信息论
1、信息熵
在决策树中,熵是非常非常重要的,一件事发生的概率越小,我们说他蕴含的信息量最大,比如说:当我们听到一个男人怀孕了,哈哈哈哈哈,这信息量很大了,所以用下面的公式衡量信息量:

信息熵就是所有可能发生的事件的信息量的期望

以此来表达Y事件的不确定度。
2、条件熵
条件熵:表示在X给定的条件下,Y的条件概率分布的熵对X的数学期望。

条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。注意一下,条件熵中X也是一个变量,意思是在一个变量X的条件下(变量X的每个值都会取到),另一个变量Y的熵对X的期望。
举个小栗子:
当一个妹子决定向一个男生搭讪的时候,取决于俩个标准:颜值和身高
| 颜值 | 身高 | 追不追 | |
|---|---|---|---|
| 1 | 帅 | 高 | 追 |
| 2 | 帅 | 不高 | 追 |
| 3 | 不帅 | 高 | 不追 |
上表中随机变量Y={追,不追},P(Y=追)=2/3,P(Y=不追)=1/3,得到Y的熵
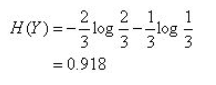
这里还有一个特征变量X,X={高,不高}。当X=高时,追的个数为1,占1/2,不追的个数为1,占1/2,此时:
同理:

(注意:我们一般约定,当p=0时,plogp=0)

3、信息增益
信息增益: 度量以某特征划分数据集前后的信息熵的差值。当我们用另一个变量X对原变量Y分类后,原变量Y的不确定性就会减小了(即熵值减小)。而熵就是不确定性,不确定程度减少了多少其实就是信息增益。这就是信息增益的由来,所以信息增益定义如下:

此外,信息论中还有互信息、交叉熵等概念,它们与本算法关系不大,这里不展开。
在决策树算法中,最重要的就是划分属性的选择,即我们选择哪一个属性来进行划分。三种划分属性的主要算法是:ID3、C4.5以及CART。
| 算法 | 划分标准 |
|---|---|
| ID3 | 信息增益 |
| C4.5 | 信息增益率 |
| CART | 基尼系数 |
决策树简介
决策树是一个分而治之的递归过程。
- 开始,构建根节点,将所有训练数据都放在根节点。
- 然后,选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
- 如果子集未分类完毕,则在子集中选择一个最优特征,继续进行划分,直到所有训练数据子集都被正确分类或没有合适的特征为止。
决策树三要素
- 特征选择: 从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
- 决策树生成:根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。
- 决策树的修剪:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
1. 算法特征的选择
有三种方法进行特征选择:ID3: 信息增益,C4.5: 信息增益比,CART: 基尼系数1. ID3
ID3算法所采用的度量标准就是我们前面所提到的“信息增益”。当属性a的信息增益最大时,则意味着用a属性划分,其所获得的“纯度”提升最大。我们所要做的,就是找到信息增益最大的属性。由于前面已经强调了信息增益的概念,这里不再赘述。缺点:信息增益对分支较多的属性有所偏好,因此有人提出采用信息增益比来划分特征。2、C4.5
实际上,信息增益准则对于可取值数目较多的属性会有所偏好,为了减少这种偏好可能带来的不利影响,C4.5决策树算法不直接使用信息增益,而是使用“信息增益率”来选择最优划分属性,信息增益率定义为:
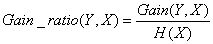
其中,分子为信息增益,分母为属性X的熵。
需要注意的是,增益率准则对可取值数目较少的属性有所偏好。
所以一般这样选取划分属性:先从候选属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。3、 CART
ID3算法和C4.5算法主要存在三个问题:
(1)每次选取最佳特征来分割数据,并按照该特征的所有取值来进行划分。也就是说,如果一个特征有4种取值,那么数据就将被切成4份,一旦特征被切分后,该特征就不会再起作用,有观点认为这种切分方式过于迅速。
(2)它们不能处理连续型特征。只有事先将连续型特征转换为离散型,才能在上述算法中使用。
(3)会产生过拟合问题。
为了解决上述(1)、(2)问题,产生了CART算法,它主要的衡量指标是基尼系数。为了解决问题(3),主要采用剪枝技术和随机森林算法,这部分内容,下一次再详细讲述。
上述就是决策树算法的原理部分,下面展示完整代码和注释。代码中主要采用的是ID3算法
import picklefrom math import log#计算信息熵def CalcShannonEnt(dataset):num_entries=len(dataset)label_counts={}for feature_vec in dataset:current_label=feature_vec[-1]if current_label not in label_counts.keys():label_counts[current_label]=0else:label_counts[current_label]+=1shannonEnt=0for key in label_counts.keys():pro_y=float(label_counts[key]/num_entries)shannonEnt-=log(pro_y,2)return shannonEnt#根据特征划分数据集def SplitDataset(dataset,axis,values):retdataset=[]for feature_vec in dataset:if feature_vec[axis]==values:reduced_feature_vec=feature_vec[:axis]reduced_feature_vec.extend(feature_vec[axis+1:])retdataset.append(reduced_feature_vec)return retdataset#根据信息增益,选取最好的特征def chooseBestFeatureSplit(dataset):num_feature=len(dataset[0])-1base_entropy=CalcShannonEnt(dataset)best_infogain=0.0best_feature=-1for i in range(num_feature):feature_list=[example[i] for example in dataset]unique_vals=set(feature_list)new_entropy=0for value in unique_vals:subdataset=SplitDataset(dataset,i,value)prob=len(subdataset)/float(len(dataset))new_entropy+=prob*log(subdataset)infogain=base_infogain-new_entropyif (infogain>best_infogain):best_infogain=infogainbest_feature=ireturn best_feature#多数表决器def MaujorityCnt(classlist):classcount={}for vote in classlist:if vote not in clsscount.keys():classcount[vote]=0else:classcount[vote]+=1sorted_classcount=sorted(classcount.items(),key=lambda x:x[1],reverse=True)return sorted_classcount[0][0]#创建决策树def CreatTree(dataset,labels):classlist=[example[-1] for example in dataset]if classlist.count(classlist[0])==len(classlist):return classlist[0]if len(dataset[0])==1:return MaujorityCnt(classlist)best_feature=chooseBestFeatureSplit(dataset)best_feature_label=labels[best_feature]my_tree={best_feature_label:{}}del(labels[best_feature])feature_values=[example[best_feature] for example in dataset]unique_vals=set(feature_values)for value in unique_vals:sublabels=labels[:]my_tree[best_feature_label][value]=CreatTree(SplitDataset(dataset,best_feature,value),sublabels)return my_tree#使用决策树进行分类def classify(inputtree,feature_labels,test_vec):first_str=lsit(inputtree.keys())[0]seconde_dict=inputtree[first_str]feature_index=feature_labels.index(first_str)for key in seconde_dict.keys():if test_vec[feature_index]==key:if type(seconde_dict[key]).__name__=="dict":classlabel=classify(seconde_dict[key],feature_labels,test_vec)else:classlabel=seconde_dict[key]return classlabel#决策树在磁盘的存储和导入def StoreTree(InputTree,filename):file_write=open(filename,'w')pickle.dump(InputTree,file_write)fw.close()def GrabTree(filename):file_read=open(filename,'r')return pickle.load(file_read)

若有收获,就点个赞吧
0 人点赞
