Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库。从字面上理解,Prometheus由两个部分组成,一个是监控报警系统,另一个是自带的时序数据库(TSDB)。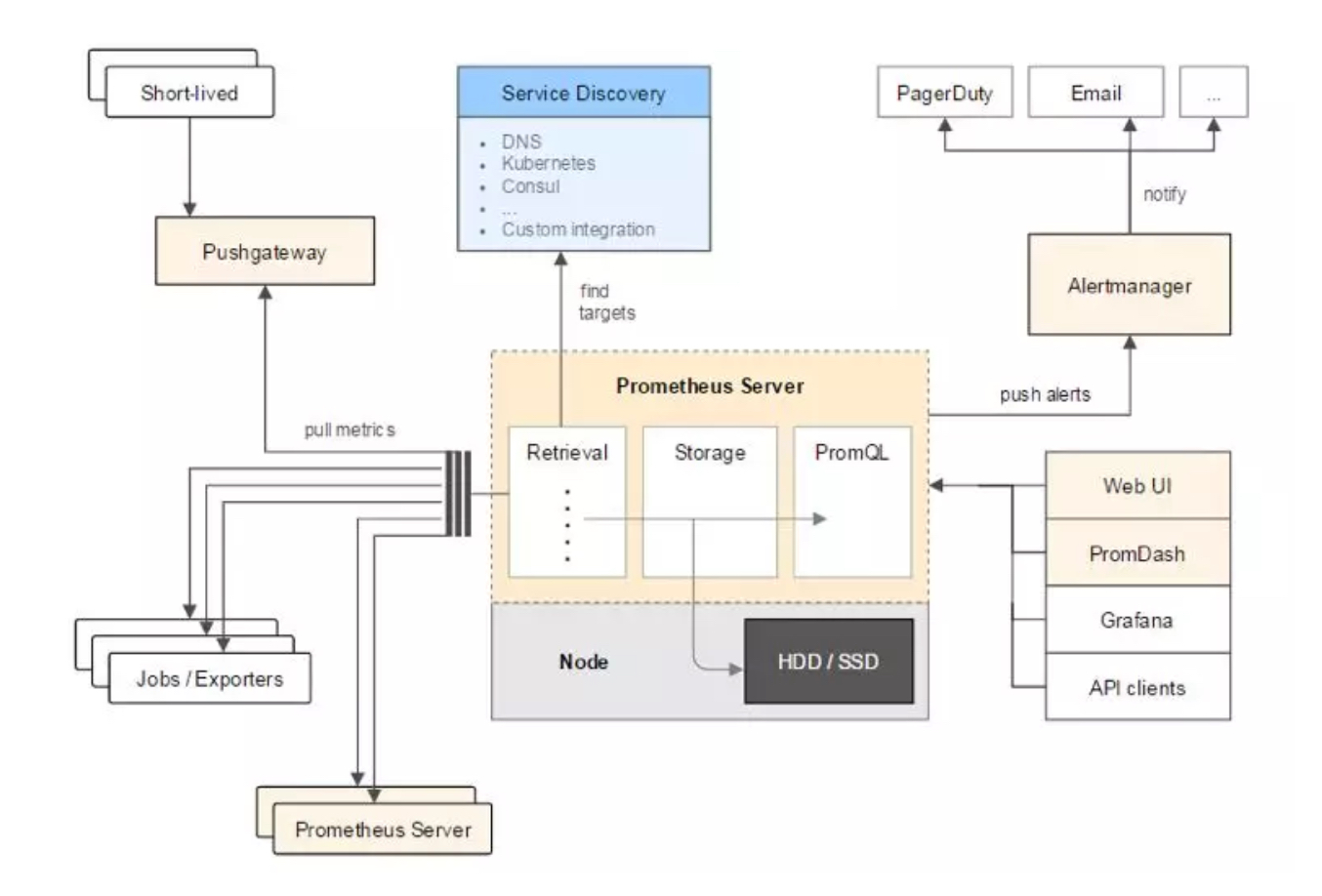
上图是Prometheus整体架构图,左侧是各种符合Prometheus数据格式的exporter,除此之外为了支持推动数据类型的Agent,可以通过Pushgateway组件,将Push转化为Pull。Prometheus甚至可以从其它的Prometheus获取数据,组建联邦集群。Prometheus的基本原理是通过HTTP周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口并且符合Prometheus定义的数据格式,就可以接入Prometheus监控。
上侧是服务发现,Prometheus支持监控对象的自动发现机制,从而可以动态获取监控对象。
图片中间是Prometheus Server,Retrieval模块定时拉取数据,并通过Storage模块保存数据。PromQL为Prometheus提供的查询语法,PromQL模块通过解析语法树,调用Storage模块查询接口获取监控数据。
图片右侧是告警和页面展现,Prometheus将告警推送到alertmanger,然后通过alertmanger对告警进行处理并执行相应动作。数据展现除了Prometheus自带的WebUI,还可以通过Grafana等组件查询Prometheus监控数据。
监控告警遇到的坑:
1、基于metrics的数据间隔采样设计,会丢失一部分数据准确性,采集间隔越大,数据越不精确。比如在两次采样的间隔中,内存用量有一个瞬时小尖峰,那么这次小尖峰我们是观察不到的
2、首先得做好自监控,不能指望监控系统挂掉之后自己能发现自己挂了
3、prometheus若发现意外重启,可能会导致存储文件发生损坏丢失了历史监控数据
4、警报和历史趋势图未必 Match,趋势图上每个采样点的采样时间和警报规则每次的计算时间不是严格一致的。当时间区间拉得比较大的时候,采样点非常稀疏,不如警报计算的间隔来得密集,这个现象尤为明显
5、警报resolved不能立即发送resolved通知,必须要等待group_interval时长才能发送

若有收获,就点个赞吧
0 人点赞
