- 如何创建第一个进程
- 进程是如何调度的
- 创建进程操作是在内核态进行的,进程执行时是在用户态,如何进行切换
-
1. 创建进程
xv6 中,创建第一个用户进程的入口为
userinit,其逻辑如下:// Set up first user process.voiduserinit(void){struct proc *p;p = allocproc();initproc = p;// allocate one user page and copy init's instructions// and data into it.uvminit(p->pagetable, initcode, sizeof(initcode));p->sz = PGSIZE;// prepare for the very first "return" from kernel to user.p->trapframe->epc = 0; // user program counterp->trapframe->sp = PGSIZE; // user stack pointersafestrcpy(p->name, "initcode", sizeof(p->name));p->cwd = namei("/");p->state = RUNNABLE;release(&p->lock);}
分为如下几步:
分配一个
struct proc结构- 初始化用户页表
- 设置
epc寄存器,当调度该进程的时候,会从该寄存器存放的指令地址开始执行 - 设置用户栈
xv6 的进程结构 struct proc 如下:
// Per-process statestruct proc {struct spinlock lock;// p->lock must be held when using these:enum procstate state; // Process statevoid *chan; // If non-zero, sleeping on chanint killed; // If non-zero, have been killedint xstate; // Exit status to be returned to parent's waitint pid; // Process ID// wait_lock must be held when using this:struct proc *parent; // Parent process// these are private to the process, so p->lock need not be held.uint64 kstack; // Virtual address of kernel stackuint64 sz; // Size of process memory (bytes)pagetable_t pagetable; // User page tablestruct trapframe *trapframe; // data page for trampoline.Sstruct context context; // swtch() here to run processstruct file *ofile[NOFILE]; // Open filesstruct inode *cwd; // Current directorychar name[16]; // Process name (debugging)};
1.1 分配 struct proc
xv6 中进程结构统一存放在 struct proc proc[NPROC] , NPROC 定义为 64 ,表明最多支持同时运行 64 个进程。
这一步主要在 proc 数组中找到空闲的 struct proc 并且对其进行初始化。
初始化中比较需要关注的是
- 分配
trapframe,用于该进程在 用户态 和 内核态 中断时保存上下文 - 分配页表
初始化
ra寄存器与sp寄存器ra寄存器存放着指令地址,主要用于执行函数结束时,ret指令执行后要跳转到的指令位置sp寄存器为栈寄存器,这里进程默认分配PGSIZE大小的用户栈 ```c static struct proc allocproc(void) { struct proc p;
for(p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if(p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
} } return 0;
found: p->pid = allocpid(); p->state = USED;
// Allocate a trapframe page. if((p->trapframe = (struct trapframe *)kalloc()) == 0){ freeproc(p); release(&p->lock); return 0; }
// An empty user page table. p->pagetable = proc_pagetable(p); if(p->pagetable == 0){ freeproc(p); release(&p->lock); return 0; }
// Set up new context to start executing at forkret, // which returns to user space. memset(&p->context, 0, sizeof(p->context)); p->context.ra = (uint64)forkret; p->context.sp = p->kstack + PGSIZE;
return p; }
<a name="WWs6s"></a>### 1.2 加载代码段每个进程都有属于自己的用户页表,这里 xv6 主要将进程的代码段映射到用户页表中,地址为 0 的地方,这里的代码段中的数据为 xv6 自己进行硬编码的二进制数据```c//uvminit(p->pagetable, initcode, sizeof(initcode));uchar initcode[] = {0x17, 0x05, 0x00, 0x00, 0x13, 0x05, 0x45, 0x02,0x97, 0x05, 0x00, 0x00, 0x93, 0x85, 0x35, 0x02,0x93, 0x08, 0x70, 0x00, 0x73, 0x00, 0x00, 0x00,0x93, 0x08, 0x20, 0x00, 0x73, 0x00, 0x00, 0x00,0xef, 0xf0, 0x9f, 0xff, 0x2f, 0x69, 0x6e, 0x69,0x74, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x00,0x00, 0x00, 0x00, 0x00};
翻译过来其实就是如下汇编代码
user/initcode.o: file format elf64-littleriscv
Disassembly of section .text:
0000000000000000 <start>:
#include "syscall.h"
# exec(init, argv)
.globl start
start:
la a0, init
0: 00000517 auipc a0,0x0
4: 00050513 mv a0,a0
la a1, argv
8: 00000597 auipc a1,0x0
c: 00058593 mv a1,a1
li a7, SYS_exec
10: 00700893 li a7,7
ecall
14: 00000073 ecall
0000000000000018 <exit>:
# for(;;) exit();
exit:
li a7, SYS_exit
18: 00200893 li a7,2
ecall
1c: 00000073 ecall
jal exit
20: ff9ff0ef jal ra,18 <exit>
0000000000000024 <init>:
24: 696e692f 0x696e692f
28: 0074 addi a3,sp,12
...
