什么是Redis
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化
支持丰富的数据类型,如:String、list、set、zset、hash
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化
为什么要使用Redis
- 读写性能优异
数据类型丰富
Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作
原子性
Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行
丰富的特性
Redis支持 publish/subscribe, 通知, key 过期等特性
持久化
Redis支持RDB, AOF等持久化方式
发布订阅
Redis支持发布/订阅模式
分布式
Redis Cluster
Redis的使用场景
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性
作为缓存使用时,一般有两种方式保存数据:
- 读取前,先去读Redis,如果没有数据,读取数据库,将数据拉入Redis。
- 插入数据时,同时写入Redis
方案一:实施起来简单,但是有两个需要注意的地方:
- 避免缓存击穿。(数据库没有就需要命中的数据,导致Redis一直没有数据,而一直命中数据库)
- 数据的实时性相对会差一点
限时业务的运用
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等
延时操作
比如在订单生产后我们占用了库存,10分钟后去检验用户是够真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。
当然我们也可以利用rabbitmq、activemq等消息中间件的延迟队列服务实现该需求
数据类型:5种基础数据类型详解
Redis数据结构简介
首先对redis来说,所有的key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作 对整数或浮点数进行自增或自减操作 |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素; 根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除; 还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射; 元素的排列顺序由分数的大小决定; 包含方法有添加、获取、删除单个元素以及根据分值范围或成员来 获取元素 |
String字符串
String是redis中最基本的数据类型,一个key对应一个value
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象
- 图例
下图是一个String类型的实例,其中键为hello,值为world
命令使用 | 命令 | 简述 | 使用 | | —- | —- | —- | | GET | 获取存储在给定键中的值 | GET name | | SET | 设置存储在给定键中的值 | SET name value | | DEL | 删除存储在给定键中的值 | DEL name | | INCR | 将键存储的值加1 | INCR key | | DECR | 将键存储的值减1 | DECR key | | INCRBY | 将键存储的值加上整数 | INCRBY key amount | | DECRBY | 将键存储的值减去整数 | DECRBY key amount |
命令执行
127.0.0.1:6379> set hello worldOK127.0.0.1:6379> get hello"world"127.0.0.1:6379> del hello(integer) 1127.0.0.1:6379> get hello(nil)127.0.0.1:6379> get counter"2"127.0.0.1:6379> incr counter(integer) 3127.0.0.1:6379> get counter"3"127.0.0.1:6379> incrby counter 100(integer) 103127.0.0.1:6379> get counter"103"127.0.0.1:6379> decr counter(integer) 102127.0.0.1:6379> get counter"102"
实战场景
缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
session:常见方案spring session + redis实现session共享
