- 为什么要研究树结构
- 二分搜索树
- 二分搜索树基础
- 向二分搜索树中添加元素
- 改进添加操作:深入理解递归终止条件
- 作业:和二分搜索树的添加相关的两个问题todo
- 二分搜索树的查询操作
- 二分搜索树的前序遍历
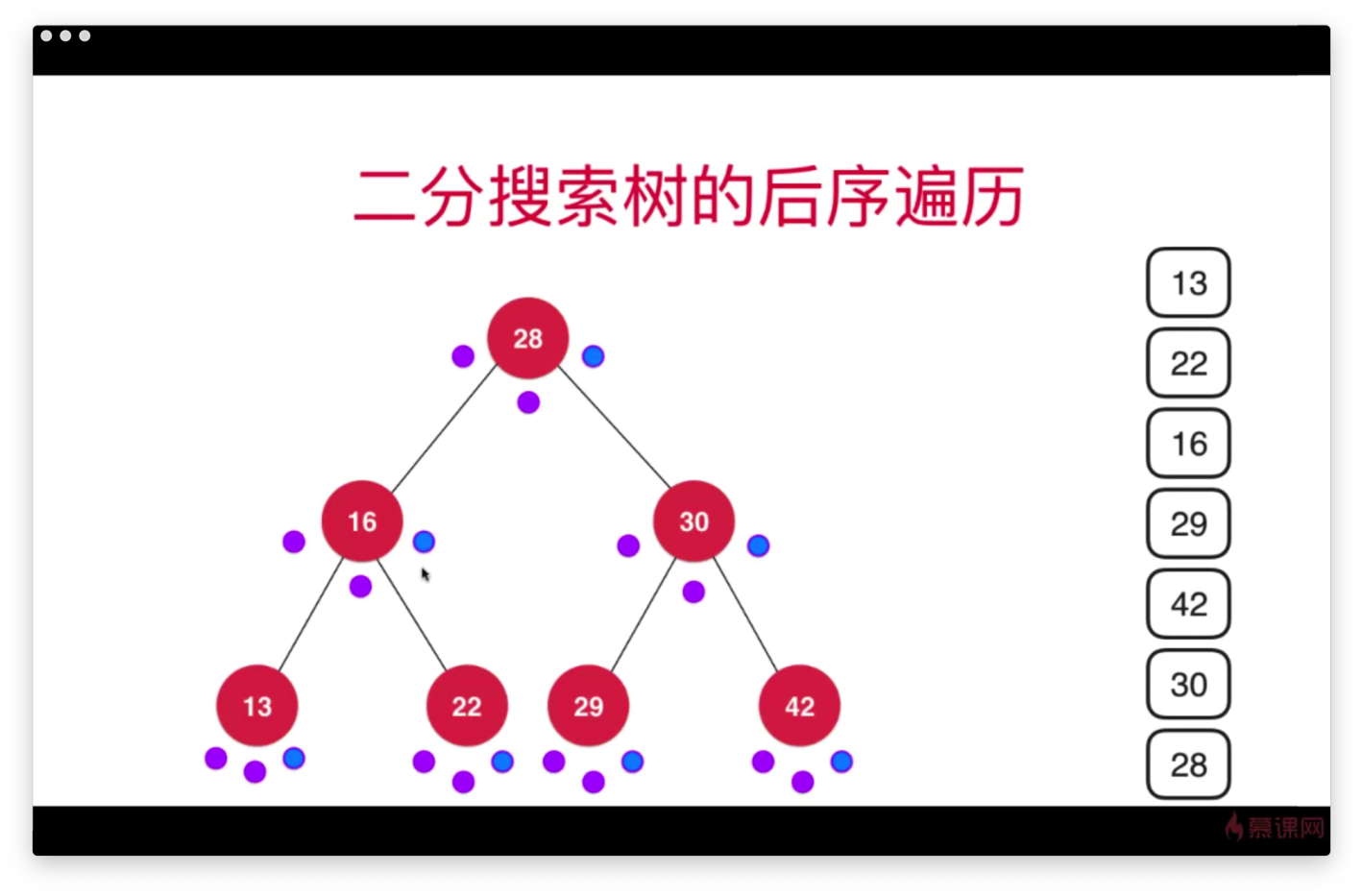
- 二分搜索树的中序遍历和后序遍历
- 深入理解二分搜索树的前中后序遍历.mp4
- 二分搜索树前序遍历的非递归实现
- 二分搜索树的层序遍历
- 删除二分搜索树的最大元素和最小元素
- 删除二分搜索树的任意元素
- 更多二分搜索树相关话题.mp4
- ❤二分搜索树相关练习
- 集合基础和基于二分搜索树的集合实现
- 基于链表的集合实现
- 集合类的复杂度分析
- ❤集合相关练习题
- 映射基础
- 基于链表的映射实现.mp4
- 基于二分搜索树的映射实现.mp4
- 映射的复杂度分析和更多映射相关问题.mp4
- ❤映射相关练习题
为什么要研究树结构
二分搜索树
二分搜索树基础
和链表一样动态数据结构
二叉树(多叉树)
二叉树具有唯一根节点
二叉树每个节点最多有两个孩子
二叉树每个节点最多有一个父亲
二叉树具有天然递归结构
每个节点的左子树也是二叉树
每个节点的右子树也是二叉树
class Node {E e;Node left; // 左孩子Node right; // 右孩子}


二分搜索树
二分搜索树是二叉树
二分搜索树的每个节点的值:
大于其左子树的所有节点的值
小于其右子树的所有节点的值
每一颗子树也是二分搜索树。
存储的元素必须有可比较性

向二分搜索树中添加元素
我们的二分搜索树不包含重复元素,如果想包含重复元素的话,只要定义:左子树小于等于节点,或者右子树大于等于节点。
注意我们之前讲的数组和链表,可以有重复元素。
二分搜索树添加元素的非递归写法和链表很像。
注意二分搜索树可能退化成一个链表。
在二分搜索树方面,递归比非递归简单
