_2011_Linux_x86_64_cuda_multi.tar.gztar xpzf nvhpc_2020_2011_Linux_x86_64_cuda_multi.tar.gzsudo nvhpc_2020_2011_Linux_x86_64_cuda_multi/install
- 设置环境变量
按照上面的安装完成后,默认安装在 /opt/nvidia/hpc_sdk 文件夹,设置环境变量后即可使用
在 ~/.bashrc 文件末尾写入下面几行(注意将 20.9换成自己的版本号)
NVARCH=`uname -s`_`uname -m`; export NVARCHNVCOMPILERS=/opt/nvidia/hpc_sdk; export NVCOMPILERSMANPATH=$MANPATH:$NVCOMPILERS/$NVARCH/20.9/compilers/man; export MANPATHPATH=$NVCOMPILERS/$NVARCH/20.9/compilers/bin:$PATH; export PATHexport PATH=$NVCOMPILERS/$NVARCH/20.9/comm_libs/mpi/bin:$PATHexport MANPATH=$MANPATH:$NVCOMPILERS/$NVARCH/20.9/comm_libs/mpi/man
使环境变量生效:
source ~/.bashrc
- 检查是否安装成功
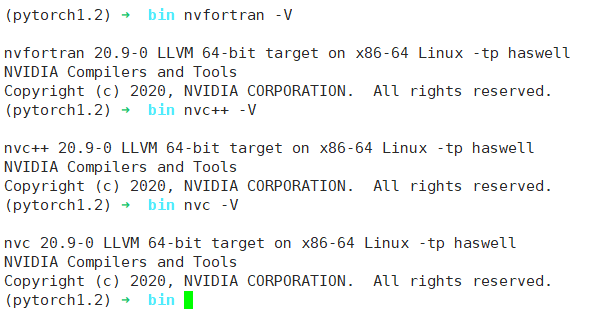
OpenACC 支持 Fortran、C/C++ 三种语言,检查这三种语言编译器是否成功安装
nvfortran -Vnvc++ -Vnvc -V
OpenACC 编程示例
示例1-OpenACC测试
用 C 语言编程测试 OpenACC 是否能够正常使用。代码如下(C语言):
若openacc 能够正确使用,则检测当前机器GPU数量,否则输出不支持
#include<stdio.h>#ifdef _OPENACC#include<openacc.h>#endifint main(){#ifdef _OPENACCprintf("Number of device: %d \n", acc_get_num_devices(acc_device_not_host));#elseprintf("OpenACC is not supported.\n");#endifreturn 0;}
命令行编译运行
nvc -acc c_test.c -o acc_test.exe./acc_test.exe

示例2-数组加法
该例子来自官方文档:
https://docs.nvidia.com/hpc-sdk/compilers/openacc-gs/index.html#c-examples
// nvc -acc -Minfo plus.c -o plus.exe#include<stdio.h>#define N 256int main(){int i, a[N], b[N], c[N];for(i = 0; i < N; i++){a[i] = i;b[i] = i;c[i] = 0;}#pragma acc kernelsfor(i = 0; i < N; i++){c[i] = a[i] + b[i];}printf("c[N-1]= %d (right value %d) \n", c[N-1], 2*N-2); // c[N-1] should equal to 2*(N-1)return 0;}

小技巧
- 编译时使用 -Minfo 参数可以输出编译过程中的更多信息
环境变量 NVCOMPILER_ACC_NOTIFY
设置 NVCOMPILER_ACC_NOTIFY=1 ,程序会输出每次调用 kernel 时的运行信息, 设置 NVCOMPILER_ACC_NOTIFY=3 ,程序还会输出额外的数据信息
环境变量 NVCOMPILER_ACC_TIME
设置 NVCOMPILER_ACC_TIME = 1 ,程序会输出数据在 CPU、GPU之间传输、计算的时间信息
多设备编程
使用 OpenACC 调用多张 GPU 计算,主要用到下面的函数:
- acc_get_num_devices(acc_device_not_host): 查看当前设备中包含的GPU 数量
- acc_set_device_num(device_id, device_type): 设置当前使用的设备,接收两个参数:设备id 和设备类型,以设置使用 0 号 nvidia GPU 计算卡为例: acc_set_device_num(0,acc_device_nvidia)
编程示例:
#include<openacc.h>#define GPU_NUM 3int main(){printf("Number of device: %d \n", acc_get_num_devices(acc_device_not_host));for (int gpu=0; gpu < GPU_NUM ; gpu++){acc_set_device_num(gpu, acc_device_nvidia);}/*write your code here*/return 0;}// nvc -acc -Minfo -ta=tesla:managed acc_gpu.c -o acc_gpu.exe
将程序保存为文件 acc_gpu.c, 并使用下面命令编译运行:
nvc -acc -Minfo -ta=tesla:managed acc_gpu.c -o acc_gpu.exe./acc_gpu.exe
上面的程序没有进行任何计算,将上述代码添加到我们编写完成的程序后,即可调用GPU计算。
实时监控 GPU 内存使用情况,可以看到程序成功使用3块GPU 进行了计算
若涉及复杂的多种不同的 CPU、GPU 设备协同计算, 最好使用 openmp 技术,其中 mp 是 muti-process 的意思。
参考:
https://github.com/OpenACC/openacc-best-practices-guide/blob/main/08-Advanced.markdown
学习资料

若有收获,就点个赞吧
0 人点赞