List列表
Redis中的List其实就是链表(Redis用双端链表实现List)
使用List结构,我们可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行
- 图例
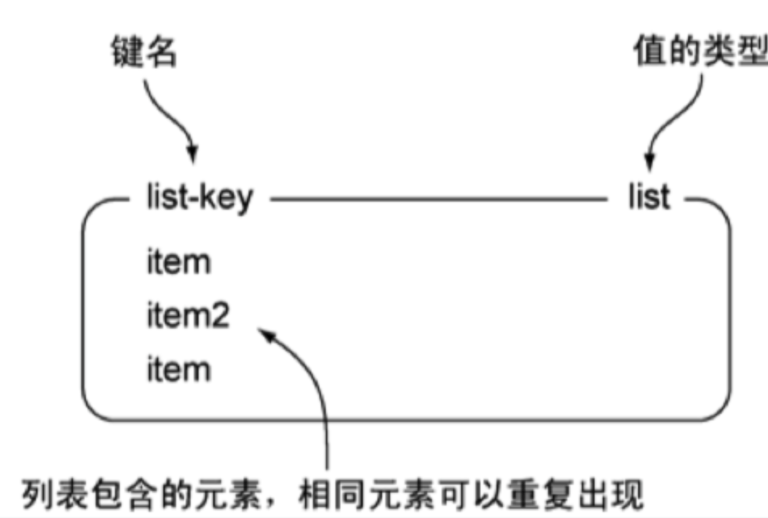
命令使用 | 命令 | 简述 | 使用 | | —- | —- | —- | | RPUSH | 将给定值推入到列表右端 | RPUSH key value | | LPUSH | 将给定值推入到列表左端 | LPUSH key value | | RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key | | LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key | | LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 | | LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推 | LINEX key index |
使用列表的技巧
lpush+lpop=Stack(栈)<br /> lpush+rpop=Queue(队列)<br /> lpush+ltrim=Capped Collection(有限集合)<br /> lpush+brpop=Message Queue(消息队列)<br />**命令执行**
127.0.0.1:6379> lpush mylist 1 2 ll ls mem(integer) 5127.0.0.1:6379> lrange mylist 0 -11) "mem"2) "ls"3) "ll"4) "2"5) "1"127.0.0.1:6379> lindex mylist -1"1"127.0.0.1:6379> lindex mylist 10 # index不在 mylist 的区间范围内(nil)
实战场景
微博TimeLine: 有人发布微博,用lpush加入时间轴,展示新的列表信息。
-
Set集合
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1) 图例
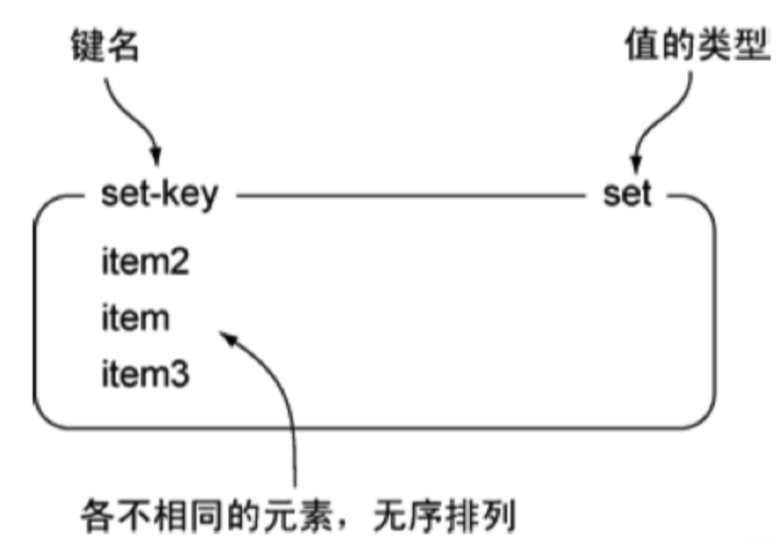
命令使用 | 命令 | 简述 | 使用 | | —- | —- | —- | | SADD | 向集合添加一个或多个成员 | SADD key value | | SCARD | 获取集合的成员数 | SCARD key | | SMEMBER | 返回集合中的所有成员 | SMEMBER key member | | SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
命令执行
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao(integer) 3127.0.0.1:6379> smember myset1) "xiaohao"2) "hao1"3) "hao"127.0.0.1:6379> sismember myset hao(integer) 1
实战场景
标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
-
Hash散列
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
图例
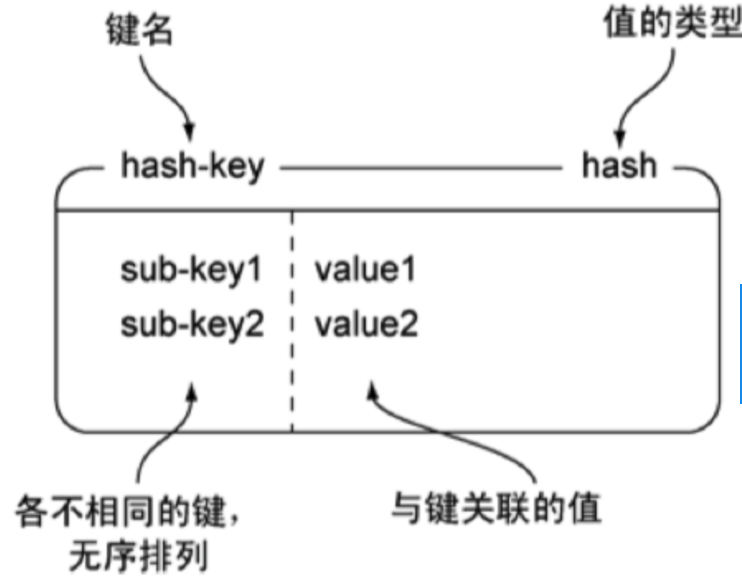
命令使用 | 命令 | 简述 | 使用 | | —- | —- | —- | | HSET | 添加键值对 | HSET hash-key sub-key1 value1 | | HGET | 获取指定散列键的值 | HGET hash-key key1 | | HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key | | HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
命令执行
