一、DLedger引入目的
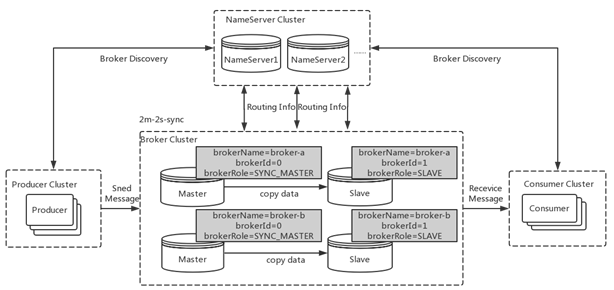
在4.5版本之前,rocketmq只有master/slave一种部署方式,一组broker中有一个master,有0到多个slave,slave通过同步复制或者异步复制的方式去同步master数据,这种部署方式由一定缺陷。比如故障转移方面,如果主节点挂了,还需要人为手动进行重启或者切换,无法自动将一个从节点转换为主节点。因此我们希望能够由一个新的多副本架构,去解决这个问题。
新的多副本架构受限需要解决自动故障转移的问题,本质上来说是自动选主的问题。这个问题的解决方案由两种
- 利用第三方协调服务集群完成选主,比如zookeeper或者etcd。这种方案会引入重量级外部组件,加重部署、运维和故障诊断成本,比如在维护rocketmq集群还需要维护zookeeper集群,并且zookeeper集群故障会影响到rocketmq集群
- 利用raft协议来完成自动选主,raft协议相比前者的优点是不需要引入外部组件,自动选主逻辑集成到各个节点的进程中,节点之间通过通信就可以完成选主。
因此最后选用raft协议来解决这个问题,而DLedger就是一个基于raft协议的commitlog存储库,也是rocketmq实现新的高可用多副本架构的关键。
二、DLedger设计理念
1、DLedger定位
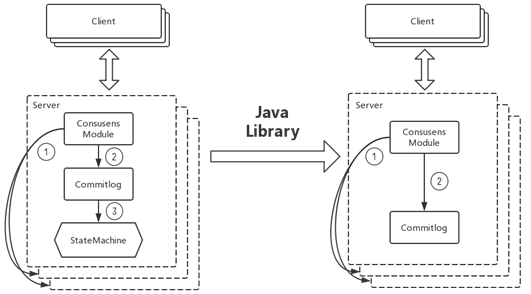
raft协议是复杂状态机的实现,这模型应用到消息系统中就会存在问题。对于消息系统来说,它本身是一个中间代理,commitlog状态是系统最终状态,并不需要状态机再去完成一次状态构建。因此DLedger去掉了raft协议中状态机部分,但基于raft协议保证commitlog是一致的,并且是高可用的。
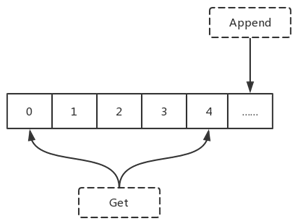
另一方面DLedger又是一个轻量级的java library。它对外提供的api非常简单,append和get。append向DLedger添加数据,并且添加的数据会对应一个递增的索引,而get课可以根据索引去获得相应的数据。因此DLedger是一个append only的日志系统。
2、DLedger应用场景
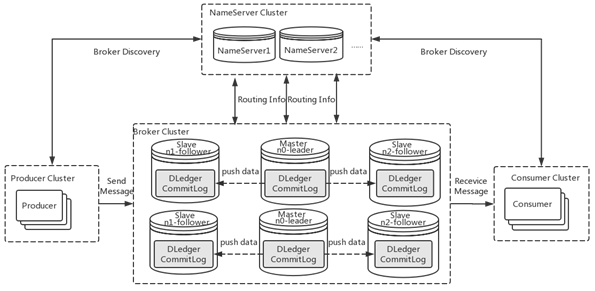
DLedger其中一个应用就是在分布式消息系统中,rocketmq4.5版本发布后,可以采用rocketmq on DLedger方式进行部署。DLedger commitlog代替了原来的commitlog,使得commitlog拥有了选举复制能力,然后通过角色透传的方式,raft角色透传给外部broker角色,leader对应原来的master,follower和candidate对应原来的slave。
