- Risc-V 下的页表
- 虚拟内存翻译
- 内核中对物理内存的分配和管理。
1. 页表
操作系统初始化完毕后(主要是启动了分页机制后),所有的地址都会认为是虚拟地址,当我们获取地址中的内容时,CPU 会将该地址发送给 MMU 单元进行地址翻译,从页表中查询对应的物理地址。1.1 Sv39 RISC-V
xv6 为 64 位的操作系统,在其采用的 Sv39 RISC-V 机制下,该操作系统的虚拟地址位长只有 39 位(也可选择为 48 位),剩余的 25 位为扩展位,默认情况下不使用。其物理地址由 44 位的物理页号 PPN 和 12 位的页内偏移组成(4kb)。1.2 虚拟地址翻译
首先需要在satp寄存器中设置MODE开启分页,并且将页目录载入该寄存器PPN字段,该寄存器结构如下:
MODE字段取值范围如下,xv6 中该值为 8,即开启 39 bit 虚拟地址: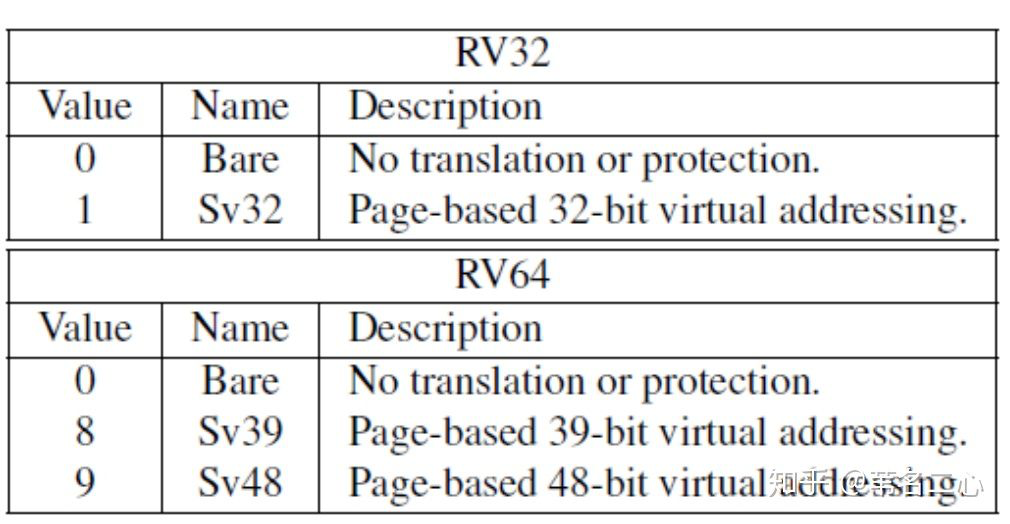
加载完页表开启分页后,其虚拟地址翻译流程大致如下: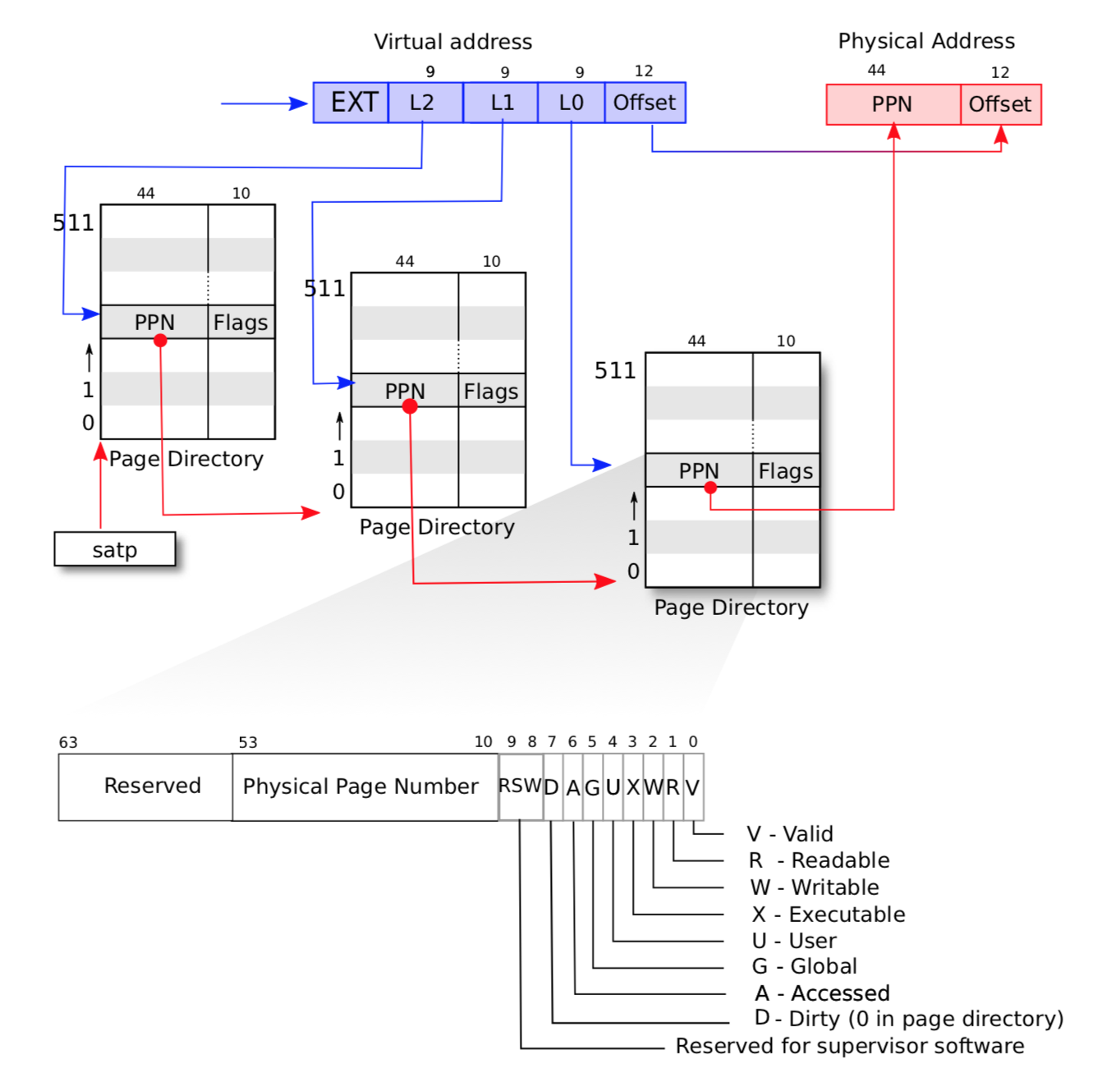
可以看到分为 3 级页表(假如MODE设置为 9,开启 48bit 的虚拟地址,则为 4 级页表,39 ~ 47 位为 4 级页表的索引位置),首先忽略低 12 位的物理地址偏移,接下来的 27 位拆分为 3 组,每组 9 位,每一组的值依次对应在每一级页表中的索引位置。
假如以伪代码的形式,模拟翻译流程,不考虑页目录未创建的情况,流程大致如下: ```c uint64 vaddr; // 要翻译的虚拟地址 pagetable_t pagetable = get_pagetable(); // 从 stap 中获取根页表
// 获取次级页表 int L2 = get_va_L2_value(va); // 获取 27 位中,高 9 位的值 pagetable = pagetable[L2]; // 根据 L2 索引根页表,获取次级页表
// 获取最终页表 int L1 = get_va_L1_value(va); // 获取 27 位中,中 9 位的值 pagetable = pagetable[L1]; // 获取最终页表
// 此时已经获取到最后一个页表,接下来获取目标页 int L0 = get_va_L0_value(va); // 获取 27 位中,低 9 位的值 pte_t pte = &pagetable[L0]; // 将获取到的目标页右移 10 位,去掉属性位 // 然后左移动 12 位,这部分是实际物理地址的偏移,需要赋值为 va 的低 12 位偏移 uint64 ppn = pte >> 10 << 12; // 加上虚拟地址低 12 位偏移,最终得到物理地址 uint64 paddr= ppn + (vaddr & 0x1ff);
