4. 中文问题处理
1 问题显现
1.1 编码基础知识
- 编码发生的位置
- 系统编码,操作系统中重要的一个功能就是文件管理,操作系统中有许多文件,文件的名字可以有中文,因此选择的方式需要能满足中文,windows中文系统的编码都是GBK的。例如我们新建一个名字叫做 你好 word文档,你好两个字就自动以gbk的方式存在操作系统中,并且被管理。
- 文件编码,这里的编码是对文件的内容文件内容进行编码,对于一个文本文件通常编码方式与解码方式相对应才能正确使用文本文件。
- 网络传输过程中url编码,url编码不允许出现英文等基本字符以外的字符,服务端一般默认使用了ISO-8859-1对这些数据解码。至于为什么要有url编码原因比较复杂url编码
- 系统编码,操作系统中重要的一个功能就是文件管理,操作系统中有许多文件,文件的名字可以有中文,因此选择的方式需要能满足中文,windows中文系统的编码都是GBK的。例如我们新建一个名字叫做 你好 word文档,你好两个字就自动以gbk的方式存在操作系统中,并且被管理。
几种编码格式
- gbk、gb2312编码,满足中文的编码。
- Unicode,utf-8,万国码。
- ASCII,ISO-8859-1方式的编码。
由字符转化为二进制的过程叫编码,由二进制转化为字符的过程叫解码。
1.2 此处的问题
在get与post请求 的基础上使用中文查看效果,包括两方面
- 在login.html上输入中文,查看效果,出现了乱码效果。
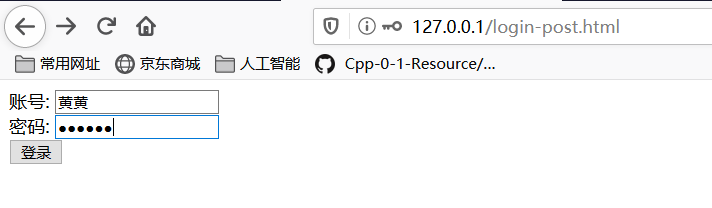
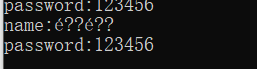
- 返回的页面上输出中文查看效果,出现了乱码。
- 在login.html上输入中文,查看效果,出现了乱码效果。
String html = null;if ("admin".equals(name) && "123456".equals(password))html = "<div style='color:green'>登陆成功</div>";elsehtml = "<div style='color:red'>登陆失败</div>";PrintWriter pw = response.getWriter();pw.println(html);
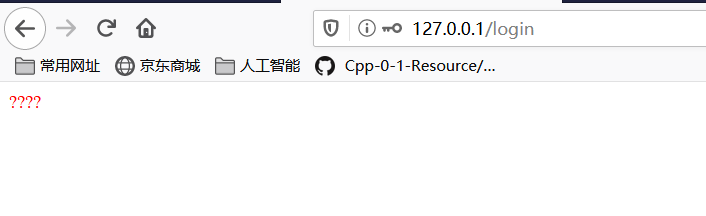
2 request中文解决
2.1 分析
- 问题显现中的第一次乱码情况就是request中的乱码。
http传输过程中客户请求传输的是字节流信息,通过ISO-8859-1方式对url进行编码,不允许出现中文,中文要对他进行编码操作。

产生错误的具体流程
黄 —-> 对应utf-8为: E9 BB 84 ——> 服务端默认使用ISO-8859-1解码成:é??乱码 本身的utf-8编码 服务端解码格式不对
2.2 解决思路1
直接修改服务端默认的解码方式
流程
黄 —-> 对应utf-8为: E9 BB 84 ——> 服务端使用utf-8的方式解码成:黄 本身的utf-8编码 服务端解码格式与原本格式对应
代码
request.setCharacterEncoding("UTF-8");String name = request.getParameter("name");
2.3 解决思路2
对乱码编码后再解码
流程
黄 —-> 对应utf-8为: E9 BB 84 ——> 服务端默认使用ISO-8859-1解码成:é??乱码—->ISO-8859-1解码 E9 BB 84字节数组—->字节数组以urf-8格式解码为字符串:黄
代码
String name = request.getParameter("name");byte[] bytes= name.getBytes("ISO-8859-1");name = new String(bytes,"UTF-8");
3 response中文解决
3.1 分析
- 问题显现中的第二次乱码情况就是response的乱码
- 原因非常简单html文档没有声明编码格式,浏览器不知道用什么方式对它进行解码。
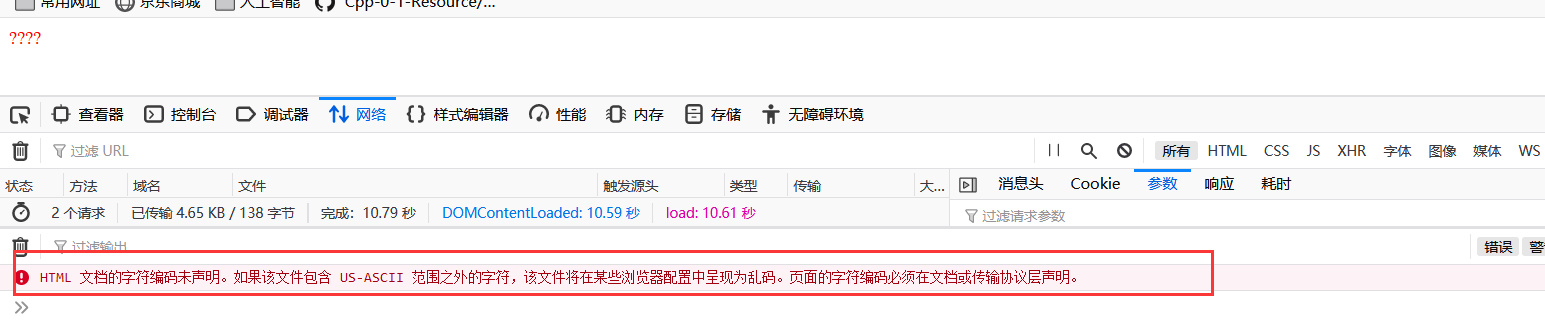
3.2 解决思路
只需要像html文档一样再前面用meta标签指明编码格式就可以了
response.setContentType("text/html; charset=UTF-8");

若有收获,就点个赞吧
0 人点赞