public class BST<E extends Comparable<E>> {private class Node {public E e;public Node left, right;public Node(E e) {this.e = e;left = null;right = null;}}private Node root;private int size;public BST(){root = null;size = 0;}public int size(){return size;}public boolean isEmpty(){return size == 0;}// 向二分搜索树中添加新的元素epublic void add(E e){// 根节点为空,用当前的值创建一个节点,赋值给 rootif(root == null){root = new Node(e);size ++;}else // 根节点不为空,进行递归添加add(root, e);}// 向以node为根的二分搜索树中插入元素e,递归算法private void add(Node node, E e){// 如果插入的值和当前节点的值相等,则什么都不做if(e.equals(node.e))return;// 如果插入的值比当前节点的值小且当前的节点的左子树为空就将这个值放到当前节点的左子树上else if(e.compareTo(node.e) < 0 && node.left == null){node.left = new Node(e);size ++;return;}// 如果插入的值比当前节点的值小且当前的节点的右子树为空就将这个值放到当前节点的右子树上else if(e.compareTo(node.e) > 0 && node.right == null){node.right = new Node(e);size ++;return;}// 如果插入的值比当前节点的值小且当前节点有左子树if(e.compareTo(node.e) < 0)add(node.left, e);else //e.compareTo(node.e) > 0// 如果插入的值比当前节点的值小且当前节点有右子树add(node.right, e);}}
改进添加操作:深入理解递归终止条件
public class BST<E extends Comparable<E>> {
// ...
