1、 钱包业务背景介绍
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。 应用为每个用户开设一个系统内的虚拟钱包账户,支持用户充值、提现、支付、冻结、透 支 转赠、查询账户余额、查询交易流水等操作。下图是一张典型的钱包功能界面,你可以 直观地感受一下 。
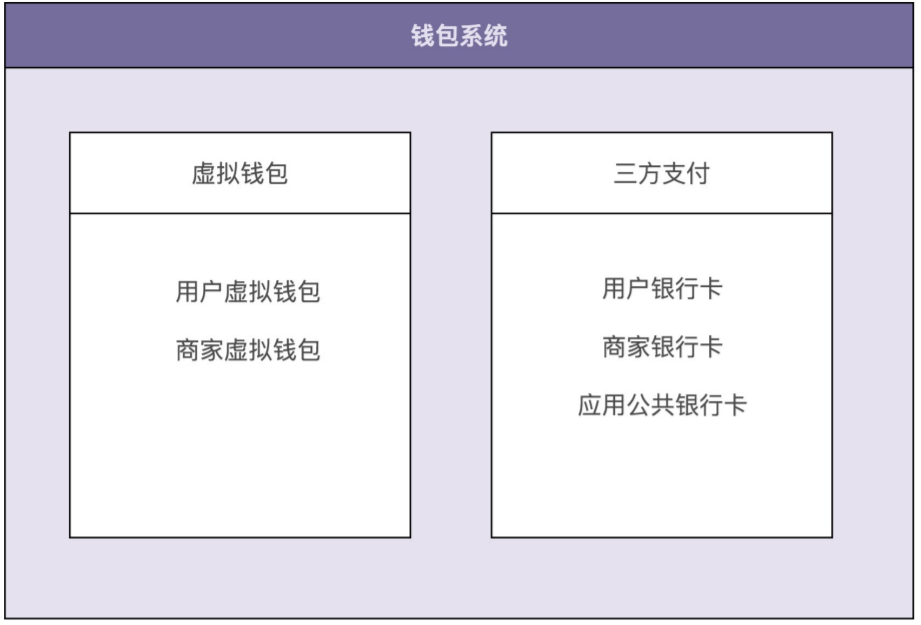
一般一个虚拟账户都会对应一个真实的支付账户,有可能是银行卡账户,也有可能是三方支付账户,(比如支付宝、微信) 我们设定钱包只有以下五种核心功能(其他比如冻结、透支、转赠等不常用的功能)
- 充值
- 体现
- 支付
- 查询余额
- 查询交易流水
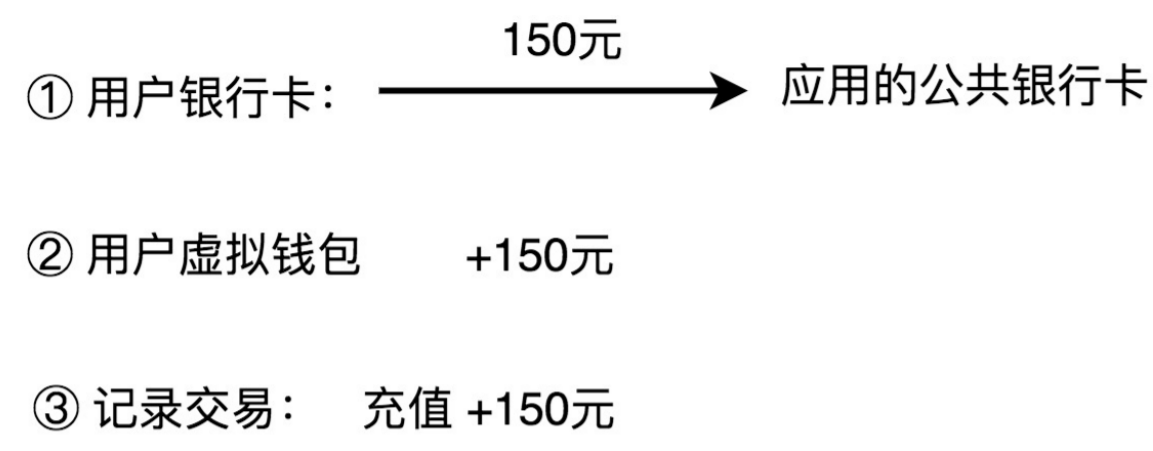
