- xv6 中锁的实现(Spin lock && Sleep lock)
- 锁的特性与死锁
-
1. Lock
1.1 Spin lock
1.1.1 acquire
Spin lock 的加锁操作如下:
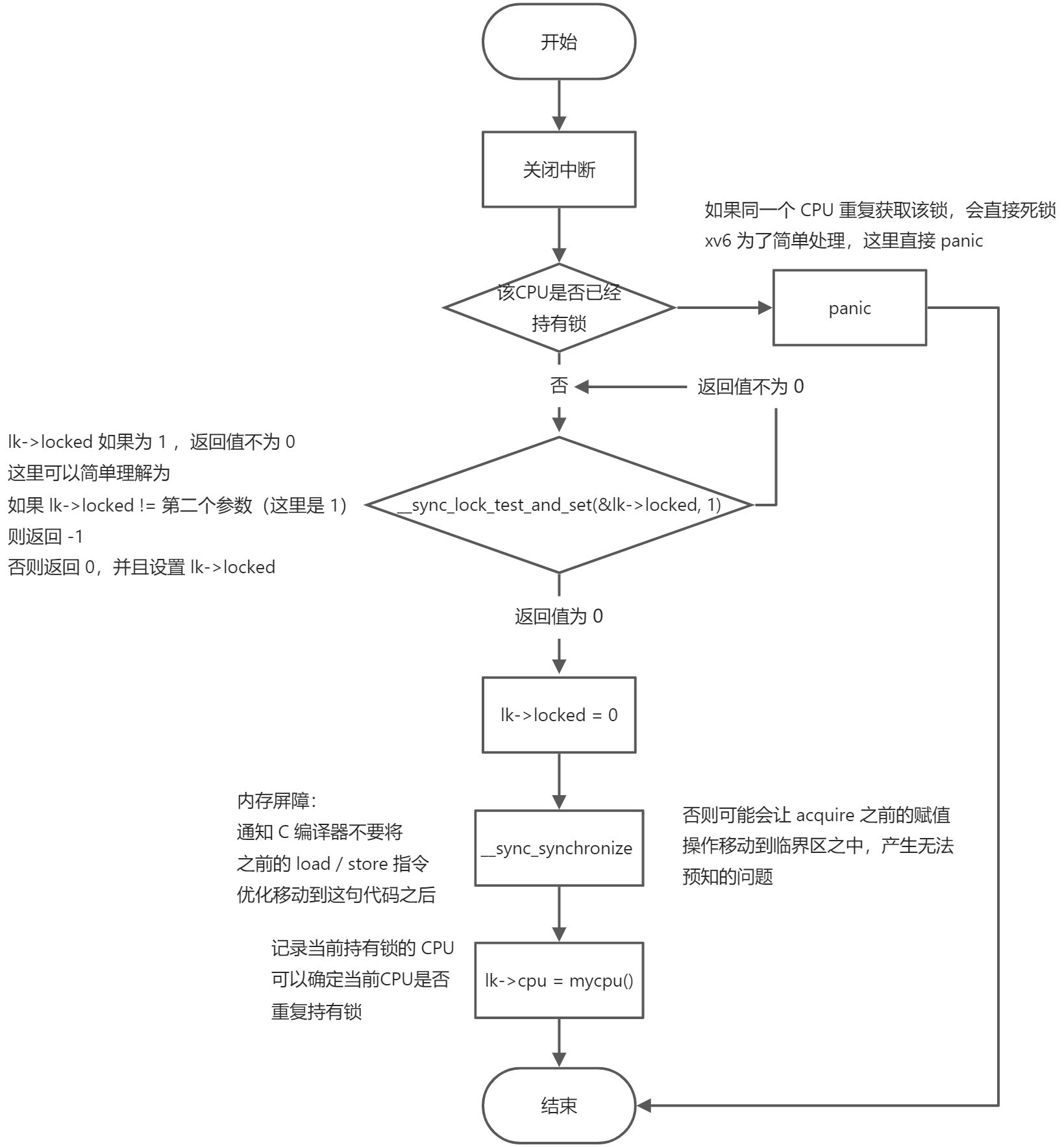
// Acquire the lock.// Loops (spins) until the lock is acquired.voidacquire(struct spinlock *lk){push_off(); // disable interrupts to avoid deadlock.if(holding(lk))panic("acquire");// On RISC-V, sync_lock_test_and_set turns into an atomic swap:// a5 = 1// s1 = &lk->locked// amoswap.w.aq a5, a5, (s1)while(__sync_lock_test_and_set(&lk->locked, 1) != 0);// Tell the C compiler and the processor to not move loads or stores// past this point, to ensure that the critical section's memory// references happen strictly after the lock is acquired.// On RISC-V, this emits a fence instruction.__sync_synchronize();// Record info about lock acquisition for holding() and debugging.lk->cpu = mycpu();}
锁的定义如下:
// Mutual exclusion lock.struct spinlock {uint locked; // Is the lock held?// For debugging:char *name; // Name of lock.struct cpu *cpu; // The cpu holding the lock.};