127.0.0.1:6379> hset user name1 hao(integer) 1127.0.0.1:6379> hset user email1 hao@163.com(integer) 1127.0.0.1:6379> hgetall user1) "name1"2) "hao"3) "email1"4) "hao@163.com"127.0.0.1:6379> hget user user(nil)127.0.0.1:6379> hget user name1"hao"127.0.0.1:6379> hset user name2 xiaohao(integer) 1127.0.0.1:6379> hset user email2 xiaohao@163.com(integer) 1127.0.0.1:6379> hgetall user1) "name1"2) "hao"3) "email1"4) "hao@163.com"5) "name2"6) "xiaohao"7) "email2"8) "xiaohao@163.com"
实战场景
缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
Zset有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序
有序集合的成员是唯一的,但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)图例
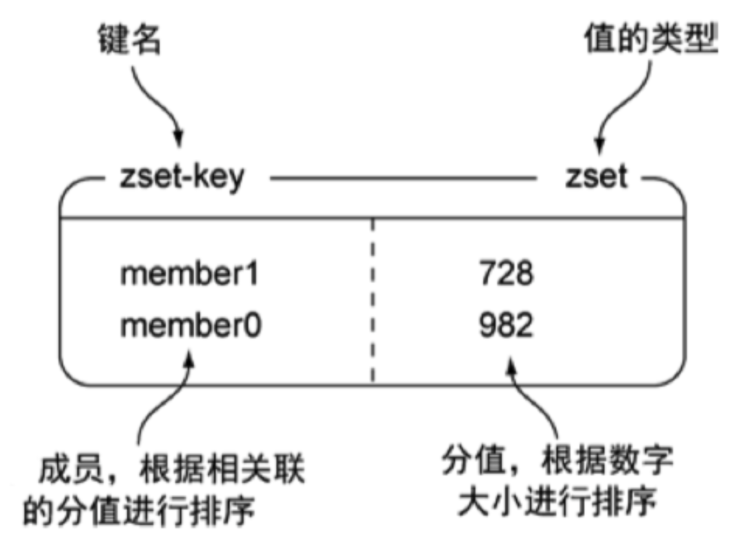
命令使用 | 命令 | 简述 | 使用 | | —- | —- | —- | | ZADD | 将一个带有给定分值的成员添加到哦有序集合里面 | ZADD zset-key 178 member1 | | ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores | | ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
命令执行
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao(integer) 2127.0.0.1:6379> ZRANGE myscoreset 0 -11) "xiaohao"2) "hao"127.0.0.1:6379> ZSCORE myscoreset hao"100"
实战场景
排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行持久化:RDB和AOF机制详解
为什么需要持久化?
1、会对数据库带来巨大的压力,
2、数据库的性能不如Redis。导致程序响应慢。
所以对Redis来说,实现数据的持久化,避免从后端数据库中恢复数据,是至关重要的
RDB 持久化
RDB 就是 Redis DataBase 的缩写,中文名为快照/内存快照,RDB持久化是把当前进程数据生成快照保存到磁盘上的过程
触发方式
手动触发
手动触发分别对应save和bgsave命令
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用
bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
自动触发
在以下4种情况时会自动触发
redis.conf中配置save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;
- 主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
- 执行debug reload命令重新加载redis时也会触发bgsave操作;
默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作
redis.conf中配置RDB
快照周期:内存快照虽然可以通过技术人员手动执行SAVE或BGSAVE命令来进行,但生产环境下多数情况都会设置其周期性执行条件
Redis中默认的周期新设置
其它相关配置
# 文件名称dbfilename dump.rdb# 文件保存路径dir /home/work/app/redis/data/# 如果持久化出错,主进程是否停止写入stop-writes-on-bgsave-error yes# 是否压缩rdbcompression yes# 导入时是否检查rdbchecksum yes
RDB优缺点
优点
- RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景
- Redis加载RDB文件恢复数据要远远快于AOF方式
缺点
- RDB方式实时性不够,无法做到秒级的持久化;
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高;
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全;
- 版本兼容RDB文件问题;
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决
AOF 持久化
而AOF日志采用写后日志,即先写内存,后写日志
为什么采用写后日志?
