线程waitting到runnable切换也就是上下文切换,是需要时间代价的,这个就需要根据具体情况去衡量,多少个线程运行合适,
windows下可以使用visulavm查看进行pid,或者命令行输入 jps
输出线程信息到文件
jstack pid > 文件全路径
统计线程状态
grep 关键字 文件名 | awk ‘{print $2$3$4$5}’ |sort|uniq -c
grep java.lang.Thread.State dump | awk ‘{print $2$3$4$5}’ |sort|uniq -c
一、Java并发基础原理
1. synchronized
是通过进入和退出monitor对象来实现方法同步和代码块同步,代码块同步使用monitorEnter和monitorExit指令来实现,方法同步使用另外一种方式实现(细节书里面没有说)。但是,方法的同步统一可以使用这两个指令来实现
1.1 偏向锁
大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获取锁的代价更低引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块的时候不需要CAS操作来加锁和解锁,只需要测试一下对象头里是否存着指向当前线程的偏向锁。
偏向锁的撤销,需要等待全局安全点(在这个时间点上没有正在执行的字节码)。首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否存活,如果线程不处于活动状态,则将对象头设置成无锁状态。如果线程还存活,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录,栈中的锁记录和对象头的Mark Word要么重新偏向于其他线程,恢复到无锁状态或者标记对象不合适作为偏向锁,最后唤醒暂停的线程。
1.2 轻量级锁
加锁和解锁都采用CAS进行,所以是轻量级的。
加锁
线程执行同步块之前,JVM会先在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,当前线程尝试自旋来获取锁。
解锁
解锁的时候会使用CAS将Displaced Mark Word替换回到对象头,如果成功,就没有竞争发生。如果失败,表示当前锁存在竞争,锁膨胀为重量级锁。
1.3 重量级锁
竞争时线程会阻塞,有上下文切换过程,比较耗费资源
1.4 锁对比
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁解锁不需要额外的消耗 | 如果线程间存在竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步块场景 |
| 轻量级锁 | 竞争过程线程不会阻塞,提高了程序响应速度 | 如果始终得不到锁竞争的线程,使用自旋会消耗CPU | 最求响应时间 同步块执行速度非常快 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量 同步块执行速度较长 |
2. volatile
volatile是一种轻量级锁,能够保证在多处理器开发中保证线程共享变量的可见性,java语言规范对volatile的定义为:java语言规范允许线程访问共享变量,为了确保共享变量能够被准确和一致性地更新,线程应该确保通过排它锁单独获得这个变量。
volatile变量进行写操作的时候,会在汇编指令里面插入lock指令,lock指令的作用:
1)将当前处理器缓存行的数据写回系统内存
2)这个回写内存的操作会使在其他CPU里缓存了该地址的数据无效。
3. 原子操作实现原理
原子操作是指不可中断的一个或者一系列操作,处理器通过总线锁和缓存锁来保证原子性,java通过CAS操作实现原子操作。
CAS存在三个问题:
1)ABA问题;
2)循环时间长开销大;
3)只能保证一个共享变量的原子操作
CAS操作利用的处理器提供的CMPXCHG指令实现的,自旋CAS实现就是循环进行CAS操作直到成功。同时有volatile的写/读语义
二、Java内存模型
2.1 Java内存模型基础
java内存模型采用共享内存模型,线程间通信总是隐式进行,通信对程序员透明,线程直接通信由JMM控制,JMM定义了线程和主内存之间的抽象关系:线程直接的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。
JMM通过控制主内存与每个线程的本地内存之间的交互,来为java程序员提供内存可见性。线程直接的通信也是通过主内存完成的。
