一、基本概述

二、基本架构

Druid 总体包含以下5个类节点:
中间管理节点(middleManager node): 及时摄入实时数据,以生成Segment 数据文件 | MiddleManager 进程是执行提交的任务的工作节点。Middle Managers 将任务转发给在不同JVM中运行的Peon 进程。MiddleManager、Peon、Task 的对应关系是,每个Peon 进程一次只能运行一个Task任务,但一个MiddleManager 却可以管理多个Peon 进程。 | | —- |
历史节点(historical node): 加载已生成好的数据文件,以供数据查询。historical 节点是整个集群查询性能的核心所在,因为historical 会承担绝大部分的segment查询 | Historical 进程从Deep Storage 中下载Segment,并响应有关这些Segment 的查询请求。(这些请求来自Broker 进程)。另外,Historical 进程不处理写入请求
Historical 进程采用了无共享架构设计,它知道如何去加载和删除Segment,以及如何基于Segment 来响应查询。因此,底层的Deep Storage 无法正常工作,Historical 进程还是能针对其以及同步的Segments,正常提供查询服务 | | —- |查询节点(broker node): 接收客户端请求,并将这些查询转发给Historical 和MiddleManagers。当Brokers 从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者
- 协调节点(coordinator node):主要负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期,协调节点告诉历史节点加载新数据、卸载过期数据、复制数据和为了负载均衡移动数据。
