概论
Ensemble learning 通过构建并结合多个学习器来完成学习任务。通俗点讲就是:让机器学习效果更好,单个不行,群殴走起。这样常可获得比单一学习器显著优秀的泛化能力。(集成算法中个体学习器的类型可以是相同的也可以是不同的,如果集成中只包含相同类型的个体学习器,则称为“基学习器”,如果包含不同的学习算法,则称为“组件学习器”或直接称为个体学习器)
根据个体学习器的生成方式,目前主要分为两大类,一种是个体学习器间不存在强依赖关系、可同时生成的并行化方法;另一种是个体学习器间存在强依赖关系、必须串行生成的序列化方法。包括:
- Bagging(训练多个分类器取平均,最典型的代表就是随机森林Random Forest)
- Boosting(从弱学习器开始加强,通过加权来进行训练)
- Stacking(聚合多个分类或回归模型(可以分阶段来做))
Why need Ensemble Learning?
- 弱分类器间存在一定的差异性,这会导致分类的边界不同,也就是说可能存在错误。那么将多个弱分类器合并后,就可以得到更加合理的边界,减少整体的错 误率,实现更好的效果
- 对于数据集过大或者过小,可以分别进行划分和有放回的操作产生不同的数据子集,然后使用数据子集训练不同的分类器,最终再合并成为一个大的分类器
- 如果数据的划分边界过于复杂,使用线性模型很难描述情况,那么可以训练多个模型,然后再进行模型的融合
- 对于多个异构的特征集的时候,很难进行融合,那么可以考虑每个数据集构建 一个分类模型,然后将多个模型融合
Bagging
Bagging是并行式集成学习算法最著名的代表。
算法流程
给定包含m个样本的数据集,我们先随机取出一个样本放入采集样本中,再把该样本放回初始数据集中,使得下次采样时该样本仍有可能被选中,这样,经过m次随机操作,我们得到m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现,由自助采样法可知,初始训练集中约有63.2%的样本出现在采样集中。这样我们可以采样出T个含有m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。(每个子集的样本数量必须和原始样本数量一致。由于每个基学习器只用了训练集中63.2%的样本,剩下的36.8%可以作为验证集,对泛化能力进行“包外估计”,另外,它还有很多用途,比如当基学习器是决策树时,可以辅助剪枝;当基学习器是神经网络时,可使用辅助早期停止以减小过拟合风险)
在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法(如果预测时出现两个类票数相同,可以随机选择一个,或者进一步考察学习器的置信度来确定最终胜者),对回归任务采用简单平均法。从偏差-方差角度分析,Bagging主要关注降低方差。
随机森林(Random Forest,简称RF)
RF是Bagging的扩展变形。
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起
RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择,通俗点讲就是RF的决策树在每个结点选择最优特征(假设样本中一共有d个特征)进行划分时,先从所有特征中随机选择包含k个特征的子集,再在这个子集中进行最优特征选择,这样样本的特征数就减少了;如果k=d,那么基决策树学习器和传统的决策树相同,一般情况下,推荐值k=log2 d
随机森林的优势:
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要
- 容易做成并行化方法,速度比较快
-
Boosting
Boosting是一簇将弱学习器提升为强学习器的算法。工作机制:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续收到更多的关注,然后基于调整后的样本分布来训练下一个基学习器,如此反复进行,直到基学习器数目到达要求,最后将所有基学习器进行加权结合。
Boosting簇算法的代表有:Adboost、GBDT、XgboostAdboost
算法流程:
假设训练数据集具有均匀的均值分布,即每个训练样本在基本分类器的权重相同,这样在原始数据上学习基本分类器G1(x)
- Adboost反复学习基本分类器,在每一轮学习m=1,2,3,4….M执行下列操作:
- a.使用当前分布
 加权的训练数据集,学习基本分类器
加权的训练数据集,学习基本分类器 
- b.计算基本分类器

 在加权训练数据集上的分类误差率
在加权训练数据集上的分类误差率 
- c.计算基本分类器

 的系数
的系数 ,
, 表示
表示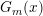 在最终分类器中的重要性。
在最终分类器中的重要性。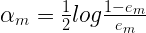 ,由此式可知,当
,由此式可知,当 小于等于0.5时,
小于等于0.5时, 大于等于0,并且
大于等于0,并且 随着
随着 的减小而增大,所以,分类误差率越小的基本分类器在最终分类器的权重越大。
的减小而增大,所以,分类误差率越小的基本分类器在最终分类器的权重越大。 - d.跟新训练数据的权重为下一轮做准备
栗子
训练数据如下
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
解:
初始化权重分布

对m=1,
- a.在权重分布为
 的训练数据上,阈值取2.5时分类误差率最低,故基本分类器为
的训练数据上,阈值取2.5时分类误差率最低,故基本分类器为


- b.
 在训练数据集上的误差率
在训练数据集上的误差率

- c.计算
 的权重系数
的权重系数


- d.更新训练数据的权值分布





分类器 在训练数据集上有3个误分类点。
在训练数据集上有3个误分类点。
对m=2,
- a.在权重分布为
 的训练数据上,阈值为8.5时分类误差率最低,基本分类器为
的训练数据上,阈值为8.5时分类误差率最低,基本分类器为


- b.
 在训练数据集上的误差率
在训练数据集上的误差率
- c.计算


- d.更新训练数据权重分布:




分类器sign[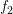 (x)]在训练数据集上有3个误分类点。
(x)]在训练数据集上有3个误分类点。
对m=3,
- a.在权重分布为
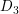 的训练数据上,阈值为5.5时分类误差率最低,基本分类器为
的训练数据上,阈值为5.5时分类误差率最低,基本分类器为


- b.
 在训练样本集上的误差率
在训练样本集上的误差率
- c.计算
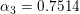

- d.更新训练数据的权重分布:


于是

分类器 在训练数据集上误分类点个数为0,
在训练数据集上误分类点个数为0,
因此,最终分类器为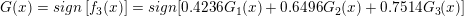
总结
在训练过程中,每个新的模型都会基于前一个模型的表现结果进行调整,这也就是为什么AdaBoost是自适应(adaptive)的原因,即AdaBoost可以自动适应每个基学习器的准确率。AdaBoost算法可以认为是一种模型为加法模型、损失函数为指数函数、学习算法为前向分步算法的而分类学习方法。
AdaBoost的优点:
- 可以处理连续值和离散值
- 模型的鲁棒性比较强
- 解释性强,结构简单
AdaBoost的缺点:










若有收获,就点个赞吧
0 人点赞