重排序:
1)编译器重排序,在不改变单线程语义的情况下对指令重排序;
2)指令级并行的重排序;
3)内存系统的重排序。如果要禁止重排序,在编译器生成指令序列的时候要插入特定的内存屏障
happens-before规则:
程序顺序规则:一个线程中的每个操作,hanppens-before于该线程中的任意后续操作
监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁
volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
传递性:如果A happens-before B,且B happens-before C , 那么A happens-before C。
两个操作如果有happens-before关系,仅要求前一个操作的结果对后一个操作可见
单CPU和CPU多级缓存示意图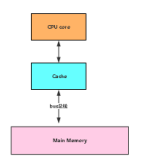
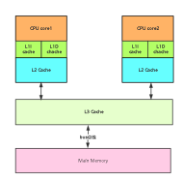
2.1.1 缓存cache 的作用:
CPU 的频率很快,主内存跟不上 cpu 的频率,cpu 需要等待主存,浪费资源。所以 cache 的出现是解决 cpu
和内存之间的频率不匹配的问题。
缓存cache 带来的问题:
并发处理的不同步
解决方式有:总线锁、缓存一致性。
2.1.2 缓存一致性 :
MESI 协议缓存状态
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M修 改 (Modified) |
该 Cache line 有效,数据被修改 了,和主内存中的数据不一致, 数据只存在于本 Cache 中。 |
缓存行必须时刻监听所有试图读该缓存行相对就主存的 操作,这种操作必须在缓存将该缓存行写回主存并将状态 |
变成 S(共享)状态之前被延迟执行 |
| E 独享、互斥
(Exclusive) | 该 Cache line 有效,数据和内存
中的数据一致,数据只存在于本
Cache 中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一
旦有这种操作,该缓存行需要变成 S(共享)状态。 |
| S 共 享
(Shared) | 该 Cache line 有效,数据和内存
中的数据一致,数据存在于很多
Cache 中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该
缓存行的请求,并将该缓存行变成无效(Invalid) |
| I 无 效
(Invalid) | 该 Cache line 无效。 | 无 |
Heap(堆):
java 里的堆是一个运行时的数据区,堆是由垃圾回收来负责的,
堆的优势是可以动态的分配内存大小,生存期也不必事先告诉编译器,
因为他是在运行时动态分配内存的,java 的垃圾回收器会定时收走不用的数据,
缺点是由于要在运行时动态分配,所有存取速度可能会慢一些
Stack(栈):
栈的优势是存取速度比堆要快,仅次于计算机里的寄存器,栈的数据是可以共享的,
缺点是存在栈中的数据的大小与生存期必须是确定的,缺乏一些灵活性
栈中主要存放一些基本类型的变量,比如 int,short,long,byte,double,float,boolean,char,
对象句柄,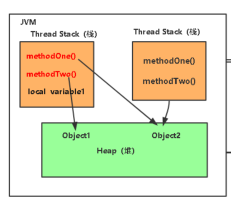
Java 并发编程的三个概念
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
可见性:可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看
得到修改的值。
有序性: 即程序执行的顺序按照代码的先后顺序执行
程序顺序和我们的编译运行的执行一定是一样
编译优化
指令重排
Happens-before:
传递原则:lock unlock
A>B>C A>C
内存同步: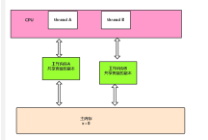
2.2 volatile
volatile写的内存语义
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存中
volatile读的内存语义
当读一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量置为无效,然后从主内存中读取
volatile内存语义的实现
