一、介绍
在大数据分析领域,Apache Kylin 和Apache Druid 是两个普遍使用的OLAP引擎,都具有支持在超大数据上进行快速查询的能力。在一些对大数据分析依赖的企业,往往同时运行着Kylin和Druid两套系统,服务于不同的业务场景,kylin 主要支持离线数据查询,Druid 主要支持实时数据查询。
二、kylin
1. 离线
在Apache Kylin 诞生之出,主要目的是解决海量数据进行交互式数据分析的需求。数据来源主要来自数据仓库(Hive),数据主要是历史数据,而不是实时的数据。 直到(v2.6的最新版本),Apache kylin 的主要功能仍在历史数据分析领域,很难满足实时查询需求。
不能支持实时的原因:
- 数据来源, 数据来源于 Hive数据仓库中,Hive 适合对一段时间的数据进行分析查询。
- Kylin 的整个工作流程 :
- 通过ETL工具 从消息队列提取数据存放到数据仓库中有延迟
- 将数据从数据仓库中提取出来进行预计算,将结果存以Cube存储到 Hbase中
- Kylin 进行数据分析流程

- Kylin 架构图:

2. 实时 OLAP 设计
Kylin 在分析大量历史数据方面已达到一定水平。为了迈向实时OLAP, Kylin在新的版本中进行支持 实时查询
2.1 Kylin 实时OLAP 简介
在新的架构下, 根据”时间戳分区列” 将数据的查询请求分成两部分。最近时间段的查询请求将发送到实时节点,历史数据的查询请求仍将发送到Hbase 区域服务器。查询服务器需要合并两者的结果并将其返回客户端。
同时,实时节点将不断将本地数据上传到HDFS。当满足一定条件时,将通过MapReduce构建该段,从而实现实时部分数据向历史数据的转换,达到减轻实时计算节点压力的目的
2.2 实时OLAP 架构
- 在数据流方面,数据流是从 Kafka到Receiver 的,然后Receiver 上传到 HDFS,最后 MapReduce 程序合并并将Segment 重新处理为HBASE
- 在查询方面: 查询请求由服务器发出,并根据查询中出现的时间分区列将请求分发给Receiver 和HBase Region Server。

2.3 实时OLAP功能
- 摄取数据后,将立即在内存中计算出长方体。也就是说,可以立即查询数据(毫秒级的数据延迟)
- 自动数据状态管理和作业调度
- 根据查询条件,查询结果可以包括实时结果和历史结果
- 实时部分使用列式存储器和反向索引来加快数据查询速度,以减少查询延迟
- 协调器和接收器的可用性很高
2.4 实时OLAP下 Kylin的架构图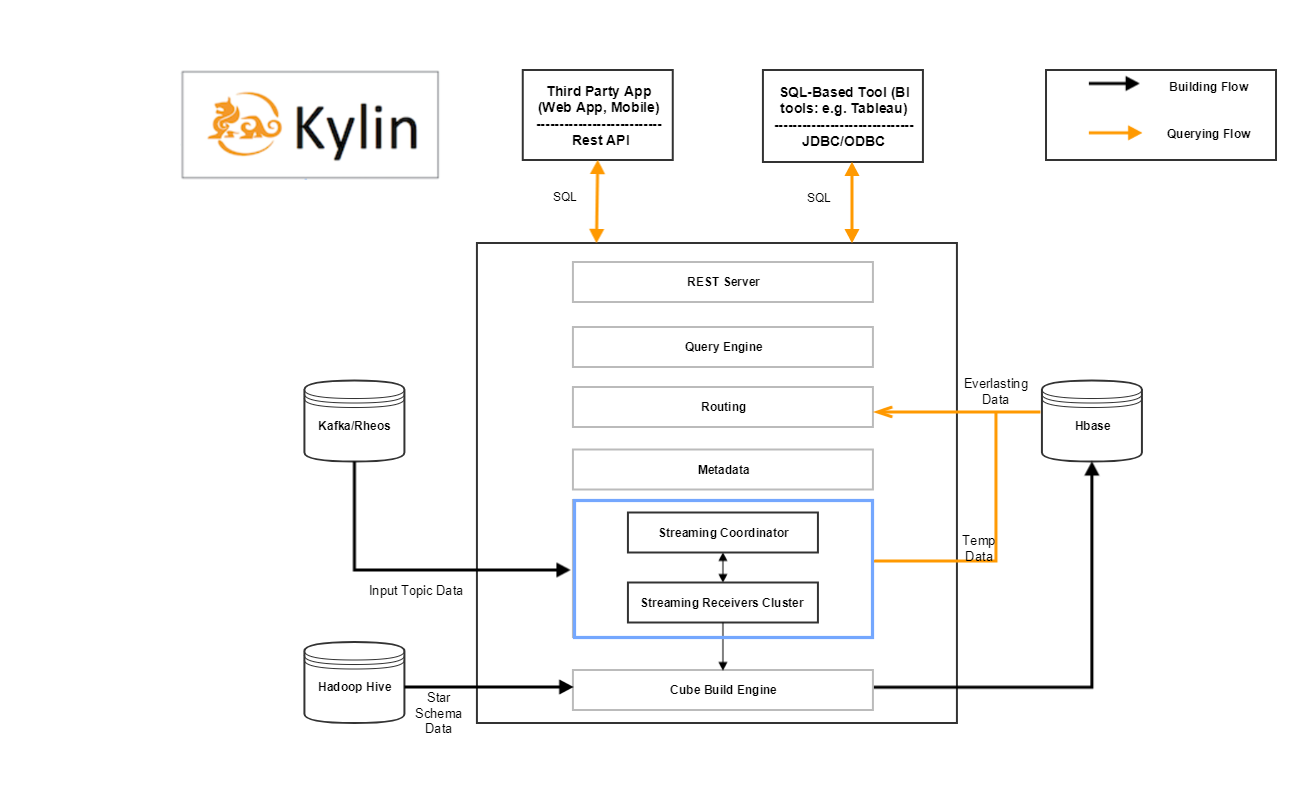
蓝色矩形区域是在当前Kylin 架构中添加的流式组件,负责从流式源中提取数据,并提供对实时数据的查询
无限制的传入流数据分为三个阶段,进入不同阶段的数据都可以理解查询
三、Druid

若有收获,就点个赞吧
0 人点赞