1.1.2 release
释放锁的操作如下:
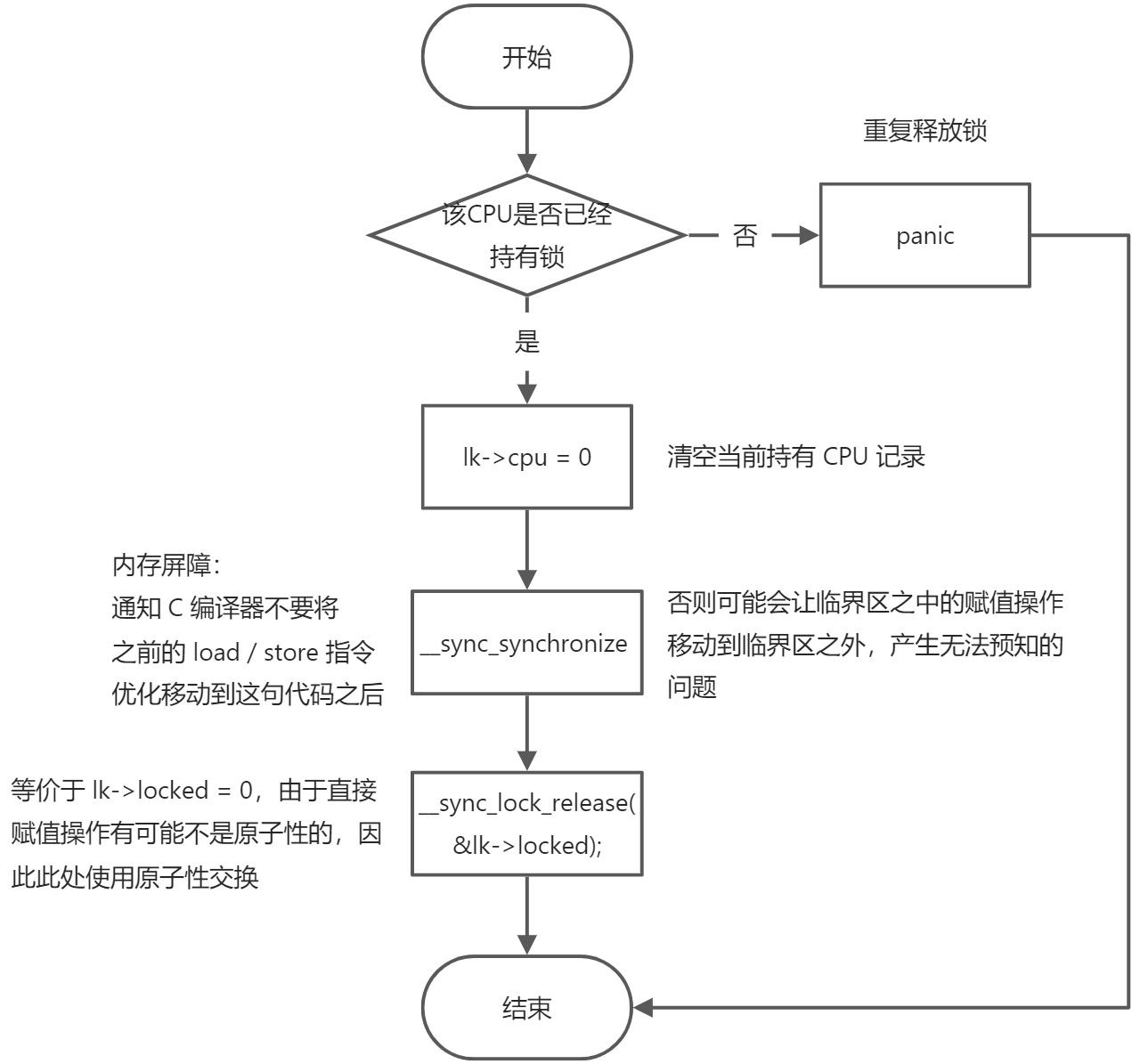
// Release the lock.voidrelease(struct spinlock *lk){if(!holding(lk))panic("release");lk->cpu = 0;// Tell the C compiler and the CPU to not move loads or stores// past this point, to ensure that all the stores in the critical// section are visible to other CPUs before the lock is released,// and that loads in the critical section occur strictly before// the lock is released.// On RISC-V, this emits a fence instruction.__sync_synchronize();// Release the lock, equivalent to lk->locked = 0.// This code doesn't use a C assignment, since the C standard// implies that an assignment might be implemented with// multiple store instructions.// On RISC-V, sync_lock_release turns into an atomic swap:// s1 = &lk->locked// amoswap.w zero, zero, (s1)__sync_lock_release(&lk->locked);pop_off();}
1.2 Sleep lock
1.2.1 sleep
Sleep lock 的操作是在 Spin lock 的基础上做了一些修改,其加锁操作如下:
// Atomically release lock and sleep on chan.// Reacquires lock when awakened.voidsleep(void *chan, struct spinlock *lk){struct proc *p = myproc();// Must acquire p->lock in order to// change p->state and then call sched.// Once we hold p->lock, we can be// guaranteed that we won't miss any wakeup// (wakeup locks p->lock),// so it's okay to release lk.acquire(&p->lock); //DOC: sleeplock1release(lk);// Go to sleep.p->chan = chan;p->state = SLEEPING;sched();// Tidy up.p->chan = 0;// Reacquire original lock.release(&p->lock);acquire(lk);}
相比而言,Sleep 其实就是将 Spinlock 的自旋操作替换成了通过
**Sched**让出当前线程 CPU,这样可以避免 CPU 长期空转。1.2.2 lost wakeup 问题
sleep 的声明为
void sleep(void* chan, struct spinlock *lk),chan的作用是,后面执行wakeup的时候,需要判断wakeup哪些进程,而lk的作用是避免 lost wakeup。假设有如下情况: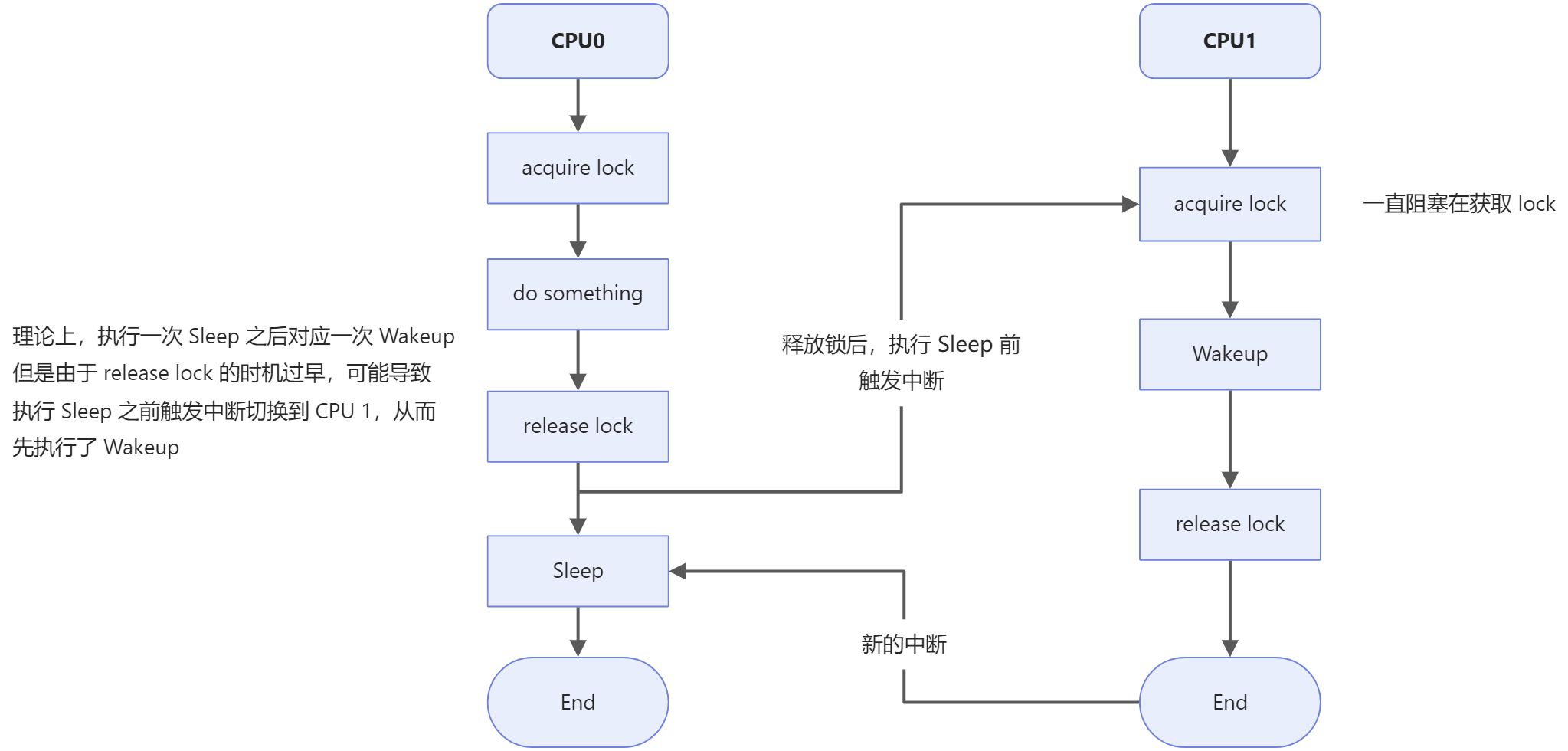
因此需要将对应的 lock 放到 sleep 接口中,先获取进程的锁,再 release lock,由于wakeup执行的时候也需要先获取进程锁,这样就可以避免 lost wakeup 问题。1.2.3 wakeup
wakeup 的操作如下:
// Wake up all processes sleeping on chan.// Must be called without any p->lock.voidwakeup(void *chan){struct proc *p;for(p = proc; p < &proc[NPROC]; p++) {if(p != myproc()){acquire(&p->lock);if(p->state == SLEEPING && p->chan == chan) {p->state = RUNNABLE;}release(&p->lock);}}}
wakeup 的操作比较简单,就是遍历当前进程列表,将
SLEEPING状态且chan相同的进程状态标记为RUNNABLE,由于 xv6 每次时钟中断都会触发进程调度,因此RUNNABLE的进程后续会被重新调度到 CPU 上。1.3 Sleep lock 升级版
相对于 1.2 Sleep lock ,xv6 对其 sleep 进行了一层封装,增加了
struct sleeplock结构,并且加锁也只需sleeplock结构体参数,不需要再传入另一个锁,使用感受与spinlock的acquire一致。// Long-term locks for processesstruct sleeplock {uint locked; // Is the lock held?struct spinlock lk; // spinlock protecting this sleep lock// For debugging:char *name; // Name of lock.int pid; // Process holding lock};
1.3.1 acquiresleep
voidacquiresleep(struct sleeplock *lk){acquire(&lk->lk);while (lk->locked) {sleep(lk, &lk->lk);}lk->locked = 1;lk->pid = myproc()->pid;release(&lk->lk);}
可以看出来,其本质上就是在
struct sleeplock中多加了一个锁,利用该锁 + 进程的锁 来避免: 申请新的锁,简化接口
-
1.3.2 releasesleep
voidreleasesleep(struct sleeplock *lk){acquire(&lk->lk);lk->locked = 0;lk->pid = 0;wakeup(lk);release(&lk->lk);}
2. 锁的特性与死锁
