https://google.github.io/mediapipe/solutions/knift
KNIFT(Keypoint Neural Invariant Feature Transform, 基于神经网络的关键点不变特征转换),一种类似于 SIFT 或 ORB 的通用局部特征描述符。
同样地,KNIFT 还是代表局部图块的紧凑型向量,对均匀的缩放、方向和照明变化方面均保持恒定。然而,与采用启发式算法的 SIFT 或 ORB 不同,KNIFT 是一种嵌入向量,根据周围视频帧中提取的大量局部对应图块直接进行学习。这种数据驱动方法会以隐式方式对嵌入向量中遇到的复杂的真实空间转换和照明变化作出编码。
因此,KNIFT 特征描述符看起来会更加稳定,其不仅能在消除仿射失真方面表现良好,还可在某种程度上减轻透视失真等问题。
In Machine Learning, loosely speaking, training an embedding means finding a mapping that can translate a high dimensional vector, such as an image patch, to a relatively lower dimensional vector, such as a feature descriptor. Ideally, this mapping should have the following property: image patches around a real-world point should have the same or very similar descriptors across different views or illumination changes. We have found real world videos a good source of such corresponding image patches as training data (See Figure 3 and 4) and we use the well-established Triplet Loss (see Figure 2) to train such an embedding. Each triplet consists of an anchor (denoted by a), a positive (p), and a negative (n) feature vector extracted from the corresponding image patches, and d() denotes the Euclidean distance in the feature space.
Training Data
The training triplets are extracted from all ~1500 video clips in the publicly available YouTube UGC Dataset. We first use an existing heuristically-engineered local feature detector to detect keypoints and compute the affine transform between two frames with a high accuracy (see Figure 4). Then we use this correspondence to find keypoint pairs and extract the patches around these keypoints. Note that the newly identified keypoints may include those that were detected but rejected by geometric verification in the first step. For each pair of matched patches, we randomly apply some form of data augmentation (e.g. random rotation or brightness adjustment) to construct the anchor-positive pair. Finally, we randomly pick an arbitrary patch from another video as the negative to finish the construction of this triplet (see Figure 5).
Hard-negative Triplet Mining
To improve model quality, we use the same hard-negative triplet mining method used by FaceNet training. We first train a base model with randomly selected triplets. Then we implement a pipeline that uses the base model to find semi-hard-negative samples
(d(a,p) < d(a,n) < d(a,p)+margin)
for each anchor-positive pair (Figure 6). After mixing the randomly selected triplets and hard-negative triplets, we re-train the model with this improved data.