1.1、 充值
用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中
1.2、 支付
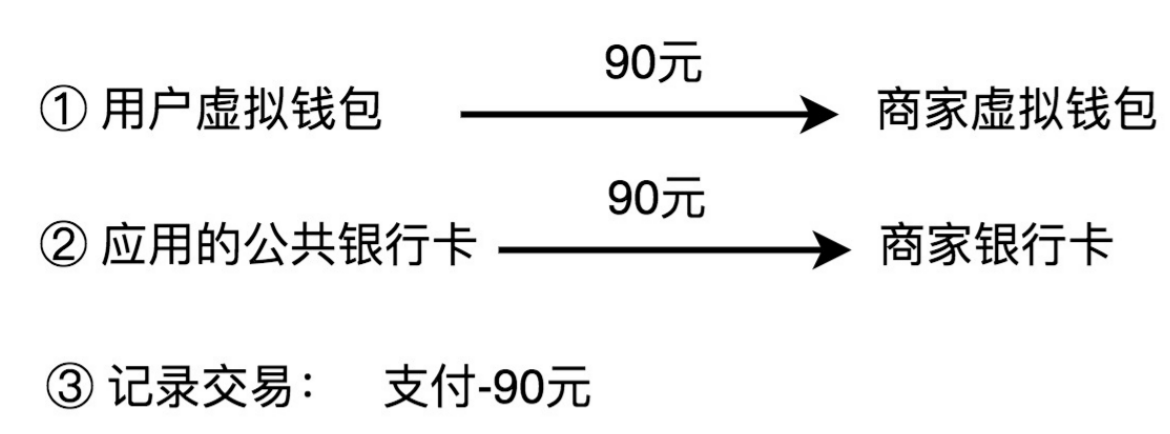
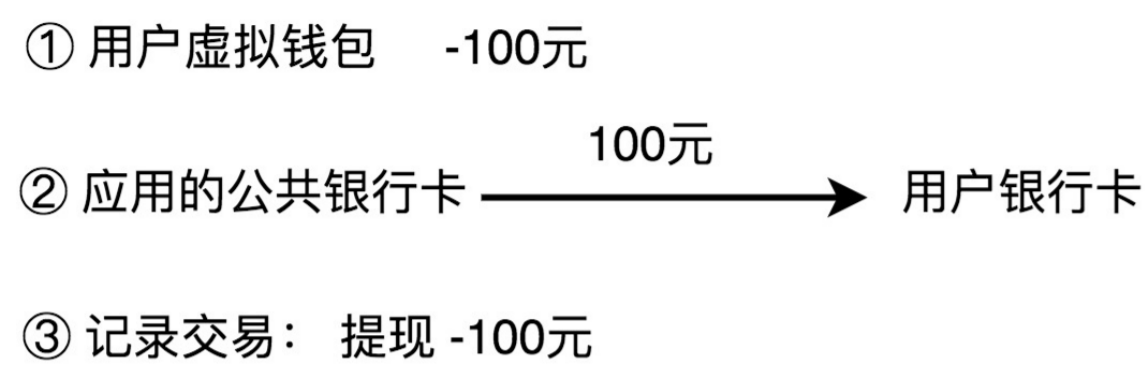
1.3、 提现
1.4、 查询余额
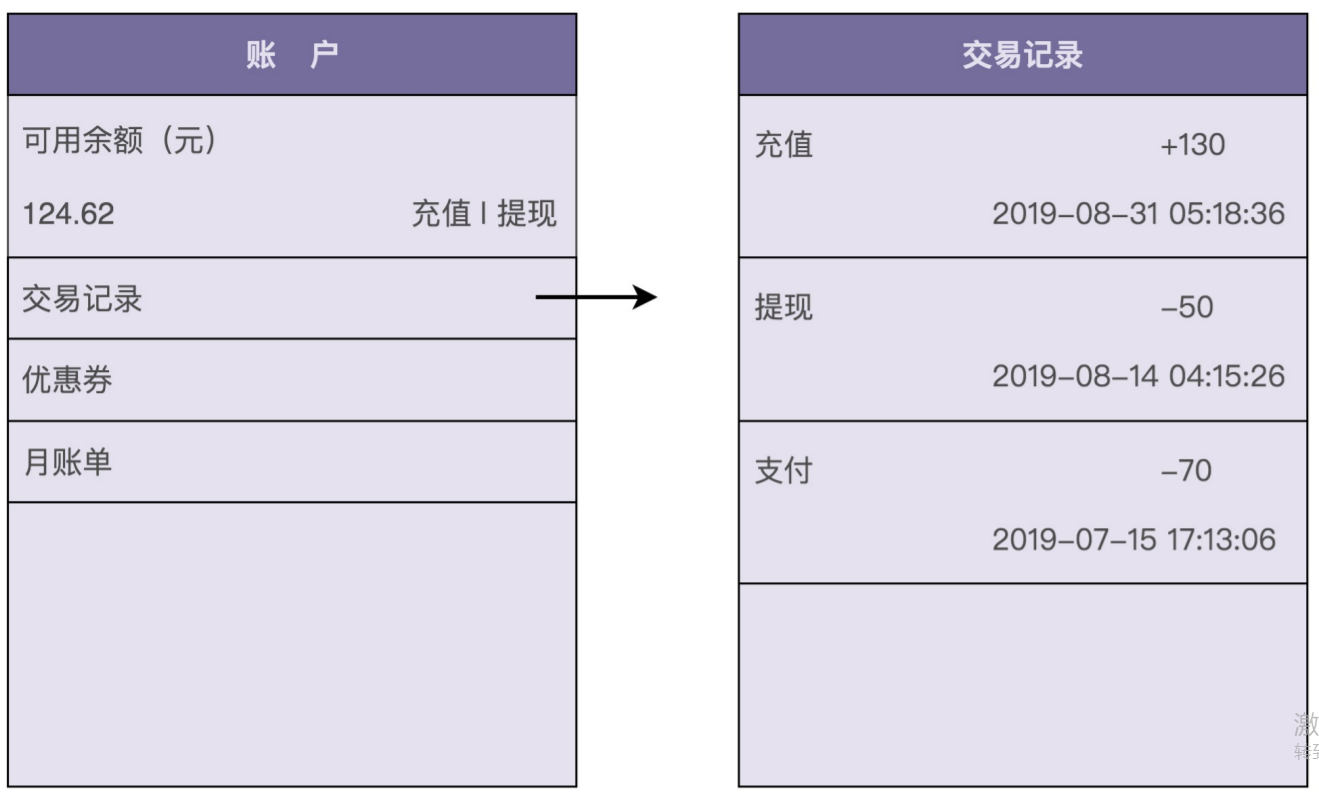
我们看一下虚拟钱包中的余额数字
1.5、 查询交易流水
查询交易流水也比较简单。我们只支持三种类型的交易流水:充值、支付、提现。在用户充 值、支付、提现的时候,我们会记录相应的交易信息。在需要查询的时候,我们只需要将之 前记录的交易流水,按照时间、类型等条件过滤之后,显示出来即可