// 向二分搜索树中添加新的元素e
public void add(E e){
root = add(root, e);
}
// 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, E e){
// 如果节点为空则创建一个新节点并返回
if(node == null){
size ++;
return new Node(e);
}
// 如果传入的值小于当前节点的值,在树的左子树添加节点
if(e.compareTo(node.e) < 0)
node.left = add(node.left, e);
// 如果传入的值大于当前节点的值,在树的右子树添加节点
else if(e.compareTo(node.e) > 0)
node.right = add(node.right, e);
// 返回修改后的节点
return node;
}
}
作业:和二分搜索树的添加相关的两个问题todo
private void add(Node node, E e) {
if (node == null) {
size++;
node = new Node(e);
return;
}
if (e.compareTo(node.e) < 0) add(node.left, e);
else if (e.compareTo(node.e) > 0) add(node.right, e);
}
上面这样写是不行的,
二分搜索树的查询操作
public boolean contains(E e) {
return contains(root, e);
}
private boolean contains(Node node, E e) {
if (node == null) return false;
if (e.compareTo(node.e) == 0) return true;
else if (e.compareTo(node.e) < 0) return contains(node.left, e);
else return contains(node.right, e);
}
二分搜索树的前序遍历
什么是遍历操作?
遍历操作就是把所有节点都访问一遍。
前序遍历是最自然的遍历方式,最常用的遍历方式
public void preOrder() {
preOrder(root);
}
private void preOrder(Node node) {
if (node == null) return;
System.out.println(node.e);
preOrder(node.left);
preOrder(node.right);
}
二分搜索树的中序遍历和后序遍历
二分搜索树的中序遍历结果是顺序的。
后序遍历的一个应用 - 为二分搜索树释放内存
中序遍历:
public void inOrder() {
inOrder(root);
}
private void inOrder(Node node) {
if (node == null) return;
inOrder(node.left);
System.out.println(node.e);
inOrder(node.right);
}
后序遍历:
public void postOrder() {
postOrder(root);
}
private void postOrder(Node node) {
if (node == null) return;
postOrder(node.left);
postOrder(node.right);
System.out.println(node.e);
}
深入理解二分搜索树的前中后序遍历.mp4


二分搜索树前序遍历的非递归实现
public void preOrderNR() {
if (root == null) return;
Stack<Node> stack = new Stack();
stack.push(root);
while (!stack.isEmpty()) {
Node cur = stack.pop();
System.out.println(cur.e);
if (cur.right !=null) stack.push(cur.right);
if (cur.left != null) stack.push(cur.left);
}
}
二分搜索树的层序遍历
public void levelOrder() {
if (root == null) return;
Queue<Node> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
Node cur = queue.remove();
System.out.println(cur.e);
if (cur.left != null) queue.add(cur.left);
if (cur.right != null) queue.add(cur.right);
}
}
广度优先遍历的意义,更快的找到问题的解,常用于算法设计中的最短路径。
删除二分搜索树的最大元素和最小元素
查找最大值和最小值
// 查找二分搜索树中的最小元素
public E minimum() {
if (size == 0) throw new IllegalArgumentException("BST is empty");
return minimum(root).e;
}
// // 返回以 node 为根的二分搜索树的最小值所在的节点
private Node minimum(Node node) {
if (node.left == null) return node;
return minimum(node.left);
}
// 查找二分搜索树中的最大元素
public E maximum() {
if (size == 0) throw new IllegalArgumentException("BST is empty");
return maximum(root).e;
}
// 返回以 node 为根的二分搜索树的最大值所在的节点
private Node maximum(Node node) {
if (node.right == null) return node;
return maximum(node.right);
}
删除二分搜索树中的最小值:找到最小值所在的节点,删除的时候要注意这个节点有右子树的时候,要把右子树变成删除节点后那个节点的左子树。
删除二分搜索树中的最大值:找到最大值所在的节点,删除的时候要注意这个节点有左子树的时候,要把右子树变成删除节点后那个节点的右子树。
移除最大值和最小值:
// 从二分搜索树中删除最小值所在节点,返回最小值
public E removeMin() {
// 获取最小值
E ret = minimum();
// 递归查找并删除最小值节点
root = removeMin(root);
// 返回最小值
return ret;
}
// 删除以 node 为根的二分搜索树中的最小节点,返回删除节点后新的二分搜索树的根
private Node removeMin(Node node) {