000000000000002b <argv>:
...
其执行了 exec("init", "..."),也就是加载 init 进程。
1.3 分配用户栈及代码入口
1.2 中将代码段加载到地址为 0 的地方,因此需要调度到该进程时,指令寄存器的值为 0,即 epc 寄存器的值为 0。
// prepare for the very first "return" from kernel to user.
p->trapframe->epc = 0; // user program counter
p->trapframe->sp = PGSIZE; // user stack pointer
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
p->state = RUNNABLE;
同时栈寄存器设置为 PGSIZE,这表示栈空间的大小为 [0, PGSIZE],而前面加载代码段内容的时候,其内容也映射在了 [0, PGSIZE],这里主要还是由于该进程较小,因此不用担心会相互覆盖。
1.4 小结
至此第一个进程就创建完毕了,这里总结一下需要如下操作:
- 从
proc数组中分配一个空闲的struct proc结构,有如下初始化操作- 分配
trapframe,该结构用于该进程在 用户态 和 内核态 中断时保存上下文 - 分配页表
- 初始化
ra寄存器与sp寄存器ra寄存器存放着指令地址,主要用于执行函数结束时,ret指令执行后要跳转到的指令位置,这里设置为forkretsp寄存器为栈寄存器,这里进程默认分配PGSIZE大小的用户栈
- 分配
- 加载用户代码段到用户页表中 0 ~ PGSIZE 这块区域
- 分配用户栈,并设置
epc寄存器为 0,这样当执行该进程时,就可以运行 step2 加载的代码段 - 设置进程状态为
RUNNABLE,表示进程已经准备好被调度
2. 首次调度进程
随着我们创建完第一个进程,那么一系列问题接踵而至:
- 假如我们初始化内核的指令流为 A,用户进程的指令流为 B,那么我们如何从 A 切换到 B
- 我们从 A 切换到 B,显然不能直接切换,因为涉及到权限问题,用户进程显然不能有内核权限,因此 A 切换 B 之前,需要改变当前的权限
当我们执行 B 指令流的时候,显然不能让其一直独占整个 CPU 下去(如果 B 存在死循环,显然会有问题),我们期望能够定时切换执行不同进程的指令流,防止一个进程卡死影响所有进程运行
2.1 寻找可以调度的进程
当 xv6 初始化完毕后,其最后执行
scheduler进行调度void main() { // init code ... scheduler(); }scheduler的定义如下void scheduler(void) { struct proc *p; struct cpu *c = mycpu(); c->proc = 0; for(;;){ // Avoid deadlock by ensuring that devices can interrupt. intr_on(); for(p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if(p->state == RUNNABLE) { // Switch to chosen process. It is the process's job // to release its lock and then reacquire it // before jumping back to us. p->state = RUNNING; c->proc = p; swtch(&c->context, &p->context); // Process is done running for now. // It should have changed its p->state before coming back. c->proc = 0; } release(&p->lock); } } }无限循环,遍历
proc数组,寻找可以调度的进程。然后通过swtch进行进程切换。
2.2 内核切换到目标进程
scheduler 主要对 struct cpu 和 struct proc 的 context 进行 swtch,把 cpu.context 保存起来,再加载 proc.context。swtch 其定义如下:
# Context switch
#
# void swtch(struct context *old, struct context *new);
#
# Save current registers in old. Load from new.
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret
其实质上就是一个 swap 操作,把当前上下文存放到 a0,再把 a1 上下文内容加载到当前上下文。
“上下文” 的定义为 struct context,如下:
// Saved registers for kernel context switches.