1.6、 钱包系统的设计思路
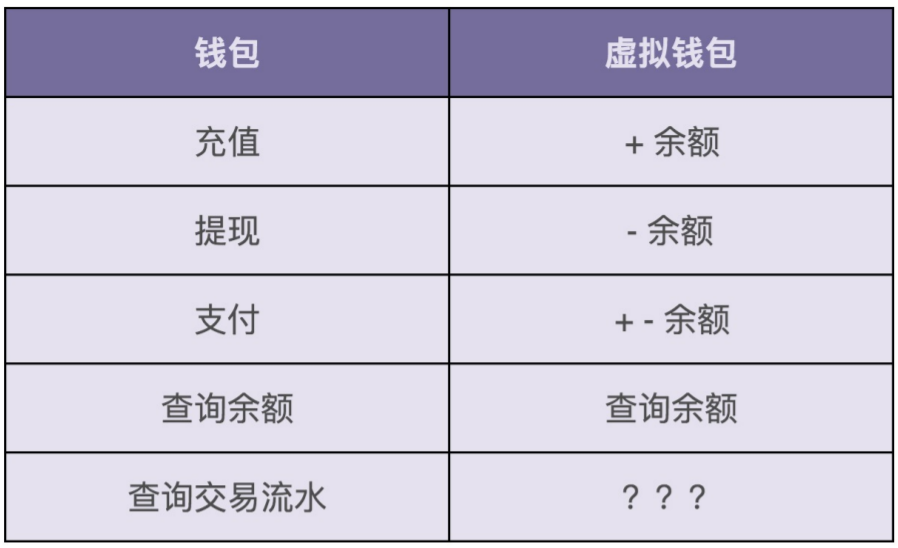
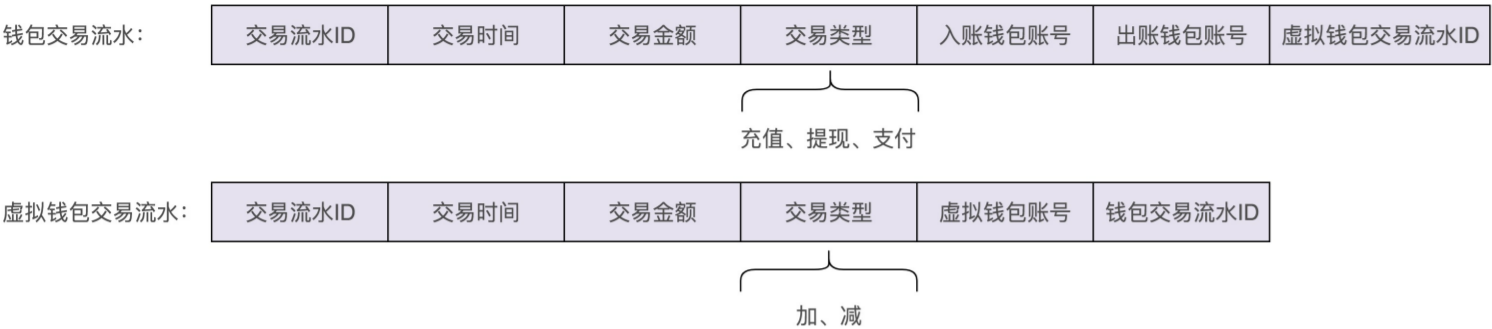
如上图可以看出从两个方向就会两种不同的主表和字段,
- 第一种设计思路更好些。因为交易流水有两个功能:一个是业务功能,比如,提供用 户查询交易流水信息;另一个是非业务功能,保证数据的一致性。这里主要是指支付操作数 据的一致性
- 保证数据一致性的方法有很多,比如依赖数据库事务的原子性 ,但是,这样的做法不够灵活,因为我们的有可能做了分库分表,支付涉及的两个账 户可能存储在不同的库中,无法直接利用数据库本身的事务特性