Redis要求高性能,采用写日志有两方面好处:
- 避免额外的检查开销:Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误的命令,Redis 在使用日志恢复数据时,就可能会出错。
- 不会阻塞当前的写操作
但这种方式存在潜在风险:
- 如果命令执行完成,写日志之前宕机了,会丢失数据。
-
如何实现AOF
AOF日志记录Redis的每个写命令,步骤分为:命令追加(append)、文件写入(write)和文件同步(sync)
命令追加 当AOF持久化功能打开了,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区。
- 文件写入和同步 关于何时将 aof_buf 缓冲区的内容写入AOF文件中,Redis提供了三种写回策略
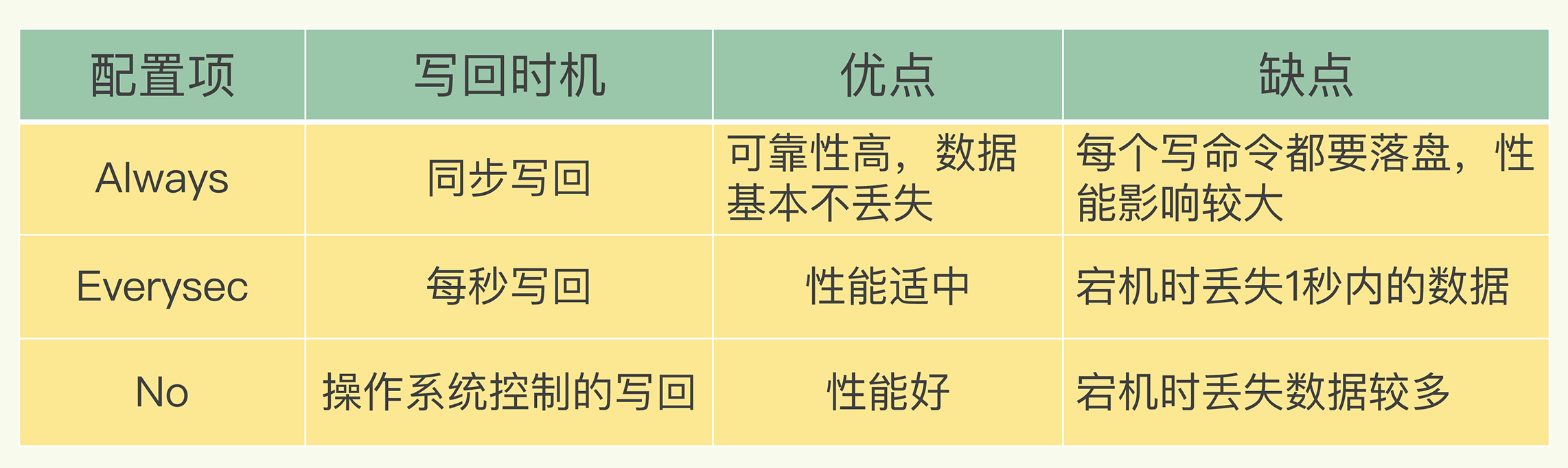
Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
No,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
从持久化中恢复数据
其实想要从这些文件中恢复数据,只需要重新启动Redis即可。我们还是通过图来了解这个流程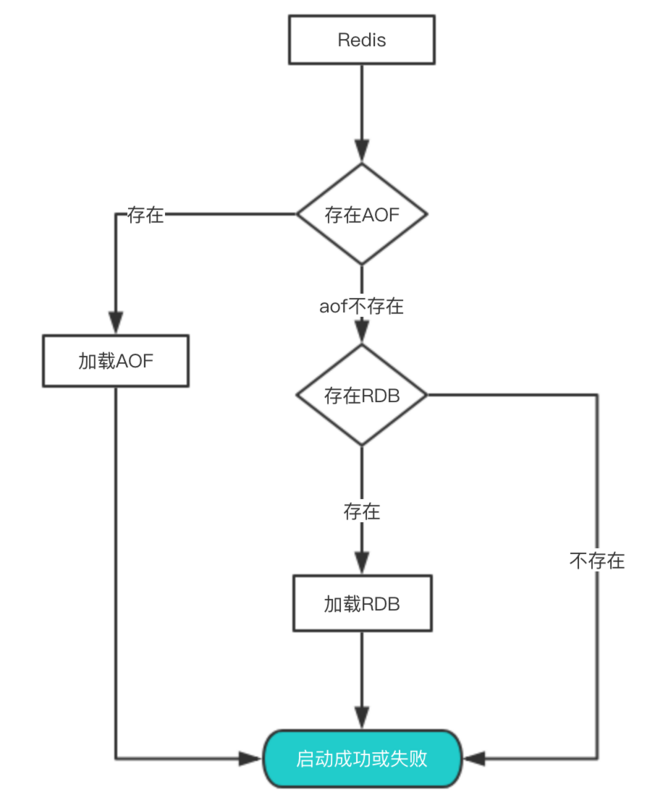
事务:Redis事务详解
redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令
- MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
- EXEC:执行事务中的所有操作命令。
- DISCARD:取消事务,放弃执行事务块中的所有命令。
- WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令
-
Redis事务执行步骤
开启:以MULTI开始一个事务
- 入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
-
如何理解Redis与事务的ACID?