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
需要保存的寄存器如下 :
ra寄存器,因为swtch也是函数,当swtch执行完毕时,会调用ret指令,继而跳转到ra寄存器的指令sp寄存器,即进程的内核栈- callee-saved 寄存器 s0 ~s11,这些寄存器的选择主要基于 risc-v 的 calling convention
2.3 执行目标进程
swtch 加载了进程上下文中的 ra 寄存器,当执行 ret 指令的时候,就会跳转到 ra 寄存器中指令位置。allocproc 接口分配进程的时候,执行了如下语句:p->context.ra = (uint64)forkret
因此,当首次调度目标进程的时候,会执行 forkret 函数,该函数内容如下:
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void
forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
first = 0;
fsinit(ROOTDEV);
}
usertrapret();
}
该接口操作比较简单,主要关注 usertrapret 调用,根据这个名字也可以看出来,这里是准备切换到用户态。
void
usertrapret(void)
{
struct proc *p = myproc();
// we're about to switch the destination of traps from
// kerneltrap() to usertrap(), so turn off interrupts until
// we're back in user space, where usertrap() is correct.
intr_off();
// send syscalls, interrupts, and exceptions to trampoline.S
w_stvec(TRAMPOLINE + (uservec - trampoline));
// set up trapframe values that uservec will need when
// the process next re-enters the kernel.
p->trapframe->kernel_satp = r_satp(); // kernel page table
p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack
p->trapframe->kernel_trap = (uint64)usertrap;
p->trapframe->kernel_hartid = r_tp(); // hartid for cpuid()
// set up the registers that trampoline.S's sret will use
// to get to user space.
// set S Previous Privilege mode to User.
unsigned long x = r_sstatus();
x &= ~SSTATUS_SPP; // clear SPP to 0 for user mode
x |= SSTATUS_SPIE; // enable interrupts in user mode
w_sstatus(x);
// set S Exception Program Counter to the saved user pc.
w_sepc(p->trapframe->epc);
// tell trampoline.S the user page table to switch to.
uint64 satp = MAKE_SATP(p->pagetable);
// jump to trampoline.S at the top of memory, which
// switches to the user page table, restores user registers,
// and switches to user mode with sret.
uint64 fn = TRAMPOLINE + (userret - trampoline);
((void (*)(uint64,uint64))fn)(TRAPFRAME, satp);
}
其主要需要关注的操作如下:
- 设置先前的特权级为 user
- 更新 epc 寄存器,进程在初始化的时候会把
epc赋值为 0,这里是 xv6 统一分配的代码入口地址
这两步设置操作会在执行 sret 指令时让当前的特权级以及指令寄存器分别更新成对应值。
最后执行 userret,返回到用户态。
.globl userret
userret:
# userret(TRAPFRAME, pagetable)
# switch from kernel to user.
# usertrapret() calls here.
# a0: TRAPFRAME, in user page table.
# a1: user page table, for satp.
# switch to the user page table.
csrw satp, a1
sfence.vma zero, zero
# put the saved user a0 in sscratch, so we
# can swap it with our a0 (TRAPFRAME) in the last step.
ld t0, 112(a0)
csrw sscratch, t0
# 这里因为 a0 寄存器目前还存放着 userret 的参数,所以不能直接覆盖回去
# restore all but a0 from TRAPFRAME
ld ra, 40(a0)
ld sp, 48(a0)
ld gp, 56(a0)
ld tp, 64(a0)
ld t0, 72(a0)
ld t1, 80(a0)
ld t2, 88(a0)
ld s0, 96(a0)
ld s1, 104(a0)
ld a1, 120(a0)
ld a2, 128(a0)
ld a3, 136(a0)
ld a4, 144(a0)
ld a5, 152(a0)
ld a6, 160(a0)
ld a7, 168(a0)
ld s2, 176(a0)
ld s3, 184(a0)
ld s4, 192(a0)
ld s5, 200(a0)
ld s6, 208(a0)
ld s7, 216(a0)
ld s8, 224(a0)
ld s9, 232(a0)
ld s10, 240(a0)
ld s11, 248(a0)
ld t3, 256(a0)
ld t4, 264(a0)
ld t5, 272(a0)
ld t6, 280(a0)