// 当前节点的左子树为空,说明左子树已经遍历到底了
if (node.left == null) {
// 将最下面的左子树的右子树保留到变量 rightNode 上
Node rightNode = node.right;
// 清空这个节点的右子树
node.right = null;
// 数量减一
size--;
// 返回保存的右子树节点
return rightNode;
}
// 将返回的右子树赋值给左子树,注意这个左子树是待删除节点的上一级
node.left = removeMin(node.left);
return node;
}
// 从二分搜索树中删除最大值所在节点,返回最大值
public E removeMax() {
// 查找最大值
E ret = maximum();
// 递归查找并删除最大值
root = removeMax(root);
// 返回最大值
return ret;
}
// 删除以 node 为根的二分搜索树中的最大节点,返回删除节点后新的二分搜索树的根
private Node removeMax(Node node) {
// 待删除节点的右子树为空,说明遍历最大值到底了
if (node.right == null) {
// 保存待删除节点的左子树
Node leftNode = node.left;
// 将待删除节点的左子树置空,也就是删除
node.left = null;
// 数量减一
size--;
// 返回保留的待删除节点的左子树
return leftNode;
}
// 将待删除节点的左子树赋值给待删除节点的上一级节点的右子树
node.right = removeMax(node.right);
// 返回删除节点的上一层节点
return node;
}
测试代码:
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.Random;
public class Main {
public static void main(String[] args) {
BST<Integer> bst = new BST();
Random random = new Random();
int n = 1000;
for (int i = 0; i < n; i++)
bst.add(random.nextInt(10000));
ArrayList<Integer> nums = new ArrayList<>();
while (!bst.isEmpty())
nums.add(bst.removeMin());
System.out.println(nums);
for (int i = 1; i < nums.size(); i++)
if (nums.get(i - 1) > nums.get(i))
throw new IllegalArgumentException("Error");
System.out.println("removeMin test completed");
// test removeMax
for (int i = 0; i < n; i++)
bst.add(random.nextInt(10000));
nums = new ArrayList<>();
while (!bst.isEmpty())
nums.add(bst.removeMax());
System.out.println(nums);
for (int i = 1; i < nums.size(); i++)
if (nums.get(i - 1) < nums.get(i))
throw new IllegalArgumentException("Error");
System.out.println("removeMax test completed");
}
}
删除二分搜索树的任意元素

二分搜索树删除某个节点可以分为三种情况:
- 待删除没有左子树
- 待删除节点没有右子树
- 待删除节点既有左子树也有右子树
对于前两种情况操作起来是很方便的。
public void remove(E e) {
root = remove(root, e);
}
private Node remove(Node node, E e) {
// if the node is empty, return directly
if (node == null) return null;
// 如果待删除的值小于当前节点的值,继续在左子树删除
if (e.compareTo(node.e) < 0) {
node.left = remove(node.left, e);
return node;
}
// 如果待删除的值大于当前节点的值,继续在右子树删除
else if (e.compareTo(node.e) > 0) {
node.right = remove(node.right, e);
return node;
} else { // 要删除的值和当前节点的值相等,则删除当前节点
// 左子树为空
if (node.left == null) {
Node nodeRight = node.right;
node.right = null;
size--;
return nodeRight;
}
if (node.right == null) { // 右子树为空
Node nodeLeft = node.left;
node.left = null;
size--;
return nodeLeft;
}
// 找到待删除节点右子树上最小值节点
Node successor = minimum(node.right);
//
successor.right = removeMin(node.right);
// size++;
successor.left = node.left;
node.left = node.right = null;
// 一加一减 size 抵消了
// size--;
return successor;
}
}
更多二分搜索树相关话题.mp4
二分搜索树的中序遍历是有序的:从小到大。

❤二分搜索树相关练习
1. 二叉搜索树中第K小的元素-230
2. 二叉搜索树的最近公共祖先-235
3. 删除二叉搜索树中的节点-450
4. 二叉搜索树中的搜索-700
5. 二叉搜索树中的插入操作-701
6. 数据流中的第 K 大元素-703
7. 将二叉搜索树变平衡-1382
8. 将有序数组转换为二叉搜索树-108
9. 把二叉搜索树转换为累加树-538
10. 验证二叉搜索树-98
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:root = [2,1,3]
输出:true
示例 2:
输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
提示:
树中节点数目范围在[1, 104] 内
-231 <= Node.val <= 231 - 1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/validate-binary-search-tree