因此rocketmq的broker拥有了自动故障转移能力。在一组broker中,master挂了以后,依靠DLedger自动选主能力,会重新选出leader,然后通过角色透传变成新的master。
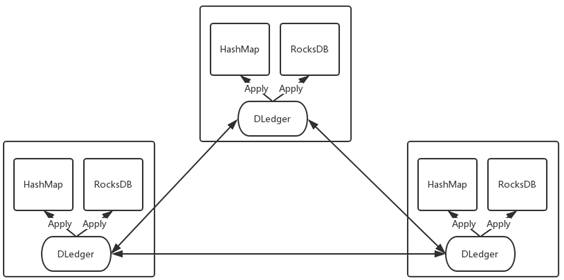
DLedger还可以构建高可用的嵌入式KV存储。我们把对一些数据的操作记录到DLedger中,然后根据数据量或者实际需求,恢复到hashmap或者rocksdb中,从而构建一致的、高可用的KV存储系统,应用到元信息管理等场景。
三、DLedger的优化
1、性能优化
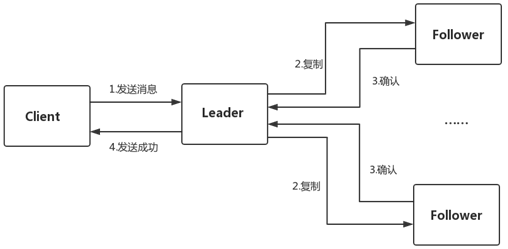
raft协议复制过程可以分为四步,先是发送消息给leader,leader除了本地存储之外,会把消息复制给follower,然后等待follower确认,如果得到多数节点确认,该消息就可以被提交,并向客户端返回发送成功的确认。DLedger中如何去优化这一复制过程?
1)异步线程模型
DLedger采用一个异步线程模型,异步线程模型可以减少等待。在一个系统中,如果阻塞点越少,每个线程处理请求时能减少等待,就能更好的利用CPU,提供吞吐量和性能。
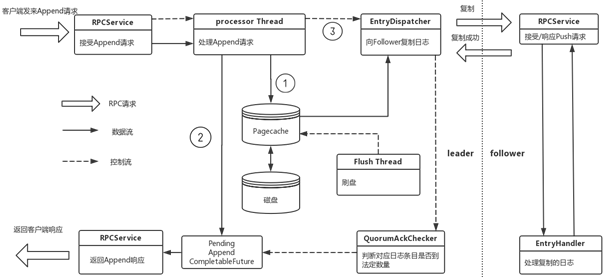
以DLedger处理append请求的整个过程来讲述DLedger异步线程模型。图中粗箭头表示RPC请求,实箭头表示数据流,虚线表示控制流。
首先客户端发送append请求,由DLedger的通信模块处理,当前DLedger默认的通信模块是利用netty实现的,因此netty IO线程会把请求交给业务线程池中的线程进行处理,然后IO线程直接返回,处理下一个请求。业务线程处理append 请求由三个步骤,首先是把append数据写入自己日志中,也就是pagecache中。然后生成Append CompletableFuture,放入一个Pending Map中,由于该日志还没有得到多数的确认所以它是一个判定状态。第三步唤醒EnrtyDispatcher线程,通知该线程去向follower复制日志。三步完成以后业务线程就可以处理下一个Append请求,中间几乎没有任何等待。
另一方面,复制线程EntryDispatch而会向follower复制日志,每个follower都对应一个EntryDispatcher线程,该线程去记录自己对应follower的复制位点,每次位点移动后都会通知QurumAckChecker,这个线程会根据复制位点的请求,判断是否一条日志已经复制到多数节点上,如果已被复制到多数节点,该日志就可以提交,并去完成对应Append CompletableFuture,通知通信模块向客户端返回响应。
