背景
在数据仓库中,未经任何加工处理的原始数据,我们称之为ODS数据。在互联网企业中,常见的ODS数据有业务日志(Log)和业务DB数据(DB)两类。对于业务DB数据来说,从Mysql 等关系行数据库的业务数据进行采集,然后导入到Hive中,是进行数据仓库生产的重要环节。
如何准确、高效地把Mysql 数据同步到Hive 中?
一般解决方案是批量取数并Load: 直连Mysql 去Select表中的数据,然后存到本地文件作为中间存储,最后把文件Load 到 Hive 表中。这种方案的优点是实现简单,但是随着业务的发展,缺点也暴露出来:
- 性能瓶颈:随着业务的增长,Select From Mysql -> Save to Localfiel ->Load to Hive 这种数据流花费的时间越来越长,无法满足下游数仓生产的时间要求
- 直接从Mysql 中Select 大量数据,对Mysql的影响特别大,容易造成慢查询,影响业务线上的正常服务
- 由于Hive本身的语法不支持删除、更新等SQL语法,对于Mysql 中发生Update/Delete的数据无法很好的进行支持。
为了解决Select From Mysql -> Load to Hive 中存在的问题,新的解决方案 CDC + merge
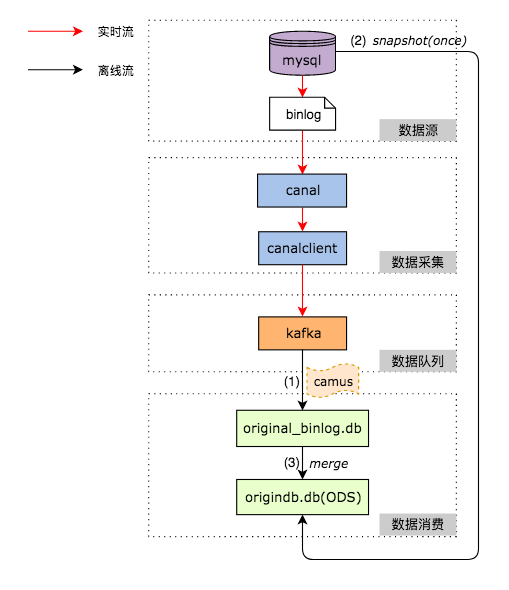
为了彻底解决这些问题,我们逐步转向CDC(Change Data Capture)+ Merge的技术方案,即实时Binlog采集+ 离线处理Binlog还原业务数据这样一套解决方案。Binlog 是Mysql 的二进制日志,记录了Mysql 中发生的所有数据变更,Mysql 集群自身的主从同步就是基于BinLog 做的。
本文主要从Binlog实时采集和离线处理Binlog还原业务数据两个方面,来介绍如何实现DB数据准确、高效地进入数仓。
基本架构

若有收获,就点个赞吧
0 人点赞
