什么是MongoDB
MongoDB是面向文档的NoSQL数据库,用于大量数据存储。属于NoSQL数据库的类别。
MongoDB功能
每个数据库都包含集合,而集合又包含文档。每个文档可以具有不同数量的字段。每个文档的大小和内容可以互不相同。 文档结构更符合开发人员如何使用各自的编程语言构造其类和对象。开发人员经常会说他们的类不是行和列,而是具有键值对的清晰结构。 从NoSQL数据库的简介中可以看出,行(或在MongoDB中调用的文档)不需要预先定义架构。相反,可以动态创建字段。 MongoDB中可用的数据模型使我们可以更轻松地表示层次结构关系,存储数组和其他更复杂的结构。 可伸缩性– MongoDB环境具有很高的可伸缩性。全球各地的公司已经定义了自己的集群,其中一些集群运行着100多个节点,数据库中包含大约数百万个文档
为什么使用MongoDB
- 面向文档的–由于MongoDB是NoSQL类型的数据库,它不是以关系类型的格式存储数据,而是将数据存储在文档中。这使得MongoDB非常灵活,可以适应实际的业务环境和需求。
- 临时查询-MongoDB支持按字段,范围查询和正则表达式搜索。可以查询返回文档中的特定字段。
- 索引-可以创建索引以提高MongoDB中的搜索性能。MongoDB文档中的任何字段都可以建立索引。
- 复制-MongoDB可以提供副本集的高可用性。副本集由两个或多个mongo数据库实例组成。每个副本集成员可以随时充当主副本或辅助副本的角色。主副本是与客户端交互并执行所有读/写操作的主服务器。辅助副本使用内置复制维护主数据的副本。当主副本发生故障时,副本集将自动切换到辅助副本,然后它将成为主服务器。
负载平衡-MongoDB使用分片的概念,通过在多个MongoDB实例之间拆分数据来水平扩展。MongoDB可以在多台服务器上运行,以平衡负载或复制数据,以便在硬件出现故障时保持系统正常运行
MongoDB常用术语
下面是MongoDB中使用的一些常用术语
_id – 这是每个MongoDB文档中必填的字段。_id字段表示MongoDB文档中的唯一值。_id字段类似于文档的主键。如果创建的新文档中没有_id字段,MongoDB将自动创建该字段。
- 集合 – 这是MongoDB文档的分组。集合等效于在任何其他RDMS(例如Oracle或MS SQL)中创建的表。集合存在于单个数据库中。从介绍中可以看出,集合不强制执行任何结构。
- 游标 – 这是指向查询结果集的指针。客户可以遍历游标以检索结果。
- 数据库 – 这是像RDMS中那样的集合容器,其中是表的容器。每个数据库在文件系统上都有其自己的文件集。MongoDB服务器可以存储多个数据库。
- 文档 - MongoDB集合中的记录基本上称为文档。文档包含字段名称和值。
- 字段 - 文档中的名称/值对。一个文档具有零个或多个字段。字段类似于关系数据库中的列
下图显示了带有键值对的字段的示例。如下的例子中,CustomerID和11是文档中定义的键值对之一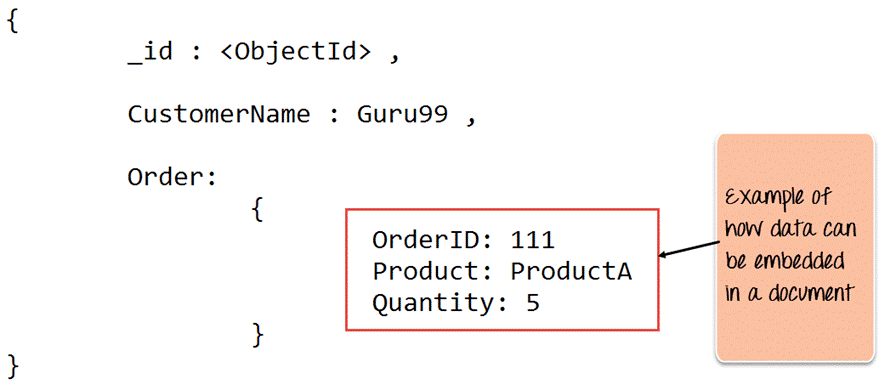
MongoDB与RDBMS区别
下表将帮助您更容易理解Mongo中的一些概念:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
WT的事务构造
知道了基本的事务概念和ACID后,来看看WT引擎是怎么来实现事务和ACID的。要了解实现先要知道它的事务的构造和使用相关的技术,WT在实现事务的时使用主要是使用了三个技术:snapshot(事务快照)、MVCC (多版本并发控制)和redo log(重做日志),为了实现这三个技术,它还定义了一个基于这三个技术的事务对象和全局事务管理器。事务对象描述如下
wt_transaction{transaction_id: 本次事务的**全局唯一的ID**,用于标示事务修改数据的版本号snapshot_object: 当前事务开始或者操作时刻其他正在执行且并未提交的事务集合,用于事务隔离operation_array: 本次事务中已执行的操作列表,用于事务回滚。redo_log_buf: 操作日志缓冲区。用于事务提交后的持久化state: 事务当前状态}
WT的多版本并发控制
WT中的MVCC是基于key/value中value值的链表,这个链表单元中存储有当先版本操作的事务ID和操作修改后的值。描述如下:
wt_mvcc{transaction_id: 本次修改事务的IDvalue: 本次修改后的值}
WT中的数据修改都是在这个链表中进行append操作,每次对值做修改都是append到链表头上,每次读取值的时候读是从链表头根据值对应的修改事务transaction_id和本次读事务的snapshot来判断是否可读,如果不可读,向链表尾方向移动,直到找到读事务能都的数据版本。样例如下:
上图中,事务T0发生的时刻最早,T5发生的时刻最晚。T1/T2/T4是对记录做了修改。那么在mvcc list当中就会增加3个版本的数据,分别是11/12/14。如果事务都是基于snapshot级别的隔离,T0只能看到T0之前提交的值10,读事务T3访问记录时它能看到的值是11,T5读事务在访问记录时,由于T4未提交,它也只能看到11这个版本的值。这就是WT 的MVCC基本原理

若有收获,就点个赞吧
0 人点赞