- 但是,为了保证数据的强一致性,它们的实现逻辑一般都比较复杂,本身的性能也不高,会影响业务的执行时间 . 不保证数据的强一致性,只实现数据的最终一致性 ——-> 交易流水要实现的非业务功能
- 实际需要最终结果一致性业务的情况
第一种方式(钱包交易流水) √
支付这样的类似转账的操作,我们在操作两个钱包账户余额之前,先记录交易流水,并 且标记为“待执行”,当两个钱包的加减金额都完成之后,我们再回过头来,将交易流水标 记为“成功”。在给两个钱包加减金额的过程中,如果有任意一个操作失败,我们就将交易 记录的状态标记为“失败”。我们通过后台补漏 Job,拉取状态为“失败”或者长时间处 于“待执行”状态的交易记录,重新执行或者人工介入处理。
~~第二种方式(虚拟钱包交易流水) ~~
~~使用两条交易流水来记录支付操作,那记录两条交易 流水本身又存在数据的一致性问题,有可能入账的交易流水记录成功,出账的交易流水信息 记录失败 ~~
问题:
从系统设计的角度,我们不应该在虚拟钱包系统的交易流水中记录交易类型。
从产品需求的角度来说,我们又必须记录交易流水的交易类型
解决对策
我们通过方式一查询上层钱包系统的交易流水信息,去满足用户查询交易流水的功能需求,而虚拟 钱包中的交易流水就只是用来解决数据一致性问题。实际上,它的作用还有很多,比如用来 对账等。限于篇幅
2、 基于贫血模型的传统开发模式
https://gitee.com/daoshizhuagui/designpatene.git
chapter12中mvc
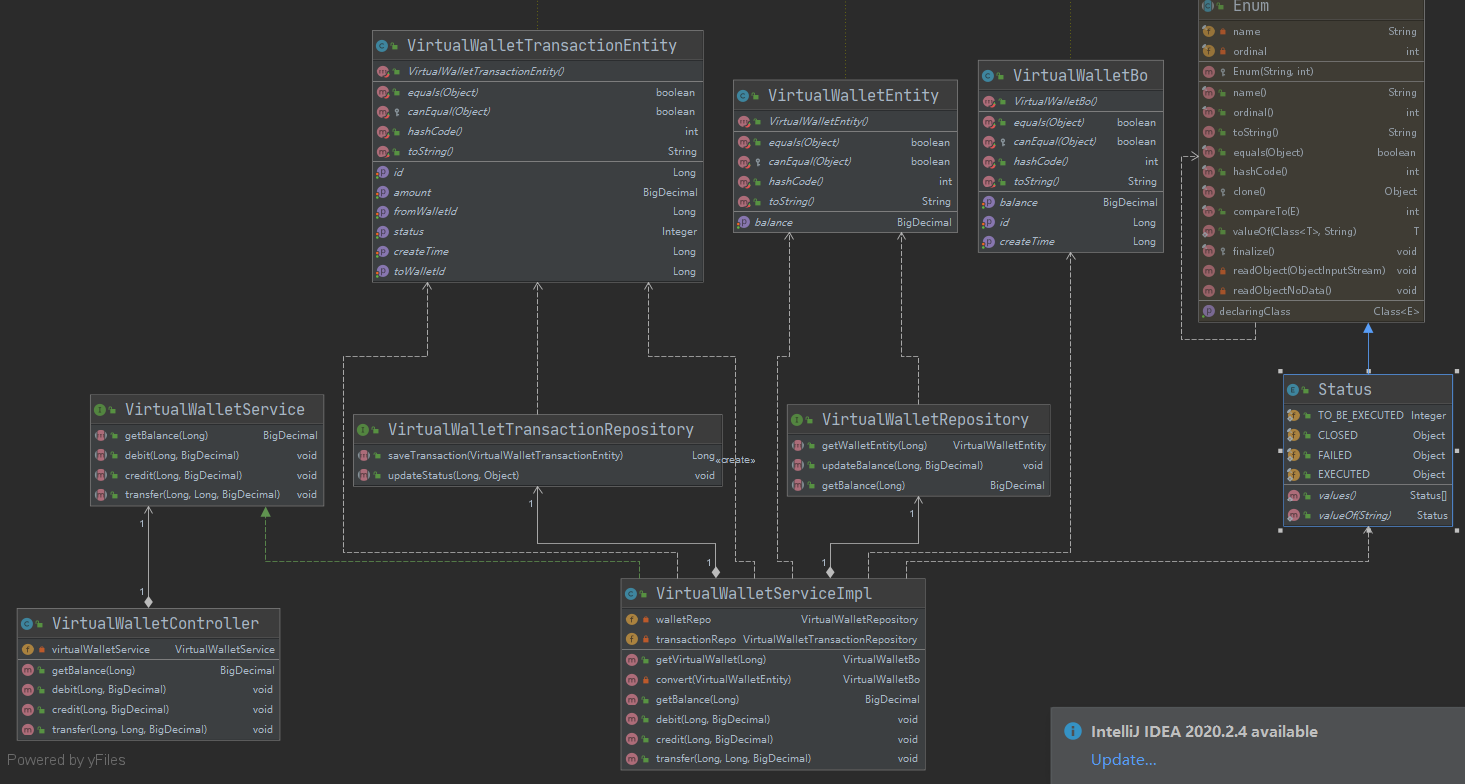
