知识点连接第一天 如有疑惑移步我的首页
补充知识点
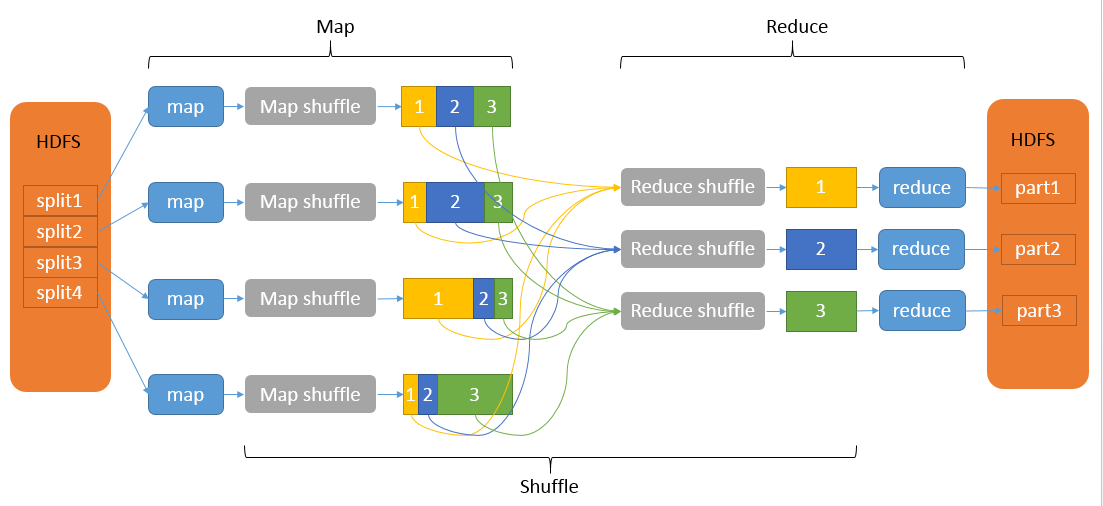
Shuffle 主要包括 四个步骤 (分区 排序 规约 分组)
Partition 分区
分区书写步骤
分区流程
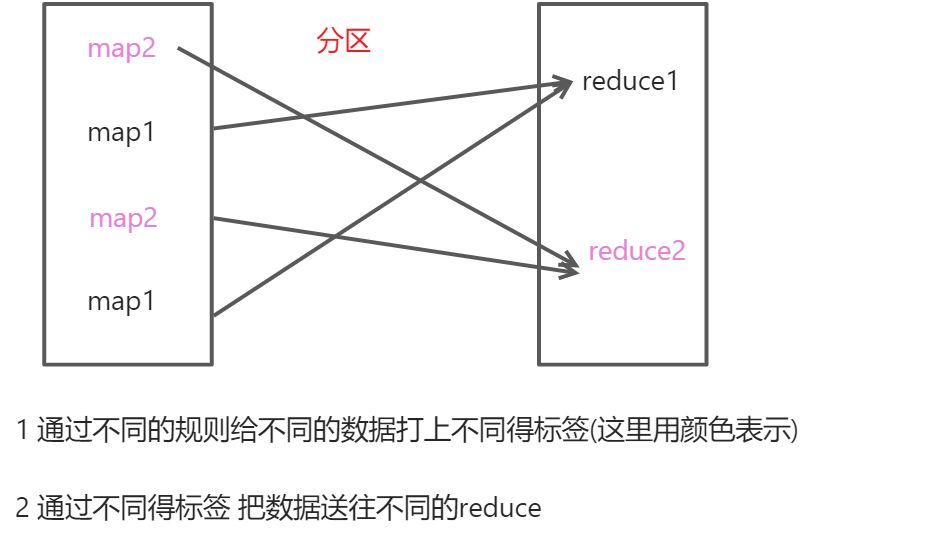
创建分区类
public static class MyPartition extends Partitioner<Text, IntWritable>{/*** 用于创建 分区规则* 继承 org.apache.hadoop.mapreduce.Partitioner;* @param text : map阶段之后 reduce阶段之前的k* @param intWritable : map阶段之后 reduce阶段之前的v* @param numPartitions* @return 返回int类型*//*** 重写getPartition方法*/@Overridepublic int getPartition(Text text, IntWritable intWritable, int numPartitions) {// 指定规则 例如 如果k是hadoop 那么 返回0 就是0分区 否则 1分区if(text.toString().equals("hadoop")){return 0;}else{return 1;}}}
让分区类能够被运用 配置
// 这个配置设置谁是分区类job.setPartitionerClass(MyPartition.class);// 设置分区reduce个数 你返回了几个变量分区数就是几 比如我0,1 就是两个分区job.setNumReduceTasks(2);
完整代码 不同项目
package MapReduce_one;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Partitioner;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class JobMainTwo {// mainpublic static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {System.setProperty("hadoop.home.dir", "H:\\winutils\\winutils-master\\hadoop-2.7.1");Configuration configuration = new Configuration();Job job = Job.getInstance(configuration, "text");job.setPartitionerClass(JobMainTwo.MyPartition.class);// 设置Reduce个数job.setReducerClass(JobMainTwo.ReduceP.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);job.setNumReduceTasks(2);job.setJarByClass(JobMainTwo.class);job.setMapperClass(JobMainTwo.MapP.class);job.setMapOutputValueClass(NullWritable.class);job.setMapOutputKeyClass(Text.class);FileInputFormat.addInputPath(job,new Path("/user/root/baoxian1117.csv"));FileOutputFormat.setOutputPath(job,new Path("/user/root/result3"));System.exit(job.waitForCompletion(true)?0:1);}// mappublic static class MapP extends Mapper<LongWritable, Text, Text, NullWritable>{@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {context.write(value, NullWritable.get());}}// partitionpublic static class MyPartition extends Partitioner<Text, NullWritable>{@Overridepublic int getPartition(Text text, NullWritable nullWritable, int numPartitions) {String[] split = text.toString().split(",");if (Integer.parseInt(split[0])>200){return 0;}else {return 1;}}}// reducepublic static class ReduceP extends Reducer<Text, NullWritable, Text, NullWritable>{@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {context.write(key, NullWritable.get());}}}
问题和注意事项
- 在本地运行配置得环境可能不支持分区操作 如果可以当然不可以 如果不可以 可以尝试先选择去yarn集群跑一下任务看是否能够正常分区
- 注意设置分区数目

若有收获,就点个赞吧
0 人点赞
