序列化和反序列化简单介绍
- 序列化(Serialization)是指把结构化对象转化为字节流
反序列化是序列化得过程 把字节流转换为结构化对象 具体怎么转换我们不深究
项目过程
项目需求
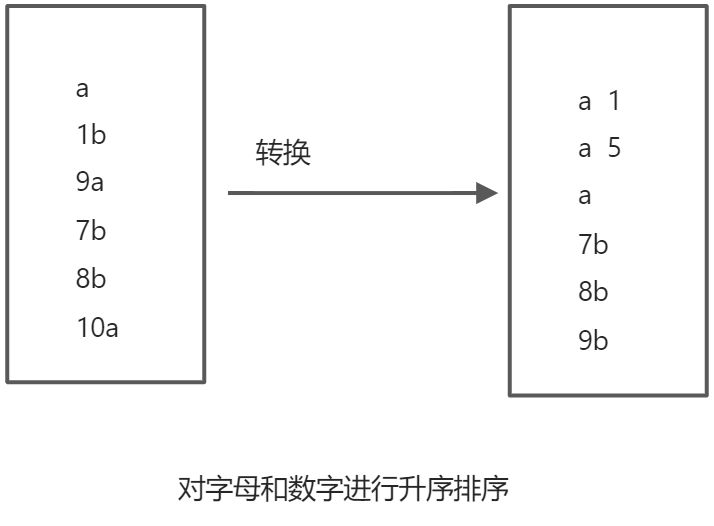
代码讲解和序列化反序列化得要求&排序
第一步创建一个类继承WritableComparable接口
// 传入得泛型就是本身public static class SortBean implements WritableComparable<SortBean>{}
第二步重写接口得抽象方法
```java public static class SortBean implements WritableComparable
{ private String word; // 单词private int num;// 数字public void setWord(String word) {this.word = word;}public void setNum(int num) {this.num = num;}public String getWord() {return word;}public int getNum() {return num;}@Overridepublic String toString() {// 重写这个方法得含义是让输出到文件的对象 toString()更好看return word + "\t" + num ;}@Overridepublic int compareTo(SortBean o) {// 默认是升序 如果要相反 则取反返回即可// 第一列按照字母排序// 第二列按照数字排列int i = this.word.compareTo(o.word);if(i == 0){return this.num - o.num;}return i;
}
// 实现序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(getWord());
dataOutput.writeInt(getNum());
}
// 实现反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
setWord(dataInput.readUTF());
setNum(dataInput.readInt());
}
}
<a name="f3KSR"></a>
## 第三步 写map reduce代码
```java
// map关键代码
//泛型<行偏移量, 数据, 序列化排序反序列化类, 空值>
<LongWritable, Text, SortBean, NullWritable>
// 接下来按照空行切割然后初始化SortBean得对象传入上下文对象
String[] split = value.toString().split(" ");
SortBean sortBean_ = new SortBean();
// 初始化完毕后记得更改对象的值
context.write(sortBean_, NullWritable.get());
// 第一种 也是最简单的一种
// 泛型
<SortBean, NullWritable, SortBean, NullWritable>
// 直接写入上下文对象
context.write(key, NullWritable.get());
// 为什么写出一个对象 就能得到我们要的结果样子
// 因为重写了toString()方法
// 第一种 也是最简单的一种
// 泛型
<SortBean, NullWritable, Text, IntWritable>
// 这种需要把对象得值取出来 转换 传入context
// context.write(text, intWritable);
因为排序得对象用在整个流程中所不需要指定排序类
package MapReduce_one;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class JobMainThree {
public static void deleteFile(Path s) throws IOException {
FileSystem fileSystem = FileSystem.get(new Configuration());
if(fileSystem.exists(s)){
fileSystem.delete(s, true);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "sortBy");
job.setJarByClass(JobMainThree.class);
job.setMapperClass(JobMainThree.MapThree.class);
job.setMapOutputKeyClass(SortBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(JobMainThree.ReduceThree.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path path = new Path("data/result2");
deleteFile(path);
FileInputFormat.addInputPath(job,new Path("data/data2.txt"));
FileOutputFormat.setOutputPath(job,path);
System.exit(job.waitForCompletion(true)?0:1);
}
public static class SortBean implements WritableComparable<SortBean>{
public void setWord(String word) {
this.word = word;
}
public void setNum(int num) {
this.num = num;
}
private String word;
private int num;
public String getWord() {
return word;
}
public int getNum() {
return num;
}
@Override
public String toString() {
return word + "\tddddd" + num ;
}
@Override
public int compareTo(SortBean o) {
// 默认是升序 如果要相反 则取反返回即可
// 第一列按照字母排序
// 第二列按照数字排列
int i = this.word.compareTo(o.word);
if(i == 0){
return this.num - o.num;
}
return i;
}
// 实现序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(getWord());
dataOutput.writeInt(getNum());
}
// 实现反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
setWord(dataInput.readUTF());
setNum(dataInput.readInt());
}
}
public static class MapThree extends Mapper<LongWritable, Text, SortBean, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, SortBean, NullWritable>.Context context) throws IOException, InterruptedException {
// 复习计数器
context.getCounter("MySort", "mapRow").increment(1l);
// 分割
String[] split = value.toString().split(" ");
String word = split[0];
int num = Integer.parseInt(split[1]);
SortBean sortBean_ = new SortBean();
sortBean_.setWord(word);
sortBean_.setNum(num);
// 传递参数
context.write(sortBean_, NullWritable.get());
}
}
public static class ReduceThree extends Reducer<SortBean, NullWritable, SortBean, NullWritable> {
@Override
protected void reduce(SortBean key, Iterable<NullWritable> values, Reducer<SortBean, NullWritable, SortBean, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
// public static class ReduceThree extends Reducer<SortBean, NullWritable, Text, IntWritable> {
// Text text = new Text();
// IntWritable intWritable = new IntWritable();
//
// @Override
// protected void reduce(SortBean key, Iterable<NullWritable> values, Reducer<SortBean, NullWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// text.set(key.getWord());
// intWritable.set(key.getNum());
// context.write(text, intWritable);
// }
// }
}
项目过程中碰到的问题
继承WritableComparable接口得类 得构造方法要为kong

若有收获,就点个赞吧
0 人点赞