3、 基于充血模型的 DDD 开发模式
代码同上哈
本质就是精简了业务模型,将部分业务逻辑放在实体类中
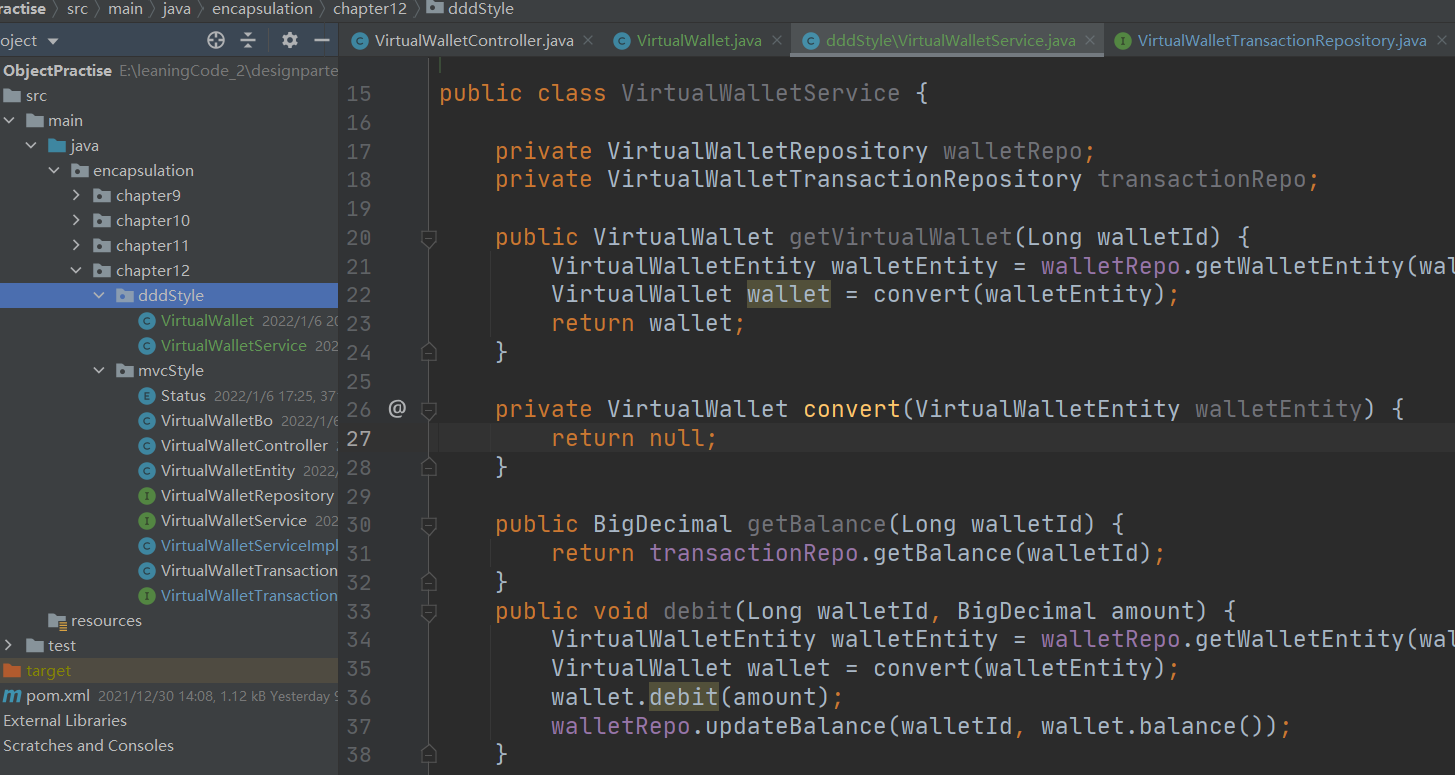
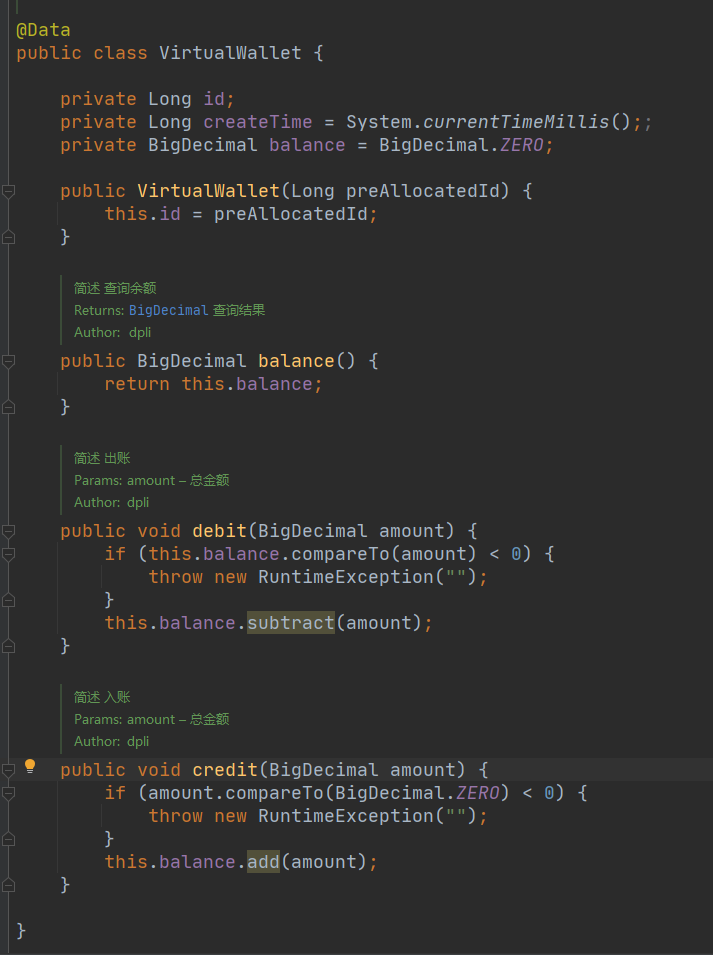
4、 辩证思考与灵活应用
4.1在基于充血模型的 DDD 开发模式中,将业务逻辑移动到 Domain 中,Service 类变得很薄,但在我们的代码设计与实现中,并没有完全将 Service 类去掉,这是为什么?或者说,Service 类在这种情况下担当的职责是什么?哪些 功能逻辑会放到 Service 类中?
- Service 类负责与 Repository 交流
- .Service 类负责跨领域模型的业务聚合功能
- .Service 类负责一些非功能性及与三方系统交互的工作
4.2 在基于充血模型的 DDD 开发模式中,尽管 Service 层被改造成了 充血模型,但是 Controller 层和 Repository 层还是贫血模型,是否有必要也进行充血领 域建模呢?
没必要Controller 层主要负责接口的暴露,Repository 层主要负责与数据库打 交道,这两层包含的业务逻辑并不多,前面我们也提到了,如果业务逻辑比较简单,就没必 要做充血建模,即便设计成充血模型,类也非常单薄,看起来也很奇怪。 尽管这样的设计是一种面向过程的编程风格,但我们只要控制好面向过程编程风格的副作 用,照样可以开发出优秀的软件。那这里的副作用怎么控制呢

若有收获,就点个赞吧
0 人点赞