# restore user a0, and save TRAPFRAME in sscratch
csrrw a0, sscratch, a0
# return to user mode and user pc.
# usertrapret() set up sstatus and sepc.
sret
2.4 小结
关于进程首次调度,这里小结一下:
- xv6 初始化完毕后,每个 CPU 会有自己的执行流,其最后都是在无限循环执行
scheduler函数 scheduler主要做两件事情- 在
proc数组中找到准备好执行的进程 - 找到目标进程后,通过
swtch,把内核执行流切换到目标进程的执行流
- 在
- 进程首次通过
swtch调度时,会执行forkret,这是因为swtch执行ret会跳转到ra寄存器,而进程初始化的时候设置了ra寄存器的值为forkret - 接下来的执行流程为
forkret->usertrapret->userret,切换特权级,以及内存页表,从而切换到用户进程的代码段,具体代码段执行的位置由中断时设置的epc寄存器的值决定的,初始化进程的时候被设置为 0。
对于首次调度的进程,处于内核态,需要通过模拟退出中断的方式,让其切换到用户态,执行用户代码。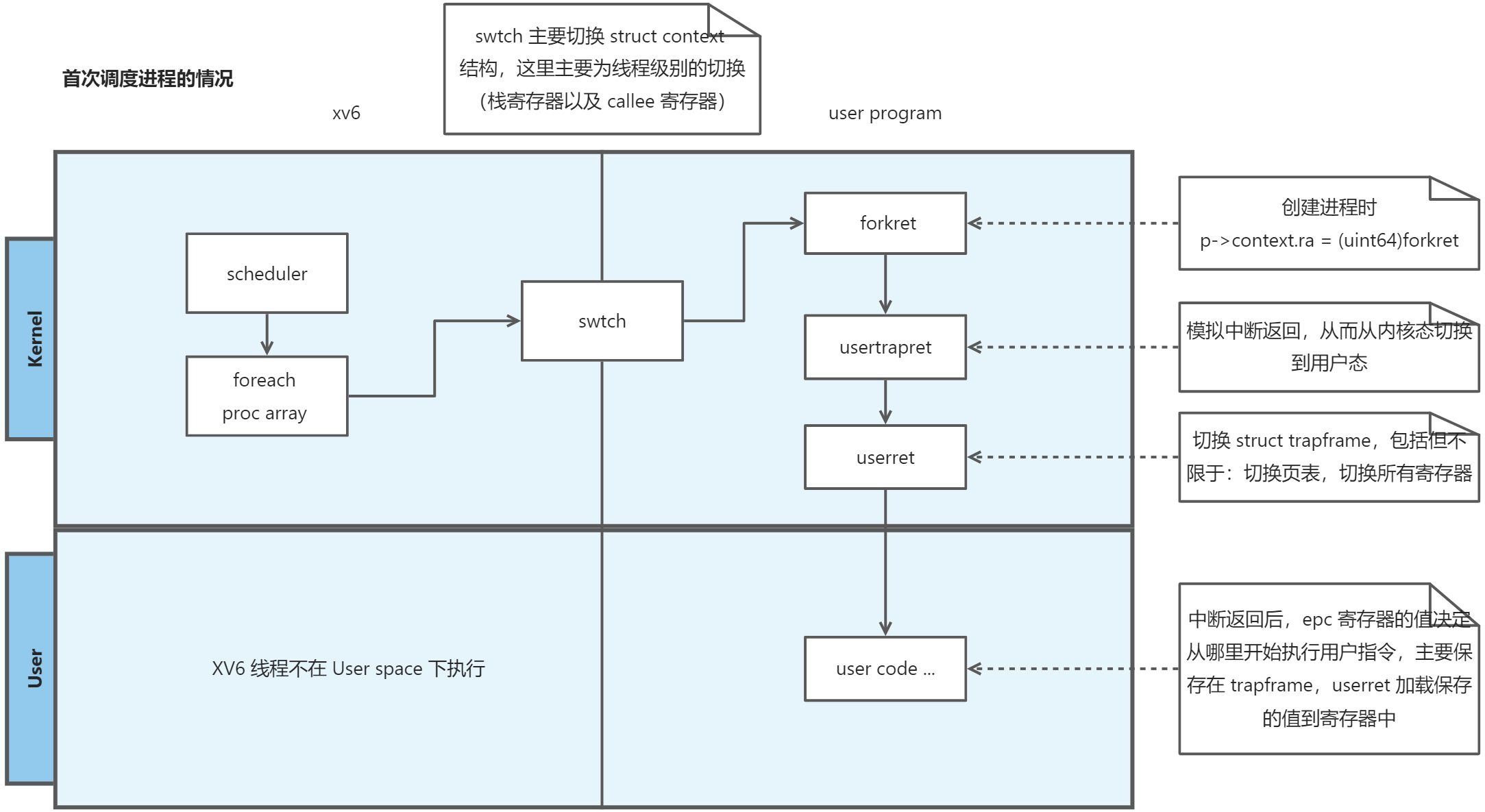
3. 运行时切换进程
进程运行时切换主要是通过时钟中断,xv6 的切换算法比较简单,每次触发时钟中断都会去执行调度,linux 则是通过时间片,优先级等方式来决定是否调度,调度哪些进程。
时钟中断会定时触发,这里我们主要关心触发中断后 xv6 是如何进行调度的,用户态下中断的处理函数如下:
void usertrap(void)
{
