准确率的局限性
准确率是指分类正确的样本占总样本个数的比例。
其中 为被正确分类的样本个数,
为被正确分类的样本个数, 为总样本的个数。
为总样本的个数。
准确率的缺陷,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
精确率与召回率的权衡
精确率是指分类正确的正样本个数占分类器判定为正样本的样本的比例。召回率是指分类正确的正样本个数占真正的正样本个数的比例。
在排序问题中,通常没有一个确定的阈值把得到的结果直接判定为正样本或负样本,而是采用Top N返回结果的Precision值和Recall值来衡量排序模型的性能,即认为模型返回的Top N的结果就是模型判定的正样本,然后计算前N个位置上的准确率Precision@N和前N个位置上的召回率Recall@N。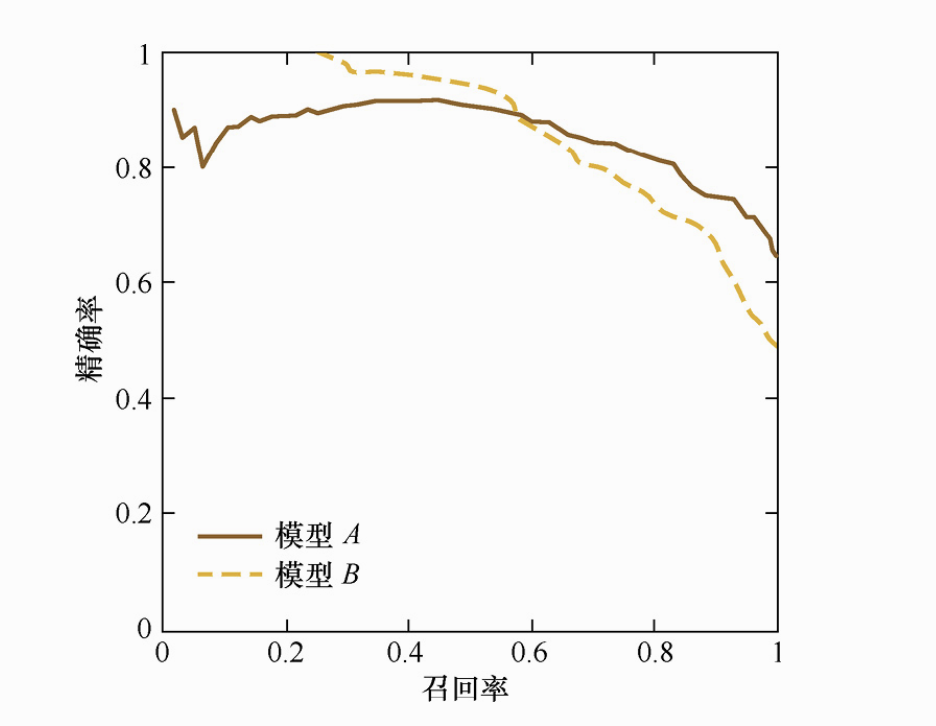
P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应着召回率和精确率。
F1 score和ROC曲线也能综合反映一个排序模型的性能。F1 score是精确率和召回率的调和平均值,它定义为
平方根误差的“意外”
Hulu作为一家流媒体公司,拥有众多的美剧资源,预测每部美剧的流量趋势对于广告投放、用户增长都非常重要。我们希望构建一个回归模型来预测某部美剧的流量趋势,但无论采用哪种回归模型,得到的RMSE指标都非常高。然而事实是,模型在95%的时间区间内的预测误差都小于1%,取得了相当不错的预测结果。那么,造成RMSE指标居高不下的最可能的原因是什么? 
其中, 是第
是第 个样本点的真实值,
个样本点的真实值, 是第个样本点的预测值,
是第个样本点的预测值, 是样本点的个数。
是样本点的个数。
一般情况下,RMSE能够很好地反映回归模型预测值与真实值的偏离程度。但在实际问题中,如果存在个别偏离程度非常大的离群点(Outlier)时,即使离群点数量非常少,也会让RMSE指标变得很差。
解决方案:第一,如果我们认为离群点是“噪声点”的话,就需要在数据预处理的阶段把这些噪声点过滤掉。第二,如果不认为这些离群点是“噪声点”的话,就需要进一步提高模型的预测能力,将离群点产生的机制建模进去。第三,可以找一个更合适的指标来评估该模型。例如平均绝对百分比误差,它定义为
相比RMSE,MAPE相当于把每个点的误差进行率归一话,降低率个别离群点带来的绝对误差的影响。

若有收获,就点个赞吧
0 人点赞