2.1 特性
锁可以避免丢失更新。如果你回想我们之前在 kalloc.c 中的例子,丢失更新是指我们丢失了对于某个内存 page 在 kfree 函数中的更新。如果没有锁,在出现 race condition 的时候,内存 page 不会被加到 freelist 中。但是加上锁之后,我们就不会丢失这里的更新。
- 锁可以打包多个操作,使它们具有原子性。我们之前介绍了加锁解锁之间的区域是 critical section,在 critical section 的所有操作会都会作为一个原子操作执行。
锁可以维护共享数据结构的不变性。共享数据结构如果不被任何进程修改的话是会保持不变的。如果某个进程 acquire 了锁并且做了一些更新操作,共享数据的不变性暂时会被破坏,但是在 release 锁之后,数据的不变性又恢复了。你们可以回想一下之前在 kfree 函数中的 freelist 数据,所有的 free page 都在一个单链表上。但是在 kfree 函数中,这个单链表的 head 节点会更新。freelist 并不太复杂,对于一些更复杂的数据结构可能会更好的帮助你理解锁的作用。
2.2 死锁
一个死锁的最简单的场景就是:首先 acquire 一个锁,然后进入到 critical section;在 critical section 中,再 acquire 同一个锁;第二个 acquire 必须要等到第一个 acquire 状态被 release 了才能继续执行,但是不继续执行的话又走不到第一个 release,所以程序就一直卡在这了。这就是一个死锁。
假设现在我们有两个CPU,一个是CPU1,另一个是CPU2。CPU1执行 rename 将文件 d1/x 移到 d2/y,CPU2执行rename将文件d2/a移到d1/b。这里CPU1将文件从d1移到d2,CPU2正好相反将文件从d2移到d1。我们假设我们按照参数的顺序来acquire锁,那么CPU1会先获取d1的锁,如果程序是真正的并行运行,CPU2同时也会获取d2的锁。之后CPU1需要获取d2的锁,这里不能成功,因为CPU2现在持有锁,所以CPU1会停在这个位置等待d2的锁释放。而另一个CPU2,接下来会获取d1的锁,它也不能成功,因为CPU1现在持有锁。这也是死锁的一个例子,有时候这种场景也被称为deadly embrace。这里的死锁就没那么容易探测了。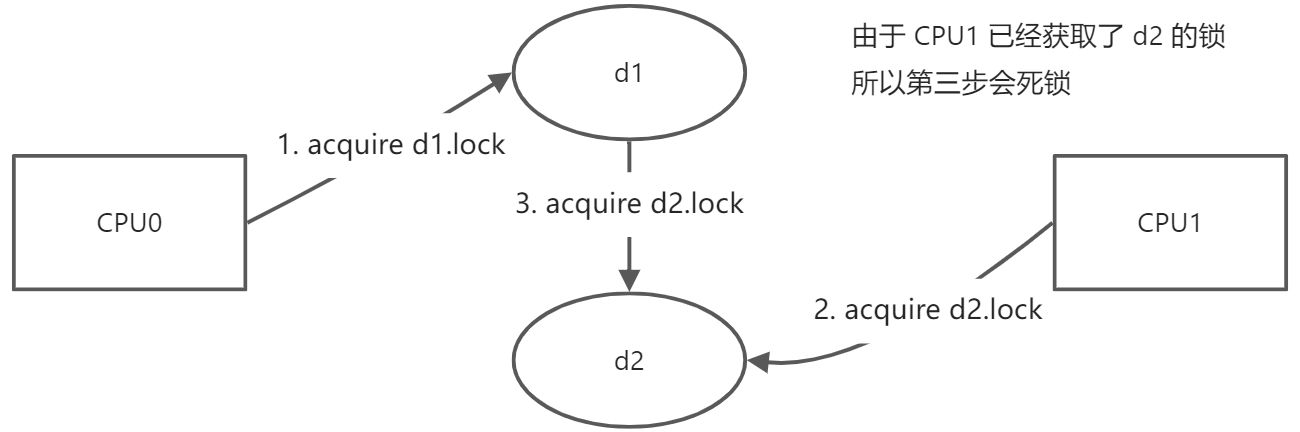