2)独立并发复制过程
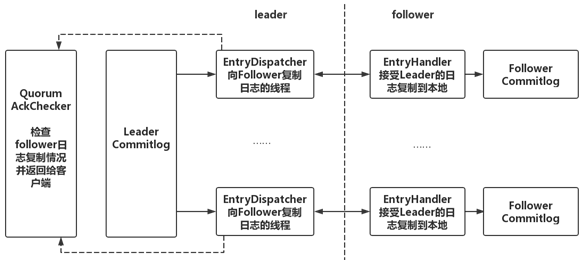
在DLedger中,leader向所有follower发送日志也是完全相互独立和并发的,leader为每个follower分配一个线程去复制日志,并记录相应的复制位点,然后再由一个单独的异步线程根据位点情况监测日志是否被复制到多数节点上,返回给客户端响应
3)日志并行复制
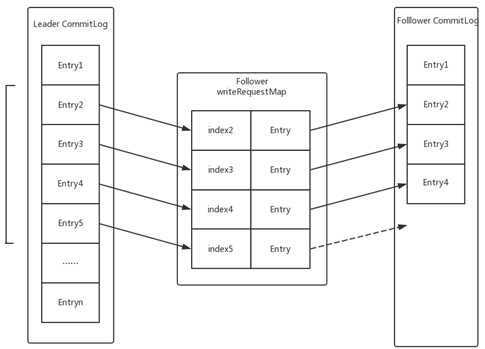
传统的现象复制是leader向follower复制日志,follower确认后下一个日志再复制,也就是leader要等到follower对前一条日志确认后才能复制下一条,这种方式保证了顺序性,不会出错,但是吞吐量很低,延时也比较高,因此DLedger设计并实现日志并行复制的方案,不再需要等待前一个日志复制完成再复制下一个日志,只需要在follower中维护一个按照日志索引排序请求列表,follower线程按照索引顺序串行处理这些复制请求。而对于并行复制后可能出现数据缺失问题,可以通过少量数据重传解决。
2、可靠性优化
1)DLedger对网络分区的优化
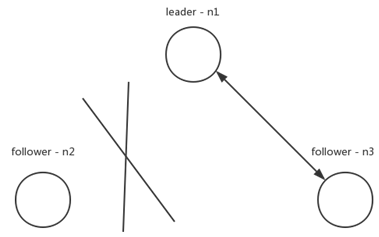
如果出现上图的网络分区,n2与集群中的其他节点发生了网络隔离,按照raft论文实现,n2会一直请求投票,但得不到多数的投票,term一直增大。一旦网络恢复后,n2就会去打断正在正常复制的n1和n3,进行重新选举。为了解决这种情况,DLedger的实现改进了raft协议,请求投票过程分成多个阶段,其中有两个重要阶段:WAIT_TO_REVOTE和WAIT_TO_VOTE_NEXT。WAIT_TO_REVOTE是初始状态,这个状态请求投票时不会曾俊杰term,WAIT_TO_VOTE_NEXT则会在下一轮请求投票开始前增加term。对于图中n2情况,当有效的票数没有达到多数量时,可以将节点状态设置为WAIT_TO_REVOTE,term就不会增加。通过这个方法,提高了DLedger对网络分区的容忍性。
2)DLedger可靠性测试
DLedger还有非常高的容错性。它可以容忍各种各样原因导致节点无法正常工作,比如
- 进程异常崩溃
- 机器节点异常崩溃(机器断电、操作系统崩溃)
- 慢节点(出现fullGC,OOM等)
- 网络故障,各种各样的网络分区
为了验证DLedger对这些故障的容忍性,除了本地对DLedger进行了各种各样的测试,还利用分布式系统验证与故障注入框架Jepsen来监测DLedger存在的问题,并验证系统的可靠性。

若有收获,就点个赞吧
0 人点赞