为了实现volatile的内存语义,编译器在生成字节码的时候,会插入内存屏障来禁止特定类型的处理器重排序
每个volatile写操作的前面插入一个StoreStore屏障
每个volatile写操作的后面插入一个StoreLoad屏障
每个volatile读操作的前面插入一个LoadLoad屏障
每个volatile读操作的后面插入一个LoadStore屏障
2.2 锁
锁的获取和释放的内存语义
当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中,当线程获取锁时,JMM会把线程对应的本地内存置为无效,从而使被监视器保护的临界区代码必须从主内存中读取共享变量。
锁内存语义的实现
锁的实现背后是借助volatile变量,使用CAS操作来实现,CAS操作同时具有volatile读和写的内存语义
Lock 的获取分公平和非公平,公平锁和非公平锁最后都会写一个volatile变量;公平锁获取先读volatile变量,非公平锁先用CAS更新volatile变量
2.3 final
通过禁用重排序规则来实现final的内存语义
写final域的重排序规则
1)禁止把final域的写重排序到构造函数之外
2)编译器会在final域写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
读final域的重排序规则:在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作。编译器会在读final域操作的前面插入一个LoadLoad屏障。
双重检查锁与延迟初始化
由于new一个对象要分三步:1)申请空间;2)初始化;3)设置实例内存地址,2/3之间可能会出现重排序,导致没有初始化完就分配了地址,出现问题,可以采用以下几种方案:
1)使用volatile修饰
2)基于类初始化的解决方案,利用类加载的特性,将创建实例包装到一个内部类,这样有虚拟机保证只会被初始化一次
2.4 happens-before
JMM向程序员提供的happens-before规则能满足程序员的需求。JMM的happens-before规则不但简单易懂,而且也向程序员提供了足够强的内存可见性
JMM对编译器和处理器的束缚已经尽可能少。
三、并发基础
3.1 线程
线程是现代操作系统调度的最小单位,也叫轻量级进程,一个进程可以创建多个线程。
线程状态:
1)new,初始状态,线程被构建,但是还没有调用start()方法
2)Runnable, 运行状态,java线程将操作系统中的就绪状态和运行状态笼统地称作“运行中”
3)blocked, 阻塞状态,表示线程阻塞于锁
4)waiting, 等待状态,表示线程进入等待状态,进入该状态表示当前线程需要等待其他线程做出一些特定动作(通知或中断)
5)time_waiting,超时等待状态,该状态不同于waiting,它是可以在指定的时间自行返回的
6)terminaled, 终止状态,表示当前线程已经执行完毕
调用wait(),notify(),notifyAll()需要注意:
1)调用前需要先获得对象的锁
2)调用wait()方法后,线程由RUNNING状态转为WAITING状态,并加入等待队列
3)notify(),notifyAll()调用后等待线程还不会从wait()返回,需要等到线程释放锁之后等待线程才会返回
4)notify()将等待队列中的一个线程移到同步队列,notifyAll()将等待队列所有线程全部移到等待队列,等待线程状态由WAITING变为BLOCKED
使用多线程的原因:
1)更多的处理器核心
2)更快的响应时间
3)更好的编程模型
3.1.1 Thread.join()的使用
这个方法的作用就是当前线程等待thread线程执行完毕后才从join返回
3.2 ThreadLocal的使用
线程变量,用来存储线程独享的数据,可以使用get、set方法进行取、存,可以应用于关键参数的传递,计算方法执行时间等,使用线程作为key
四、锁
Lock接口提供的特性:1)非阻塞的获取锁;2)能被中断地获取锁;3)超时获取锁
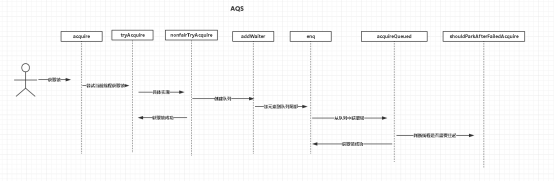
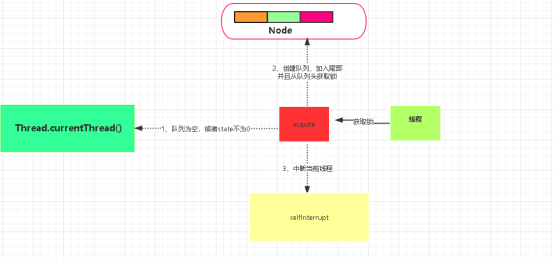
4.1 队列同步器
队列同步器,AbstractQueuedSynchronizer是用来构建锁或者其他同步组件的基础框架,使用一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作.