事务有四个性质称为ACID,分别是原子性,一致性,隔离性和持久性
原子性atomicity
Redis的事务是原子性的:所有的命令,要么全部执行,要么全部不执行
- 一致性consistency
redis事务可以保证命令失败的情况下得以回滚,数据能恢复到没有执行之前的样子,是保证一致性的,除非redis进程意外终结
- 隔离性Isolation
redis事务是严格遵守隔离性的,原因是redis是单进程单线程模式(v6.0之前),可以保证命令执行过程中不会被其他客户端命令打断。
但是,Redis不像其它结构化数据库有隔离级别这种设计
- 持久性Durability
redis事务是不保证持久性的,这是因为redis持久化策略中不管是RDB还是AOF都是异步执行的,不保证持久性是出于对性能的考虑
高可用:主从复制详解
Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式
主从复制概述
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从库之间采用的是读写分离的方式
读操作:主库、从库都可以接收;
-
主从复制原理
全量(同步)复制:比如第一次同步时
- 增量(同步)复制:只会把主从库网络断连期间主库收到的命令,同步给从库
高可用:哨兵机制
哨兵的核心功能是主节点的自动故障转移
典型的哨兵集群监控的逻辑图: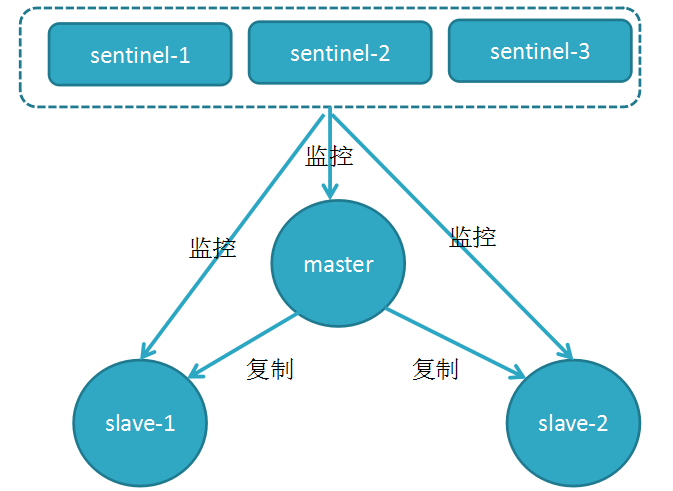
哨兵实现了什么
- 监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常
- 自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点
- 配置提供者(Configuration provider):客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址
- 通知(Notification):哨兵可以将故障转移的结果发送给客户端
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;而配置提供者和通知功能,则需要在与客户端的交互中才能体现
主库下线的判定
首先要理解两个概念:主观下线和客观下线
- 主观下线:任何一个哨兵都是可以监控探测,并作出Redis节点下线的判断;
- 客观下线:有哨兵集群共同决定Redis节点是否下线;
