wordCount &简易知识点
总体概述
MapReduce 总共分为map和reduce 一个分一个合 本次主要记录代码的含义和书写
我是写在一个文件夹里面进行的 并没有分成三个文件夹 接下来我会粘贴三部分得代码 和总体代码
总体三层
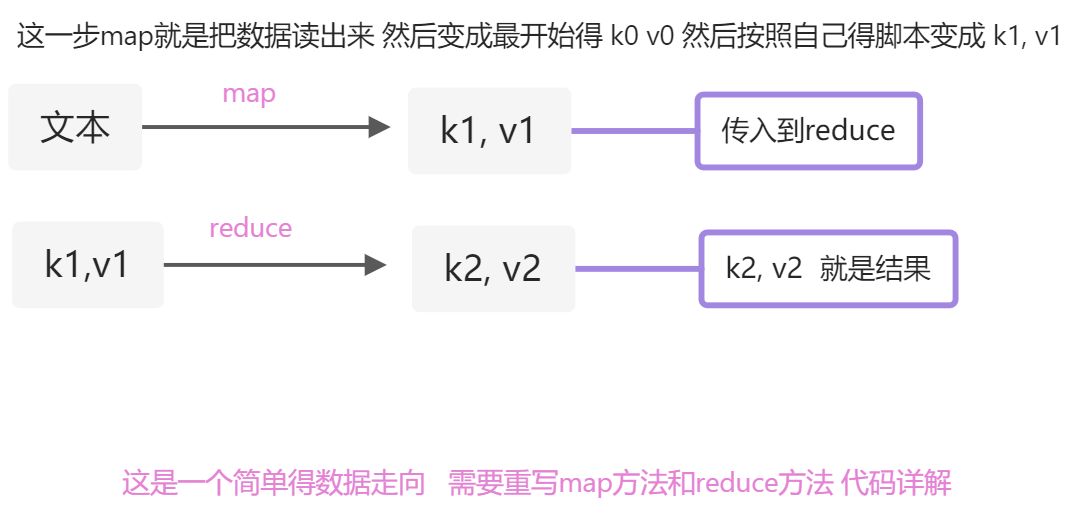
map
public static class MapperDemo extends Mapper<LongWritable,Text, Text, IntWritable>{/*** 声明MapperDemo类 继承 org.apache.hadoop.mapreduce.Mapper; 必须继承这个类* 继承这个类需要输入泛型 <KEYIN, VALUEIN, KEYOUT, VALUEOUT>* 这个案列分别是* KEYIN 编号 int or long 注意java和mapreduce有区别 不能直接给int和 Long应该是 IntWritable or IntWritable* VALUEIN 一行数据 string 应该给 Text* KEYOUT 应该是一个单词 Text* VALUEOUT 1 IntWritable*/// v2private final IntWritable one = new IntWritable(1);// 声明Text对象 用于存放key2Text text = new Text();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 声明一个分词对象 传入参数 string:一行数据(value.toString) dim: "," 按照什么分割StringTokenizer tokenizer = new StringTokenizer(value.toString(), ",");// 分割完成就是一个可迭代得 通过while循环 构建k2 v2while (tokenizer.hasMoreTokens()){// 分词出来得单词转换成Textthis.text.set(tokenizer.nextToken());// 传入上下文对象 比如 "hello, 1"context.write(text, one);}}}
reduce
public static class ReduceDemo extends Reducer<Text, IntWritable, Text, IntWritable>{/*** 此功能和map很像 继承得类变成了 org.apache.hadoop.mapreduce.Reducer;* 也需要实现泛型 <> k2 v2 k3 v3* 示例 reduce方法首先会把同一个k得value放在一起 比如hello <1,1,1,1,>最后得出得结果就是 hello, 4*/private IntWritable count = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {// 用于计数int sum = 0;// 循环迭代 获取valuefor (IntWritable value : values) {// .get() 获取方法sum += value.get();count.set(sum);}// 放入上下文中context.write(key, count);}}
job提交main
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {System.setProperty("hadoop.home.dir", "H:\\winutils\\winutils-master\\hadoop-2.6.0");// ConfigurationConfiguration conf = new Configuration();// 生成jobJob job = Job.getInstance(conf, "word count");// 指定打包类job.setJarByClass(JobMainTwo.class);// 指定map类job.setMapperClass(JobMainTwo.MapperDemo.class);// 输出得key 和 value 数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setCombinerClass(JobMainTwo.ReduceDemo.class);// 指定reduce类job.setReducerClass(JobMainTwo.ReduceDemo.class);// 输出得key 和 value 数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 读取文件的路径FileInputFormat.addInputPath(job,new Path("data/java/hello.txt"));// 输出文件得路径FileOutputFormat.setOutputPath(job,new Path("data/java/hello-put2"));// 输出运行结果System.exit(job.waitForCompletion(true)?0:1);}
数据结构
hello,world
hello,haha
hello,hadoop
完整代码
package MapReduce_one;import java.io.IOException;import java.util.Iterator;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class JobMainTwo {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {System.setProperty("hadoop.home.dir", "H:\\winutils\\winutils-master\\hadoop-2.6.0");// ConfigurationConfiguration conf = new Configuration();// 生成jobJob job = Job.getInstance(conf, "word count");// 指定打包类job.setJarByClass(JobMainTwo.class);// 指定map类job.setMapperClass(JobMainTwo.MapperDemo.class);// 输出得key 和 value 数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setCombinerClass(JobMainTwo.ReduceDemo.class);// 指定reduce类job.setReducerClass(JobMainTwo.ReduceDemo.class);// 输出得key 和 value 数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 读取文件的路径FileInputFormat.addInputPath(job,new Path("data/java/hello.txt"));// 输出文件得路径FileOutputFormat.setOutputPath(job,new Path("data/java/hello-put2"));// 输出运行结果System.exit(job.waitForCompletion(true)?0:1);}public static class MapperDemo extends Mapper<LongWritable,Text, Text, IntWritable>{/*** 声明MapperDemo类 继承 org.apache.hadoop.mapreduce.Mapper; 必须继承这个类* 继承这个类需要输入泛型 <KEYIN, VALUEIN, KEYOUT, VALUEOUT>* 这个案列分别是* KEYIN 编号 int or long 注意java和mapreduce有区别 不能直接给int和 Long 应该是 IntWritable or IntWritable* VALUEIN 一行数据 string 应该给 Text* KEYOUT 应该是一个单词 Text* VALUEOUT 1 IntWritable*/private final IntWritable one = new IntWritable(1);Text text = new Text();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer tokenizer = new StringTokenizer(value.toString(), ",");while (tokenizer.hasMoreTokens()){this.text.set(tokenizer.nextToken());context.write(text, one);}}}public static class ReduceDemo extends Reducer<Text, IntWritable, Text, IntWritable>{/*** 此功能和map很像 继承得类变成了 org.apache.hadoop.mapreduce.Reducer;* 也需要实现泛型 <> k2 v2 k3 v3* 示例 reduce方法首先会把同一个k得value放在一起 比如hello <1,1,1,1,> 最后得出得结果就是 hello, 4*/private IntWritable count = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable value : values) {sum += value.get();count.set(sum);}context.write(key, count);}}}
错误纠正
输出得文件不能重复 如果重复则需要删除 否则报错

若有收获,就点个赞吧
0 人点赞