// some code ...
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
// some code ...
}
对于时钟中断,其处理接口为 yield
// Give up the CPU for one scheduling round.
void yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}
yield 继续调用 sched
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}
sched 中又看到了熟悉的 swtch,这里将上下文从 进程内核态 切换到当前 cpu 保存的上下文。这意味着会接下来会回到 scheduler 。
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
内核线程会从 20 行开始继续执行,找到合适的进程让其执行。其流程如下图所示: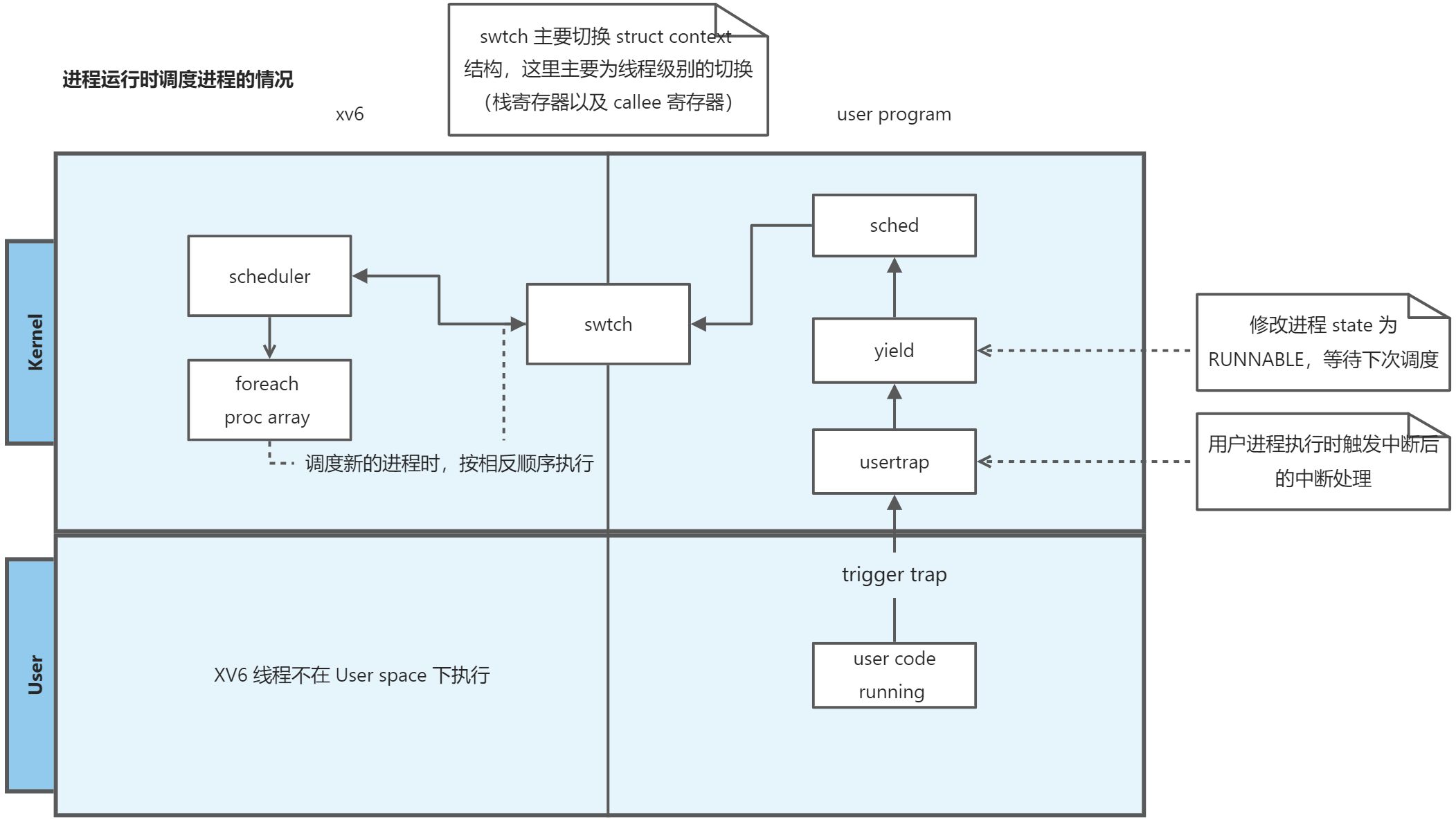
4. 小结
调度的核心在于内核态中内核线程的 swtch 交换 struct context 和 用户态到内核态的相互切换 struct trapframe
:::info
创建进程的关键流程如下:
- 从
proc数组中分配一个空闲的struct proc结构,有如下初始化操作- 分配
trapframe,该结构用于该进程在 用户态 和 内核态 中断时保存上下文trapframe会设置epc寄存器为 0,这是因为 xv6 中设定用户进程的代码段起始虚拟地址为 0
- 分配用户页表
- 初始化