同步器的主要使用方式是继承,通过实现相应的方法来控制同步状态,通过CAS算法来保证状态的修改是安全的,既可以支持独占式获取,也可以支持共享式地获取同步状态。
同步器是实现锁的关键,在锁的实现中聚合同步器,利用同步器实现锁的语义。锁是面向使用者的,它定义了使用者与锁交互的接口,隐藏了实现细节;同步器是面向实现者的,它简化了锁的实现方式,屏蔽了同步状态管理、线程排队、等待与唤醒等底层操作。锁和同步器很好地隔离了使用者和实现者所需关注的领域。
4.2 重入锁
ReentrantLock能够被一个线程多次加锁,还支持公平和非公平选择,默认是非公平锁
实现重进入
需要解决两个问题:
1)线程再次获取锁,通过判断当前线程时候是获取锁的线程来决定是否获取成功;
2)锁的最终释放,已经获取锁的线程再次获取锁时,只是增加同步状态值,释放锁时也会减少同步状态值
公平锁与非公平锁的区别
对于非公平锁先通过CAS设置同步状态,如果成功代表同步状态设置成功,公平锁还有一个是否有前驱节点的判断。
4.3 读写锁
读写锁允许多个读线程访问,当写线程访问时,其他所有线程均被阻塞,读写锁维护了一对读锁、一对写锁,通过分离读锁和写锁,大大提升了性能。
实现分析
读写状态设计
读写锁同样依赖自定义同步器来实现同步功能,在同步状态上维护多个读线程和写线程的状态,采用“按位切割使用”这个变量,高16位表示读,低16位表示写
写锁的获取与释放
写锁支持重进入的排它锁,如果当前线程获得了写锁,则增加写状态,如果存在读锁,则写锁不能被获取
读锁的获取与释放
读锁是一个支持重进入的共享锁,能够被多个线程同时获取,没有写线程访问时,可以被多个读线程获取
锁降级
降级指的是写锁降级为读锁,把持着写锁,然后获得读锁,最后再释放写锁。如果当前线程不获取读锁而是直接释放写锁,假设此刻另一个线程T获取了写锁并修改了数据,那么当前线程无法感知线程T的数据更新。如果遵循锁降级的步骤,则线程T将会被阻塞,直到当前线程使用数据并释放读锁之后,线程T才能获取读锁进行数据更新。
4.4 LockSupport
当需要阻塞或唤醒一个线程的时候,都会使用LockSupport工具类来完成相应工作,提供了park/unpark实现。
4.5 Condition
Condition接口提供了类似Object的监视器方法,与Lock配合可以实现等待通知模式,在调用condition.await()方法之前需要先获得锁
1、等待队列
等待队列是一个先进先出队列,每个节点都包含了一个线程的引用
2、等待
调用await()方法会是当前线程进入等待队列,并释放锁
3、通知
调用signal()方法,会唤醒在等待队列中等待时间最长的节点,唤醒之前会将节点移到同步队列中
Lock(更确切地说是同步器)拥有一个同步队列和多个等待队列。
五、并发容器和框架
5.1 ConcurrentLinkedQueue
是一个基于链接节点的无界线程安全队列,采用先进先出的规则进行排序
5.2 阻塞队列
阻塞队列是一个支持两个附加操作的队列:
1)支持阻塞的插入方法:当队列满时,队列会阻塞插入元素的线程,直到队列不满
2)支持阻塞的移除方法:当队列为空时,获取元素的线程会等待队列变为非空
当队列不可用时有四种方式:
1)抛出异常:
2)返回特殊值
3)一直阻塞
4)超时退出
5.2.1 ArrayBlockingQueue
是一个用数组实现的有界阻塞队列,按照先进先出对元素进行排序,默认情况下不保证线程公平的访问队列
5.2.2 LinkedBlockingQueue
是一个用链表实现的有界阻塞队列,默认最大长度为Integer.MAX_VALUE
5.2.3 PriorityBlockingQueue
是一个支持优先级的无界阻塞队列,默认采用自然升序排列,也可以自定义排序规则,需要注意的是不能保证同优先级元素的排序
5.2.4 DelayQueue
是一个支持延时获取元素的无界阻塞队列,队列使用PriorityQueue来实现,元素必须实现Delayed接口,创建元素时可以指定需要多久才能从队列中拿到元素,运用场景:
1)缓存系统设计:用DelayQueue保存缓存有效期,使用现场循环查询DelayQueue
2)定时任务调度:使用DelayQueue保存需要执行的任务
5.2.5 SynchronousQueue
是一个不存储元素的阻塞队列,每个put必须等待一个take操作,否则不能继续添加元素。
5.2.6 LinkedTransferQueue
是一个由链表结构组成的无界阻塞队列,多了两个方法transfer和tryTransfer
1)transfer:当有消费者在等待接收元素时,transfer可以立刻将元素传输给消费者,如果没有消费者,transfer方法会将元素放在队列的tail节点,等到该元素被消费者消费了才返回。因为自旋会消耗CPU,所以自旋一定次数后使用Thread.yield()方法来暂停当前正在执行的线程,并执行其他线程。