- 统治者(overlord node): 进程监视MiddleManager 进程,并且是数据摄入Druid的控制器。他们负责将提前任务分配给MiddleManager 并协调segment 发布,包括接受、拆解、分配task、以及创建Task相关的锁,并返回task的状态。
Druid 的5个进程理论上可以被任意部署,但是为了理解与部署组织方便。 这些进程分为三类:
- Master:Coordinator,overlord 负责数据可用性和摄取
- Query:Broker and Router ,负责处理外部请求
- Data:Historical and MiddleManager ,负责实际的Ingestion 负载和数据存储
三、外部依赖
- 数据文件存储库(Deep Storage):存放生成的Segment数据文件,并提供历史服务器下载,对于单节点集群可以是本地磁盘,而对于分布式集群一般是HDFS
- 元数据(Metedata Storage): 存储Druid 集群的元数据信息,比如Segment的相关信息,一般用MySQL或PostgreSQL
- Zookeeper:
四、架构演进
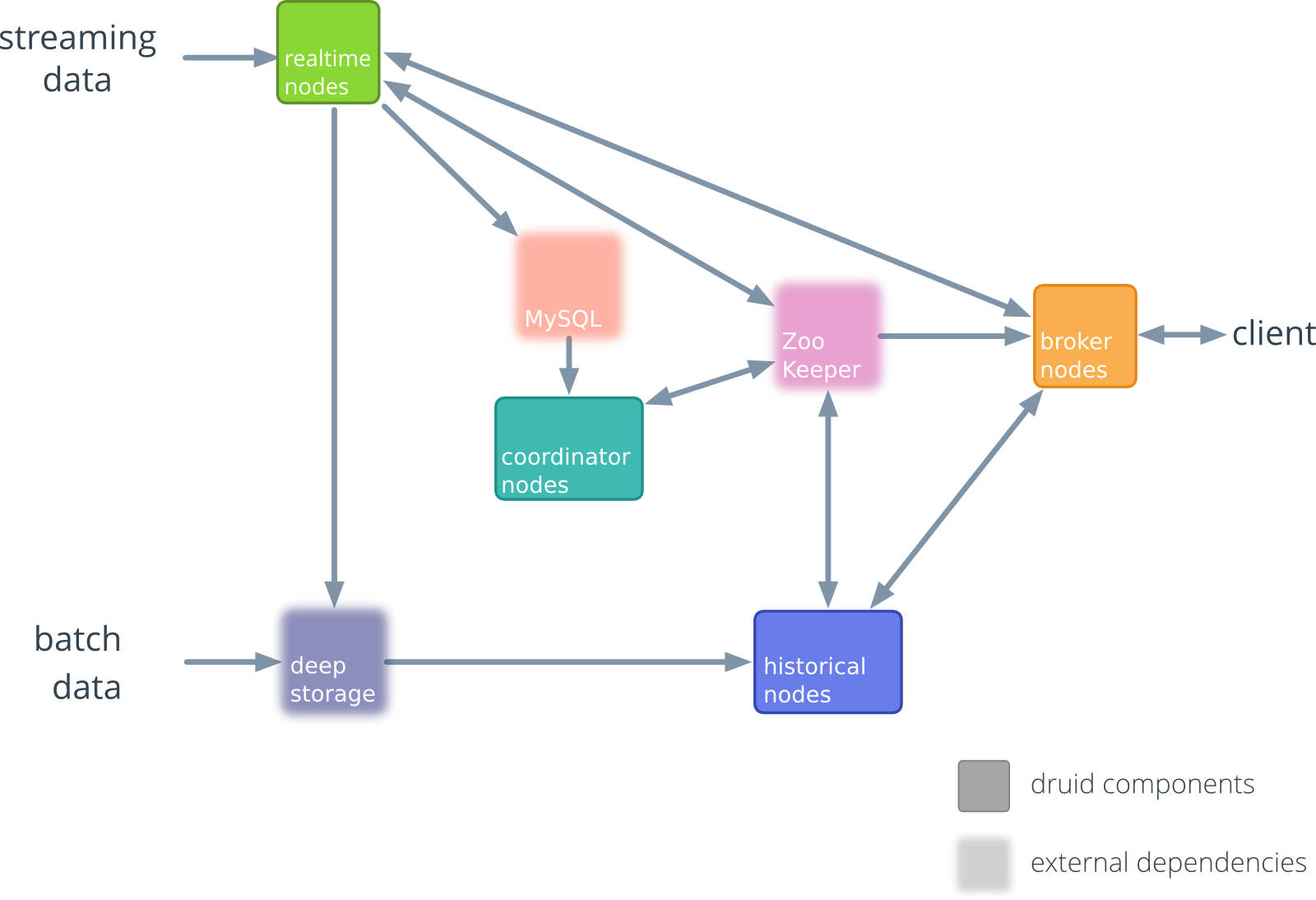
Apache Druid 初始版本架构图 ~ 0.6.0(2012~2013)
**
0.7.0 ~ 0.12.0(2013~2018)
Apache Druid 旧架构图——数据流转
**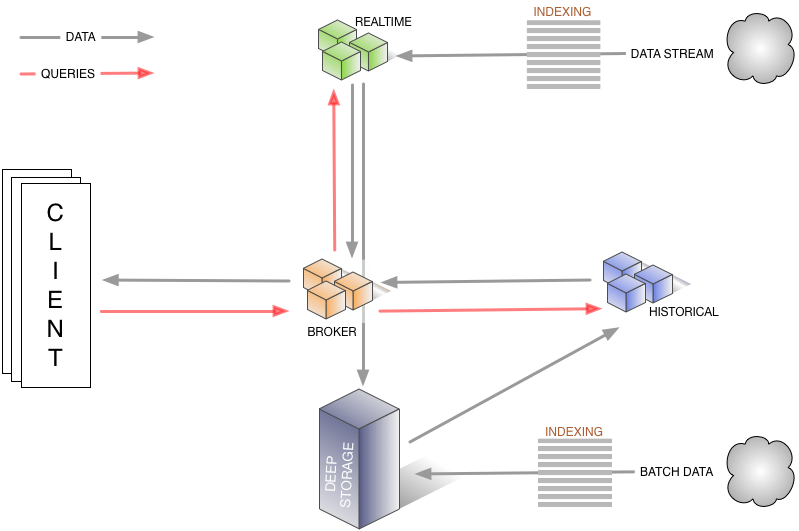
查询路径:红色箭头:①客户端向Broker发起请求,Broker会将请求路由到②实时节点和③历史节点
Druid数据流转:黑色箭头:数据源包括实时流和批量数据. ④实时流经过索引直接写到实时节点,⑤批量数据通过IndexService存储到DeepStorage,⑥再由历史节点加载. ⑦实时节点也可以将数据转存到DeepStorage

若有收获,就点个赞吧
0 人点赞
