在空间上线性可分的两类点,分别向SVM分类的超平面上做投影,这些点在超平面上的投影仍然是线性可分的吗?
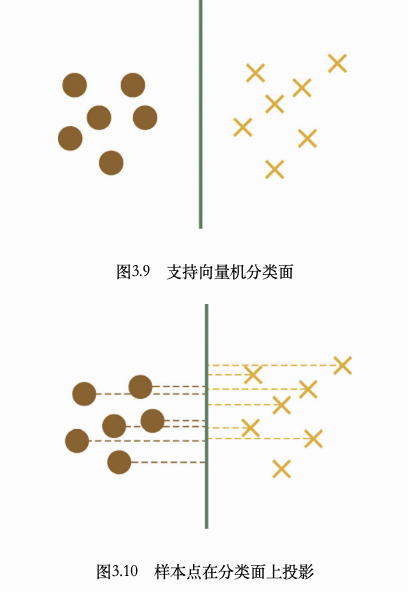
由上图3.10可知,设想二维空间中只有两个样本点,每个点各属于一类的分类任务,此时SVM的分类超平面(直线)就是两个样本点连线的中垂线,两个点在分类面(直线)上的投影会落到这条直线上的同一个点,自然不是线性可分的。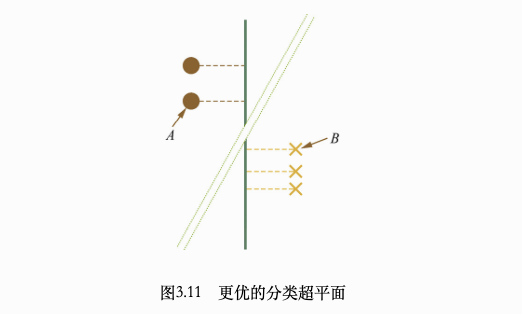
假设存在一个SVM分类超平面使所有支持向量在该超平面上的投影依然线性可分,如图3.11所示。根据简单的初等几何知识不难发现,图中AB两点连线的中垂线所组成的超平面(绿色虚线)是相较于绿色实线超平面更优的解,这与之前假设绿色实线超平面为最优的解相矛盾。考虑最优解对应的绿色虚线,两组点经过投影后,并不是线性可分的。
是否存在一组参数使SVM训练误差为0?

 (1)
(1)
由于不存在两个点在同一位置,因此对于任意的 ,有
,有 。对于任意
。对于任意 ,固定
,固定 ,只保留参数
,只保留参数 。
。 (2)
(2)
将任意 代入(2)
代入(2) (3)
(3) (4)
(4) (5)
(5)
训练误差为0的SVM分类器一定存在吗?
虽然在问题2中我们找到了一组参数 以及使得SVM的训练误差为0,但这组参数不一定是满足SVM条件的一个解。在实际训练一个不加入松弛变量的SVM模型时,是否保证得到的SVM分类器满足训练误差为0呢?
以及使得SVM的训练误差为0,但这组参数不一定是满足SVM条件的一个解。在实际训练一个不加入松弛变量的SVM模型时,是否保证得到的SVM分类器满足训练误差为0呢?
模型中解的限制条件 。我们已经得到了一组参数使得当
。我们已经得到了一组参数使得当 时,
时, ;而当
;而当 时,
时, 。现在需要找到一组参数满足更强的条件,即。
。现在需要找到一组参数满足更强的条件,即。
仍然固定b=0,于是预测公式 ,将
,将 展开,有
展开,有
可以把每个 选择一个很大的值,同时取一个非常小的,使得核映射
选择一个很大的值,同时取一个非常小的,使得核映射 非常小,于是在上式中占据绝对主导位置。因此SVM最优解也满足上述条件,同时一定使模型分类误差为0。
非常小,于是在上式中占据绝对主导位置。因此SVM最优解也满足上述条件,同时一定使模型分类误差为0。
加入松弛变量的SVM的训练误差可以为0吗?
在实际应用中,如果使用SMO算法来训练一个加入松弛变量的线性SVM模型,并且惩罚因子C为任一未知常数,我们是否能得到训练误差为0的模型呢?
松弛变量的SVM模型优化目标函数包含 和
和 ,当我们的参数C选取较小的值时,后一项(正则项)将占据优化的较大比重。这样,一个带有训练误差,但是参数较小的点将成为更优的结果。一个简单的特例是,当C取0时,w也取0即可达到优化目标,但是显然此时我们的训练误差不一定能达到0。
,当我们的参数C选取较小的值时,后一项(正则项)将占据优化的较大比重。这样,一个带有训练误差,但是参数较小的点将成为更优的结果。一个简单的特例是,当C取0时,w也取0即可达到优化目标,但是显然此时我们的训练误差不一定能达到0。

若有收获,就点个赞吧
0 人点赞