2)tryTransfer:试探是否有消费者等待接收元素,有就返回true,没有就返回false
5.2.7 LinkedBlockingDeque
是一个由链表组成的双向阻塞队列
5.2.8 阻塞队列实现原理
使用通知模式实现,所谓通知模式,当生产者添加元素被阻塞,当消费者消费了一个元素后,会通知生产者当前队列可用,代码的底层实现,是用了LockSupport的park/unpark来实现阻塞的。
5.3 Fork/Join框架
Fork/Join框架是一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇聚每个小任务结果后得到大任务结果的框架。
5.3.1 工作窃取算法
是指某个线程从其他线程任务队列里窃取任务来执行,通常使用双端队列,一个从头部拿,一个从尾部拿。
优点:充分利用线程进行并行计算,减少了线程间的竞争
缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时,并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
5.3.2 异常处理
由于在主线程里没办法直接捕获异常,可以通过ForkJoinTask的isCompletedAbnormally
5.3.3 实现原理
fork实现原理
当调用ForkJoinTask的fork方法时,会调用ForkJoinWorkerThread的push方法,并立即返回this,push方法
把当前任务放到ForkJoinTask数组队列里,然后调用ForkJoinPool的signalWork()方法唤醒或者创建一个工作线程来执行任务。
join实现原理
作用是阻塞当前线程并等待获取结果,首先调用doJoin()方法判断当前任务的状态,如果是已完成直接返回结果
如果是取消或者抛出异常,会抛出异常
六、原子类
6.1 原子更新基本类型
AtomicBoolean、AtomicInteger、AtomicLong(AtomicLong和AtomicBoolean底层都是用AtomicInteger来实现),以AtomicInteger为例
1)int addAndGet 以原子方式将输入的数值与实例中的值相加,并返回结果
2)boolean compareAndSet(int expect, int update) 如果输入的值等于预期值,则以原子方式设置为输入的值
3)int getAndIncrement() 以原子方式将当前值加一,并返回自增前的值
4)void lazySet(int newValue) 延迟设置值,调用方法后的一小段时间内,其他线程还是可以读到旧值的
5)int getAndSet(int newValue) 以原子方式更新成newValue值,并返回旧值
6.2 原子更新数组
AtomicLongArray,AtomicReferenceArray,AtomicIntegerArray,以AtomicIntegerArray为例:
1)int addAndGet(int i, int delta) 以原子方式将输入值与数组中索引i的元素加一
2)Boolean compareAndSet(int i, int expect, int update) 如果当前值等于预期值,则以原子方式将数组位置i的元素设置为update值
通过构造方法传进去的数组,AtomicIntegerArray会复制一份,当修改时不会影响传入的数组。
6.3 原子更新引用类型
AtomicReference(原子更新引用类型)、AtomicRefenceFieldUpdater(原子更新引用类型里的字段)、AtomICMarkableReference(原子更新带有标记的引用类型),可以用来更新多个变量,以AtomicReference为例
调用compareAndSet进行原子更新
6.4 原子更新字段类
如果需要更新某个类里面的某个字段时,就需要原子更新字段类,AtomicIntegerFieldUpdater(原子更新整型字段更新器),AtomicLongFieldUpdater(原子更新长整型更新器),AtomicStampedReference(原子更新带有版本号的引用类型,可以解决CAS更新的ABA问题)
七、并发工具类
7.1 等待多线程完成的CountDownLatch
允许一个或多个线程等待其他线程完成操作,构造函数接受一个int的参数作为计数器,当调用countDown()方法时计数器会减一,await()方法会阻塞当前线程,直到计数器变为0,await()方法有个带超时时间的方法,可以避免无线等待
