参考:
伪标签半监督学习
实际应用Pseudo Labeling pipeline
伪标签,即,将测试集中判断结果正确的置信度高的样本加入到训练集中,从而模拟一部分人类对新对象进行判断推演的过程。效果比不上人脑那么好,但是在监督学习问题中,Pseudo Labeling几乎是万金油,肯定能够让你模型各个方面的表现都得到提升。
因此,伪标签不是将所有测试集数据加入到训练集,而是,用训练好的模型对测试数据进行预测,若预测类别的softmax值(即预测概率)大于某一设定的阈值(eg. 0.9, 0.95等),则将该测试数据加入到训练集。
流程图如下: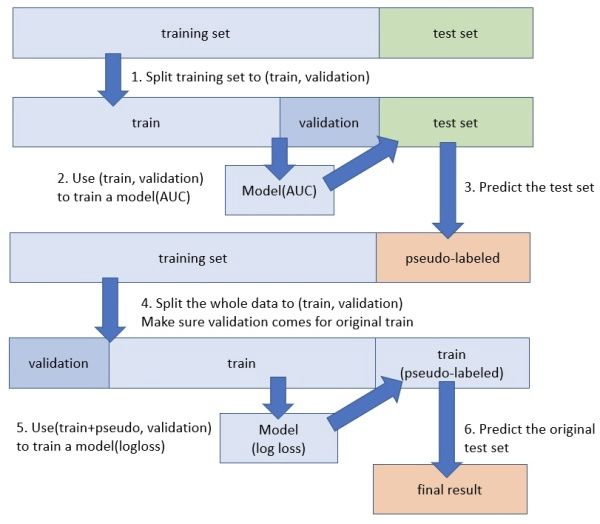
- 使用原始训练数据划分训练集和验证集
- 使用划分的训练集和验证集训练一个模型
- 使用训练好的模型对测试集进行预测分类
- 若训练数据的预测类别对应的softmax值高于一定的阈值,将该训练数据加入到训练集中
- 使用结合了部分测试集样本的新训练集,重新训练一个模型
- 使用新训练的模型对测试集再次进行预测,得到最终结果
个人想法:
- 问:只将测试集中置信度高的样本加入到训练集中,为什么会提升模型性能呢?置信度高,说明本来就是易分类样本,那如何会影响到难分类样本的分类效果?
- 答:有些难分类的样本和易分类样本可能比较相似,可能能提升这部分样本的分类准确率。

若有收获,就点个赞吧
0 人点赞