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
JS:
var isValidBST = function (root) {
let minValue = -Infinity;
function inorder(root) {
if (!root) return true;
if (!inorder(root.left)) return false;
if (root.val <= minValue) return false;
minValue = root.val;
return inorder(root.right);
}
return inorder(root);
};
集合基础和基于二分搜索树的集合实现
集合不能存放重复元素。典型应用有:客户统计、词汇量统计
前面我们介绍了二分搜索树,这里我们使用前面的二分搜索树来实现集合:
// src/Set.java
public interface Set<E> {
void add(E e);
void remove(E e);
boolean contains(E e);
int getSize();
boolean isEmpty();
}
// src/BSTSet.java
public class BSTSet<E extends Comparable<E>> implements Set<E> {
private BST<E> bst;
public BSTSet() {
bst = new BST<>();
}
@Override
public void add(E e) {
bst.add(e);
}
@Override
public boolean isEmpty() {
return bst.isEmpty();
}
@Override
public void remove(E e) {
}
@Override
public int getSize() {
return bst.size();
}
@Override
public boolean contains(E e) {
return bst.contains(e);
}
}
测试下我们的代码:
// src/Main.java
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<String> words = new ArrayList<>();
if (FileOperation.readFile("pride-and-prejudice.txt", words)) {
System.out.println("Total words " + words.size());
BSTSet<String> set = new BSTSet<>();
for (String word:words) {
set.add(word);
}
System.out.println("Total different words " + set.getSize());
}
}
}
基于链表的集合实现
二分搜索树和链表都属于动态搜索树。
// 树
class Node {
E e;
Node left;
Node right;
}
// 链表
class Node {
E e;
Node next;
}
实现:
public class LinkedList<E> {
private class Node{
public E e;
public Node next;
public Node(E e, Node next){
this.e = e;
this.next = next;
}
public Node(E e){
this(e, null);
}
public Node(){
this(null, null);
}
@Override
public String toString(){
return e.toString();
}
}
private Node dummyHead;
private int size;
public LinkedList(){
dummyHead = new Node();
size = 0;
}
// 获取链表中的元素个数
public int getSize(){
return size;
}
// 返回链表是否为空
public boolean isEmpty(){
return size == 0;
}
// 在链表的index(0-based)位置添加新的元素e
// 在链表中不是一个常用的操作,练习用:)
public void add(int index, E e){
if(index < 0 || index > size)
throw new IllegalArgumentException("Add failed. Illegal index.");
Node prev = dummyHead;
for(int i = 0 ; i < index ; i ++)
prev = prev.next;
prev.next = new Node(e, prev.next);
size ++;
}
// 在链表头添加新的元素e
public void addFirst(E e){
add(0, e);
}
// 在链表末尾添加新的元素e
public void addLast(E e){
add(size, e);
}
// 获得链表的第index(0-based)个位置的元素
// 在链表中不是一个常用的操作,练习用:)
public E get(int index){
if(index < 0 || index >= size)
throw new IllegalArgumentException("Get failed. Illegal index.");
Node cur = dummyHead.next;
for(int i = 0 ; i < index ; i ++)
cur = cur.next;
return cur.e;
}
// 获得链表的第一个元素
public E getFirst(){
return get(0);
}
// 获得链表的最后一个元素
public E getLast(){
return get(size - 1);
}
// 修改链表的第index(0-based)个位置的元素为e
// 在链表中不是一个常用的操作,练习用:)
public void set(int index, E e){
if(index < 0 || index >= size)
throw new IllegalArgumentException("Set failed. Illegal index.");
Node cur = dummyHead.next;
for(int i = 0 ; i < index ; i ++)
cur = cur.next;
cur.e = e;
}
// 查找链表中是否有元素e
public boolean contains(E e){
Node cur = dummyHead.next;
while(cur != null){
if(cur.e.equals(e))
return true;