7.2 同步屏障CyclicBarrier
让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障后,所有线程才能继续执行,还有个更高级的构造方法CyclicBarrier(int paries, Runnable barrierAction) 当线程都到达屏障后,优先执行barrierAction,方便处理更复杂的业务场景
7.3 CountDownLatch和CyclicBarrier比较
CountDownLatch只能使用一次,而CyclicBarrier可以用reset()方法重置,CyclicBarrier可以处理更复杂的场景
7.4 控制并发线程数的Semaphore
是用来控制同时访问特定资源的线程数量,通过协调线程,保证合理利用公共资源,可以用来做流量控制
7.5 线程间交换数据的Exchange
是一个用于线程间协作的工具类,可以进行线程间数据交换,它提供一个同步点,在这个点上,两个线程可以交换彼此数据,通过exchange() 方法交换数据,可用于遗传算法
八、线程池
8.1 实现原理
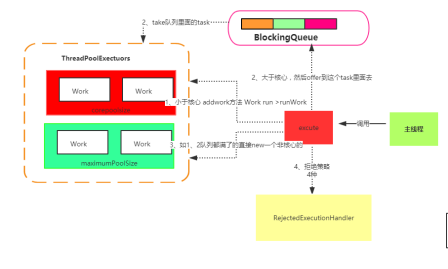
当提交一个新任务时
1)先判断核心线程池里的线程是否都在执行任务,如果不是则选取一个线程执行任务,如果核心线程都在执行任务,进入下一个流程;
2)判断工作队列是否已经满了,如果没满,就存到工作队列,如果满了,就进入下个流程;
3)判断线程池的线程是否都处于工作模式,如果没有就创建一个新的工作线程来执行任务,如果已经满了,就交给饱和策略处理任务

8.2 使用
使用new ThreadPoolExecutor(corePoolSize,maximumPoolSize,keepAliveTime,unit,workQueue,threadFactory,handler)
1)corePoolSize,核心线程的数量,当提交一个任务时,如果核心线程数量还没有达到corePoolSize,会直接创建新线程执行,如果调用prestartAllCoreThreads()方法,会提前创建并启动所有核心线程
2)maximumPoolSize,线程池最大数量,当提交新的任务时,如果任务队列满了,并且已创建的线程数小于maximumPoolSize的值,会创建新的线程,当任务队列为无界队列的时候,这个参数不起作用,因为任务队列不会满
3)keepAliveTime,线程空闲后的存活时间
4)unit,keepAliveTime的单位
5)workQueue,任务队列,可以选择ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue
6)threadFactory,线程工厂,用来自定义创建线程的一些参数,例如线程名称,组的信息,方便查找问题
7)handler,拒绝策略,挡队列和线程池都满了的时候,采取的措施,jdk提供了一下几种:
AbortPolicy:直接抛出异常
CallerRunsPolicy:由调用者执行
discardOldestPolicy:丢弃最近的一个任务,并执行当前任务
discardPolicy:直接丢弃
8.3 提交任务
提交任务有execute()提交不需要返回值的任务,submit()提交需要返回值的任务,返回一个Future对象,可以调用get方法获取返回值。
8.4 关闭线程池
可以调用shutdown或shutdownNow方法来关闭线程池,通常使用shutdown,如果不需要等任务执行完,可以调用shuntdownNow
8.5 合理配置
任务的特性可以从以下几点分析:
1)任务的性质:CPU密集型、IO密集型任务和混合任务
2)任务的优先级:高、中、低
3)任务的执行时长:长、中、短
4)任务依赖性:是否依赖其他系统资源,比如数据库连接
cpu密集型任务应尽量配置比较少的线程,IO密集型任务应配置尽可能多的线程,混合型任务,如果能拆分成一个CPU密集型任务和IO密集型任务,时间相差不多的话,分解执行任务会好点
优先级不同的任务可以使用优先级队列
执行时间可以交给不同规模的线程池来处理,或者可以使用优先级队列,让时间短的先执行
依赖性的任务,应该设置线程池尽量大,才能更好利用CPU
8.6 监控
taskCount:线程池需要执行的任务数量
completedTaskCount:线程池在运行过程中已完成的任务数
largestPoolSize:线程池里曾经创建过的最大线程数量
getPoolSize:线程池的线程数,只要线程池不销毁,这个只增不减
getActiveCount:获取活动的线程数

若有收获,就点个赞吧
0 人点赞