当某个哨兵(如下图中的哨兵2)判断主库“主观下线”后,就会给其他哨兵发送 is-master-down-by-addr 命令。接着,其他哨兵会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票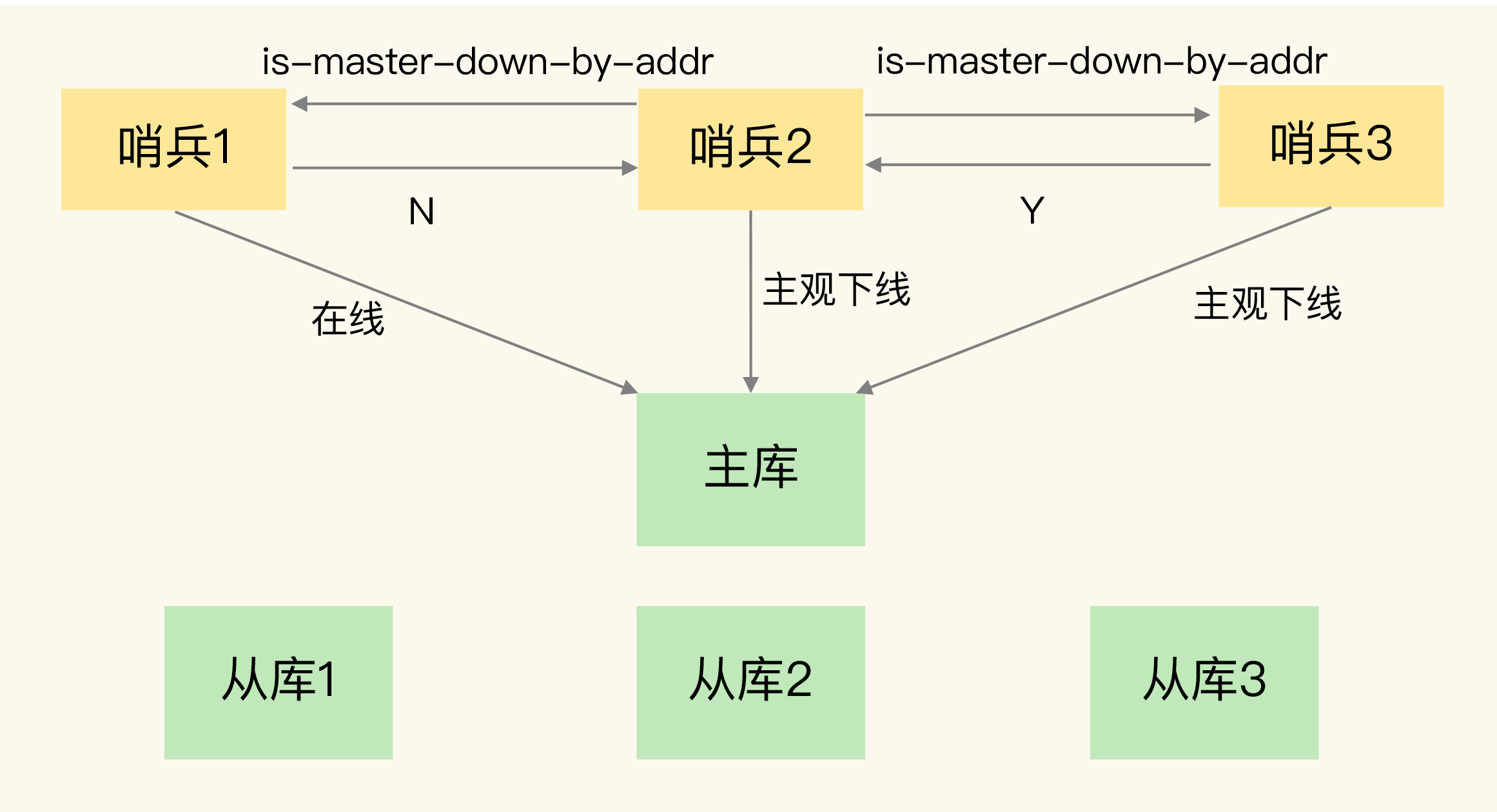
如果赞成票数(这里是2)是大于等于哨兵配置文件中的 quorum 配置项(比如这里如果是quorum=2), 则可以判定主库客观下线了
哨兵集群的选举
为什么必然会出现选举/共识机制?
为了避免哨兵的单点情况发生,所以需要一个哨兵的分布式集群。作为分布式集群,必然涉及共识问题(即选举问题);同时故障的转移和通知都只需要一个主的哨兵节点就可以了
哨兵的选举机制是什么样的?
**选举的票数大于等于num(sentinels)/2+1时,将成为领导者,如果没有超过,继续选举**
任何一个想成为 Leader 的哨兵,要满足两个条件
第一,拿到半数以上的赞成票;<br /> 第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值
新主库的选出
过滤掉不健康的(下线或断线),没有回复过哨兵ping响应的从节点
- 选择salve-priority从节点优先级最高(redis.conf)的
- 选择复制偏移量最大,指复制最完整的从节点
高可用:缓存问题
为什么要理解Redis缓存问题
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问Mysql等数据库
当缓存库出现时,必须要考虑如下问题缓存穿透
问题来源
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求解决方案
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)
布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小
缓存击穿
问题来源
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案
设置热点数据永远不过期
- 接口限流与熔断,降级
-
缓存雪崩
问题来源
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机
缓存击穿不同
缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
解决方案
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中
- 设置热点数据永远不过期

若有收获,就点个赞吧
0 人点赞