cur = cur.next;
}
return false;
}
// 从链表中删除index(0-based)位置的元素, 返回删除的元素
// 在链表中不是一个常用的操作,练习用:)
public E remove(int index){
if(index < 0 || index >= size)
throw new IllegalArgumentException("Remove failed. Index is illegal.");
Node prev = dummyHead;
for(int i = 0 ; i < index ; i ++)
prev = prev.next;
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size --;
return retNode.e;
}
// 从链表中删除第一个元素, 返回删除的元素
public E removeFirst(){
return remove(0);
}
// 从链表中删除最后一个元素, 返回删除的元素
public E removeLast(){
return remove(size - 1);
}
// 从链表中删除元素e
public void removeElement(E e){
Node prev = dummyHead;
while(prev.next != null){
if(prev.next.e.equals(e))
break;
prev = prev.next;
}
if(prev.next != null){
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
size --;
}
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
Node cur = dummyHead.next;
while(cur != null){
res.append(cur + "->");
cur = cur.next;
}
res.append("NULL");
return res.toString();
}
}
public interface Set<E> {
void add(E e);
void remove(E e);
int getSize();
boolean isEmpty();
boolean contains(E e);
}
public class LinkedListSet<E> implements Set<E> {
private LinkedList<E> list;
public LinkedListSet() {
list = new LinkedList<>();
}
@Override
public void add(E e) {
// 判断列表中是否已包含当前元素,不包含的话进行添加,否则不执行任何操作
if (!list.contains(e)) list.addFirst(e);
}
@Override
public boolean contains(E e) {
return list.contains(e);
}
@Override
public void remove(E e) {
list.removeElement(e);
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
@Override
public int getSize() {
return list.getSize();
}
}
验证:
import java.util.ArrayList;
public class Main {
public static void main(String str[]) {
ArrayList<String> words = new ArrayList<>();
if (FileOperation.readFile("pride-and-prejudice.txt", words)) {
System.out.println("pride-and-prejudice.txt:" + words.size());
LinkedListSet<String> set = new LinkedListSet<>();
for (String word: words) set.add(word);
System.out.println("Total different words:" + set.getSize());
}
}
}
集合类的复杂度分析
前面我们分别使用二分搜索树和链表实现了集合,下面我们来看下它们两个谁的性能会更好点呢?
二分搜索树的时间复杂度是 O(h),链表的时间复杂度为 O(n),你可能会问 O(h) 是多少。。。这里的 h 代表树的高度
使用二分搜索树实现的集合和树的节点有关系,
对于集合我们重点分析 add、contains、remove 三个方法的时间复杂度:
| 方法 | 二分搜索树平均时间复杂度 | 链表时间复杂度 |
|---|---|---|
| add | O(logn) | O(n) |
| contains | O(logn) | O(n) |
| remove | O(logn) | O(n) |
可能从上表你还体会不出 O(logn) 和 O(n) 的差距,下面我们举例说明:
| n | logn | 2^n | 2^n 和 logn 差距 |
|---|---|---|---|
| n = 16 | 4 | 16 | 相差 4 倍 |
| n = 1024 | 10 | 1024 | 相差 100 倍 |
| n = 100万 | 20 | 100万 | 相差 5 万倍 |
可以看出 n 越大,它们之间的差距越明显。
同样的数据可以对应不同的二分搜索树,最坏的情况可能退化成链表。所以使用二分搜索树最坏的时间复杂度可能为 O(n) 。
有序集合中的元素具有有序性,基于二分搜索树实现
无序集合中的元素没有顺序性,基于哈希表实现
❤集合相关练习题
1. 唯一摩尔斯密码词-804
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如:
'a' 对应 ".-" ,
'b' 对应 "-..." ,
'c' 对应 "-.-." ,以此类推。
为了方便,所有 26 个英文字母的摩尔斯密码表如下:
[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
给你一个字符串数组 words ,每个单词可以写成每个字母对应摩尔斯密码的组合。
例如,"cab" 可以写成 "-.-..--..." ,(即 "-.-." + ".-" + "-..." 字符串的结合)。我们将这样一个连接过程称作 单词翻译 。
对 words 中所有单词进行单词翻译,返回不同 单词翻译 的数量。
示例 1:
输入: words = ["gin", "zen", "gig", "msg"]
输出: 2
解释:
各单词翻译如下:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
共有 2 种不同翻译, "--...-." 和 "--...--.".