ra寄存器与sp寄存器ra寄存器存放着指令地址,主要用于执行函数结束时,ret指令执行后要跳转到的指令位置,这里设置为forkretsp寄存器为栈寄存器,这里进程默认分配PGSIZE大小的用户栈
- 分配
- 加载用户代码段到用户页表中 0 ~ PGSIZE 这块区域
- 分配用户栈
- 设置进程状态为
RUNNABLE,表示进程已经准备好被调度 :::首次调度进程时,流程如下:
- xv6 初始化完毕后,每个 CPU 会有自己的内核线程,其最后都是在无限循环执行
scheduler函数 scheduler主要做两件事情- 在
proc数组中找到准备好执行的进程 - 找到目标进程后,通过
swtch,把内核执行流切换到目标进程的执行流
- 在
- 进程首次通过
swtch调度时,会执行forkret,这是因为swtch执行ret会跳转到ra寄存器,而进程初始化的时候设置了ra寄存器的值为forkret - 接下来的执行流程为
forkret->usertrapret->userret,切换特权级,以及内存页表,从而切换到用户进程的代码段,具体代码段执行的位置由中断时设置的epc寄存器的值决定的,初始化进程的时候被设置为 0。
对于首次调度的进程,处于内核态,需要通过模拟退出中断的方式,让其切换到用户态,执行用户代码。
- xv6 初始化完毕后,每个 CPU 会有自己的内核线程,其最后都是在无限循环执行
运行时调度进程,流程如下:
- 通过时钟中断,进入内核
- 内核执行流程为
usertrap->yield->sched->swtch->scheduler- 当执行完
swtch时,从用户线程切换到了内核线程,内核线程一直在执行scheduler,找寻合适的进程,然后再通过swtch切换到新的目标用户线程

若有收获,就点个赞吧
0 人点赞
