朴素贝叶斯(Naive Bayesian)是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯原理简单,也很容易实现,多用于文本分类,比如垃圾邮件过滤。朴素贝叶斯可以看做是贝叶斯网络的特殊情况:即该网络中无边,各个节点都是独立的。
朴素贝叶斯朴素在哪里呢? —— 两个假设:
- 一个特征出现的概率与其他特征(条件)独立;
- 每个特征同等重要。
贝叶斯公式如下:
举例说明: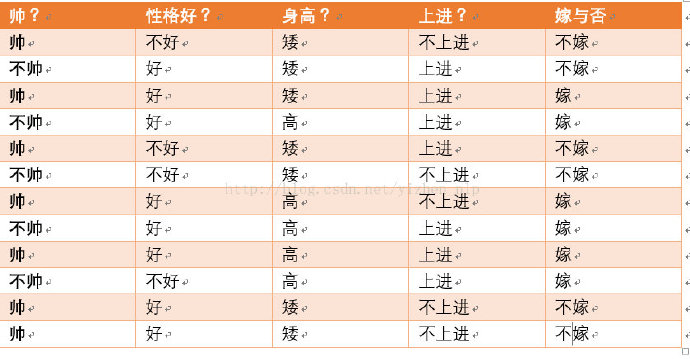
现在有一个男生向女士求婚,女孩考虑嫁不嫁他,男生有四点特征,分别是不帅、性格不好、身高矮、不上进,我们用贝叶斯来判断女生嫁不嫁他。
这是一个典型的分类问题,转化为数学问题就是比较p(嫁|不帅,性格不好,身高矮,不上进)与p(不嫁|帅,性格不好,身高矮,不上进)的概率,看谁大。
这里我们联系到朴素贝叶斯公式: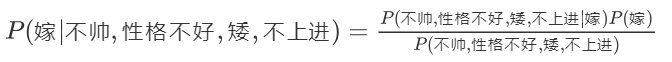

这里我们假设各个特征之间相互独立!!!如果不独立,我们统计的时候就需要在整个特征空间去找,比如统计p(不帅、性格不好、身高矮、不上进|嫁),我们就需要在嫁的条件下,去找四种特征全满足分别是不帅,性格不好,身高矮,不上进的人的个数,这样的话,由于数据的稀疏性,很容易统计到0的情况。 这样是不合适的
朴素贝叶斯优点:
- 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化即可!)
- 分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
朴素贝叶斯缺点:
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
朴素贝叶斯模型(Naive Bayesian Model)的朴素(Naive)的含义是”很简单很天真”地假设样本特征彼此独立. 这个假设现实中基本上不存在, 但特征相关性很小的实际情况还是很多的, 所以这个模型仍然能够工作得很好。

若有收获,就点个赞吧
0 人点赞