示例 2:
输入:words = ["a"]
输出:1
提示:
1 <= words.length <= 100
1 <= words[i].length <= 12
words[i] 由小写英文字母组成
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-morse-code-words
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
import java.util.TreeSet;
public class Solution {
public static int uniqueMorseRepresentations(String[] words) {
String[] codes = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."};
TreeSet<String> set = new TreeSet<>();
for (String word:words) {
StringBuilder res = new StringBuilder();
for (int i = 0, len = word.length(); i < len; i++) {
res.append(codes[word.charAt(i) - 'a']);
}
set.add(res.toString());
}
return set.size();
}
}
2. 两个数组的交集-349
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/intersection-of-two-arrays
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路:
- 暴力解法
找到两个数组中较长的那个,遍历它,在遍历的时候判断当前值是否存在较短数组中,如果存在且当前值没有存在结果数组中,就将这个值存入结果数组,遍历结束后返回结果数组即可。
var intersection = function (nums1, nums2) {
const res = [];
// 获取 nums1 数组长度
let len1 = nums1.length;
// 获取 nums2 数组长度
let len2 = nums2.length;
// 设置标志位
let flag = false;
// temp1 存放较长数组,temp2 存放较短数组
let temp1 = [], temp2 = [];
// 如果 len1 >= len2,则 num1 为较长数组,将这个数组存入 temp1,否则 nums2 为较长数组
if (len1 >= len2) {
temp1 = nums1;
// 将标志位置为真,表明 nums1 是长数组
flag = true;
} else {
temp1 = nums2;
}
// 如果标志位为真,则 nums2 为较短数组,否则 nums1 为较短数组,存入 temp2
if (flag) {
temp2 = nums2;
} else {
temp2 = nums1;
}
// 遍历较长数组
for (let i = 0; i < temp1.length; i++) {
// 如果 temp2 中包含当前元素,且结果数组中不包含当前元素,就将当前元素存入结果数组中
if (temp2.includes(temp1[i]) && !res.includes(temp1[i])) {
res.push(temp1[i]);
}
}
// 返回结果数组
return res;
};
- 使用集合
将数组一中的每个元素存入集合中,遍历数组二,判断当前遍历到的值是否存在集合中,如果存在就将这个值存入结果数组并从集合中删除这个值,删除的原因是为了防止数组二中存在多个相同的值。遍历结束后将结果数组返回即可。
Java 版本代码:
import java.util.ArrayList;
import java.util.TreeSet;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
TreeSet<Integer> set = new TreeSet<>();
for(int num:nums1) set.add(num);
ArrayList<Integer> list = new ArrayList<>();
for (int num: nums2) {
if (set.contains(num)) {
list.add(num);
set.remove(num);
}
}
int[] res = new int[list.size()];
for (int i = 0, len = list.size(); i < len; i++) res[i] = list.get(i);
return res;
}
}
JS 版本代码:
var intersection = function (nums1, nums2) {
const res = [];
const set = new Set();
nums1.forEach(item => set.add(item));
nums2.forEach(item => {
if (set.has(item)) {
res.push(item);
set.delete(item);
}
});
return res;
};
映射基础
映射是一种存储键值对的数据结构,我们可以根据键可以寻找值。对于映射这种数据结构,我们可以使用前面学到的链表或者二分搜索树实现。
关于映射我们需要实现下面几个方法:
void add(K, V);
V remove(K k);
V get(K k);
void set(K k, V v);
int getSize();
boolean isEmpty();
boolean contains();
使用链表实现映射
使用二分搜索树实现映射
基于链表的映射实现.mp4
基于二分搜索树的映射实现.mp4
映射的复杂度分析和更多映射相关问题.mp4
❤映射相关练习题
1. 两个数组的交集 II
给你两个整数数组 nums1 和 nums2 ,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值)。可以不考虑输出结果的顺序。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2,2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[4,9]