虚拟地址翻译实质上就是 MMU 根据传入的虚拟地址,将其按位拆分,分别找到其在多级页表中的位置,最后找到具体的页表项。<a name="IUEOc"></a>## 2. 内存管理xv6 内核的内存空间如下所示:<br /><br />最大可以支持 `2^56-1` 的物理内存。xv6 的内核内存使用 **直接映射** 的方式,也就是 **虚拟地址 翻译后的 物理地址 与 虚拟地址相同**。<a name="SzMc9"></a>### 2.1 内存初始化内存的访问主要通过页表,因此内核的内存初始化主要就是对各部分的内存映射到页表当中。其逻辑在 `kvmmake` 中。```c// Make a direct-map page table for the kernel.pagetable_tkvmmake(void){pagetable_t kpgtbl;kpgtbl = (pagetable_t) kalloc();memset(kpgtbl, 0, PGSIZE);// uart registerskvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);// virtio mmio disk interfacekvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);// PLICkvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);// map kernel text executable and read-only.kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);// map kernel data and the physical RAM we'll make use of.kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);// map the trampoline for trap entry/exit to// the highest virtual address in the kernel.kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);// map kernel stacksproc_mapstacks(kpgtbl);return kpgtbl;}// Initialize the one kernel_pagetablevoidkvminit(void){kernel_pagetable = kvmmake();}
- 分配一页,作为内核专用页表
- 映射专用的内存(设备寄存器)
- 映射内核的代码段
- 映射内核的数据段
- 为进程分配内核栈(xv6 会预先创建一个进程数组,分配进程的时候从进程数组中获取空闲的进程结构,此处先为每个进程创建内核栈)
2.2 内存映射流程
初始化内存的流程基本都是在映射内存到页表,因此简单整理下 xv6 中是如何映射页表与内存页的。其核心接口为 kvmmap
// add a mapping to the kernel page table.