这里的解决方案是,如果你有多个锁,你需要对锁进行排序,所有的操作都必须以相同的顺序获取锁。比如这里 d1 和 d2 的 rename 操作,总是先获取 d1 (按目录顺序)的锁,就能够避免死锁。3. 锁的性能
基本上来说,如果你想获得更高的性能,你需要拆分数据结构和锁。如果你只有一个big kernel lock,那么操作系统只能被一个CPU运行。如果你想要性能随着CPU的数量增加而增加,你需要将数据结构和锁进行拆分。
那怎么拆分呢?通常不会很简单,有的时候还有些困难。比如说,你是否应该为每个目录关联不同的锁?你是否应该为每个inode关联不同的锁?你是否应该为每个进程关联不同的锁?或者是否有更好的方式来拆分数据结构呢?如果你重新设计了加锁的规则,你需要确保不破坏内核一直尝试维护的数据不变性。
通常来说,开发的流程是:先以coarse-grained lock(注,也就是大锁)开始。
- 再对程序进行测试,来看一下程序是否能使用多核。
- 如果可以的话,那么工作就结束了,你对于锁的设计足够好了;如果不可以的话,那意味着锁存在竞争,多个进程会尝试获取同一个锁,因此它们将会序列化的执行,性能也上不去,之后你就需要重构程序。
在这个流程中,测试的过程比较重要。有可能模块使用了coarse-grained lock,但是它并没有经常被并行的调用,那么其实就没有必要重构程序,因为重构程序设计到大量的工作,并且也会使得代码变得复杂。所以如果不是必要的话,还是不要进行重构。
4. 总结
总体来说,xv6 实现了两种锁:
- 自旋锁 spin lock
- 睡眠锁 sleep lock
自旋锁基于原子性的 CAS(compare and swap) 操作实现的,再加上内存屏障保证指令可靠(不会被重排到临界区之内 or 之外),而睡眠锁是在自旋锁的基础上,将原先 一直循环等待的操作 替换成 通过 sched 让出当前 CPU 时间,调度其他进程,这对一些耗时 IO 操作来说更能节约性能。
锁本身在提供了防止 race condition 的同时,也带来了一定性能负担,需要根据锁的使用频率,锁的粒度,再判断是否需要对锁进行拆分提升性能。

若有收获,就点个赞吧
0 人点赞