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/intersection-of-two-arrays-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路:
遍历 nums1 使用映射 map 的 key 存储 nums1 中出现的值,使用映射的 value 存储当前 key 出现的频率。然后再遍历 nums2 ,看看当前值是否存在与映射 map 中,如果存在,说明这个值是 nums1 和 num2 的交集,将这个值存入结果数组,并使映射中相应的 key 的频率减一,你可能会问,为啥要减一?这是为了 如果映射中当前值出现的频率减为 0,这从映射中移除当前值作为 key 的选项,这是为了 最后返回结果数组。
Java :
import java.util.ArrayList;
import java.util.TreeMap;
class Solution {
public int[] intersect(int[] nums1, int[] nums2) {
TreeMap<Integer, Integer> map = new TreeMap<>();
for (int num:nums1) {
if (!map.containsKey(num)) map.put(num, 1);
else map.put(num, map.get(num) + 1);
}
ArrayList<Integer> list = new ArrayList<>();
for (int num:nums2) {
if (map.containsKey(num)) {
list.add(num);
map.put(num, map.get(num) - 1);
if (map.get(num) == 0) map.remove(num);
}
}
int[] res = new int[list.size()];
for (int i = 0,len = list.size(); i < len; i++)
res[i] = list.get(i);
return res;
}
}
JS :
var intersect = function (nums1, nums2) {
let res = []
// 遍历 nums1 数组
for (let i = 0; i < nums1.length; i++) {
// 看看当前元素是否在 nums2 中存在
let index = nums2.indexOf(nums1[i])
// 如果存在
if (index !== -1) {
// 将当前元素添加到结果数组
res.push(nums1[i])
// 删除 nums2 中和当前元素相等的最前面的那个值,这里必须删除,如果 nums1 = [1, 1, 1] nums2 = [1] 这样就会有问题
nums2.splice(index, 1)
}
}
// 返回结果数组
return res
};
上述代码的JS版本
function TreeNode(val) {
this.val = val;
this.left = null;
this.right = null;
}
function BST() {
this.root = null;
}
BST.prototype.add = function (val) {
this.root = _add(this.root, val);
};
BST.prototype.contains = function (val) {
return _contains(this.root, val);
};
BST.prototype.preOrder = function () {
_preOrder(this.root);
};
function _preOrder(node) {
if (!node) return;
console.log(node.val);
_preOrder(node.left);
_preOrder(node.right);
}
function _contains(node, val) {
if (!node) return false;
if (val == node.val) return true;
else if (val < node.val) return _contains(node.left, val);
else return _contains(node.right, val);
}
function _add(node, e) {
if (!node) return new TreeNode(e);
if (e < node.val) node.left = _add(node.left, e);
else if (e > node.val) node.right = _add(node.right, e);
return node;
}
BST.prototype.removeMin = function () {
this.root = _removeMin(this.root);
};
function _removeMin(node) {
if (!node.left) {
const nodeRight = node.right;
node.right = null;
return nodeRight;
}
node.left = _removeMin(node.left);
return node;
}
BST.prototype.removeMax = function () {
this.root = _removeMax(this.root);
};
function _removeMax(node) {
if (!node.right) {
const nodeLeft = node.left;
node.left = null;
return nodeLeft;
}
node.right = _removeMax(node.right);
return node;
}
const bst = new BST();
const arr = [10, 2, 45, 5, 66];
arr.forEach(item => bst.add(item));
// console.log(bst.contains(100))
// bst.preOrder(bst.root);
// console.log(bst.root);
bst.removeMin();
// console.log(bst.root);
// console.log(bst.root);
// bst.removeMax();
// console.log(bst.root);

若有收获,就点个赞吧
0 人点赞