// only used when booting.
// does not flush TLB or enable paging.
void
kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kpgtbl, va, sz, pa, perm) != 0)
panic("kvmmap");
}
// Create PTEs for virtual addresses starting at va that refer to
// physical addresses starting at pa. va and size might not
// be page-aligned. Returns 0 on success, -1 if walk() couldn't
// allocate a needed page-table page.
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if(size == 0)
panic("mappages: size");
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for(;;){
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
kvmmap 主要调用 mappages 进行页表映射工作,mappages 的逻辑如下:
- 将虚拟地址向下取整,4KB 对齐,然后遍历 [va, va+size) 这块区域,每次跨度为 PGSIZE,即 4KB
- 每次遍历,通过
walk获取虚拟地址在页表中的 PTE,如下所示:
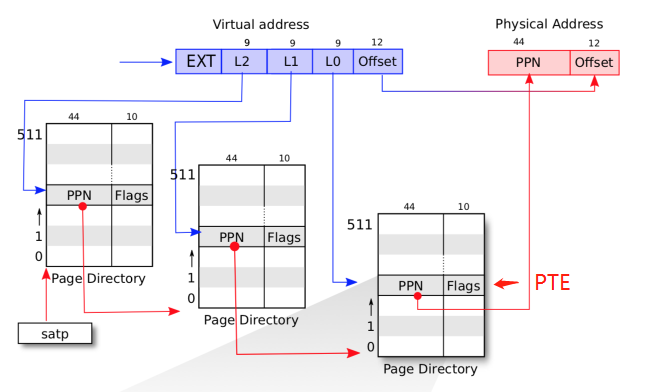
- 设置 PTE,即获取物理地址的高 44 位,加上对应的读写权限
这里只需要保存物理地址的高 44 位,因为 xv6 最高只支持 2^56 -1 的内存空间。
walk 函数其实就是模拟地址翻译的过程。
// shift a physical address to the right place for a PTE.
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
#define PTE2PA(pte) (((pte) >> 10) << 12)
#define PTE_FLAGS(pte) ((pte) & 0x3FF)
// extract the three 9-bit page table indices from a virtual address.
#define PXMASK 0x1FF // 9 bits
#define PXSHIFT(level) (PGSHIFT+(9*(level)))
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
pte_t* walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
2.3 内存管理器
xv6 的内存管理器非常简单,只有一个单向链表结构还有一个锁。
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
每个链表元素为一页内存区域的指针。其初始化方式如下:
void kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
void freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
简单来说就是通过 freerange 将一块区域的内存划分成多个页组成的链表,kfree 将页指针存到链表中,内存区域的大小为红色箭头所指区域: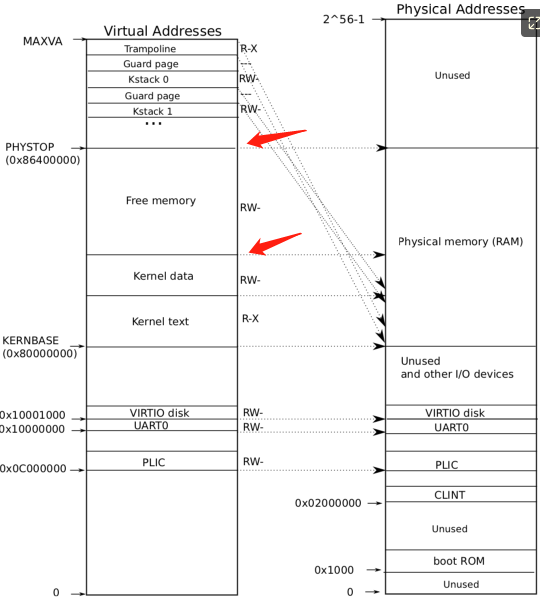
2.4 分配内存
内核分配内存的接口为 void* kalloc(void),每次返回一个页大小的内存空间。
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
2.5 释放内存
释放内存的接口为 void kfree(void *pa) ,逻辑较为简单,释放指定页内存
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}

若有收获,就点个赞吧
0 人点赞