Figure 6: (Top to bottom) Anchor, positive and semi-hard negative patches.
Quality-wise, we compare the average number of keypoints matched by KNIFT and by ORB (OpenCV implementation) respectively on an in-house benchmark (Table 2). There are many publicly available image matching benchmarks, e.g. 2020 Image Matching Benchmark, but most of them focus on matching landmarks across large perspective changes in relatively high resolution images, and the tasks often require computing thousands of keypoints. In contrast, since we designed KNIFT for matching objects in large scale (i.e. billions of images) online image retrieval tasks, we devised our benchmark to focus on low cost and high precision driven use cases, i.e. 100-200 keypoints computed per image and only ~10 matching keypoints needed for reliably determining a match. In addition, to illustrate the fine-grained performance characteristics of a feature descriptor, we divide and categorize the benchmark set by object types (e.g. 2D planar surface) and image pair relations (e.g. large size difference). In table 2, we compare the average number of keypoints matched by KNIFT and by ORB respectively in each category, based on the same 200 keypoint locations detected in each image by the oFast detector that comes with the ORB implementation in OpenCV.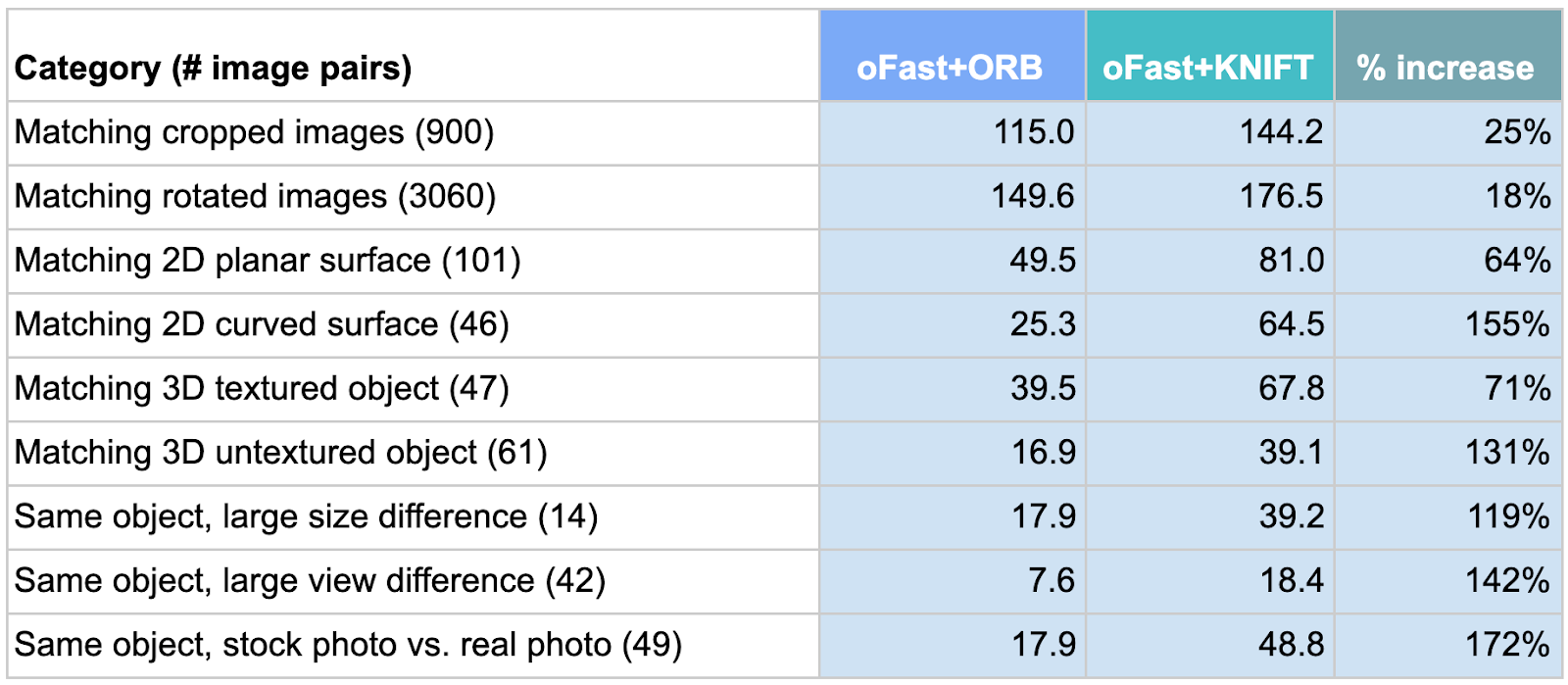
KNIFT-based Template Matching in MediaPipe
There are 3 major components in the template-matching MediaPipe graph shown below:
- FeatureDetectorCalculator: a calculator 计算器 that consumes image frames and performs OpenCV oFast detector on the input image and outputs keypoint locations. Moreover, this calculator is also responsible for cropping patches around each keypoint with rotation and scale info and stacking them into a vector for the downstream calculator to process.
- 一种计算器,它使用图像帧并在输入图像上执行OpenCV oFast检测器并输出关键点位置。此外,该计算器还负责使用旋转和缩放信息在每个关键点周围裁剪补丁,并将它们堆叠成矢量以供下游计算器处理。
- TfLiteInferenceCalculator with KNIFT model: a calculator that loads the KNIFT tflite model and performs model inference. The input tensor shape is (200, 32, 32, 1), indicating 200 32x32 local patches. The output tensor shape is (200, 40), indicating 200 40-dimensional feature descriptors. By default, the calculator runs the TFLite XNNPACK delegate, but users have the option to select the regular CPU delegate to run at a reduced speed.
- 加载KNIFT tflite模型并执行模型推理的计算器。输入张量形状为 (200, 32, 32, 1),表示 200 个 32x32 局部面片。输出张量形状为 (200, 40),表示 200 个 40 维特征描述符。默认情况下,计算器运行 TFLite XNNPACK 委托,但用户可以选择常规 CPU 委托以较低的速度运行。
- BoxDetectorCalculator: a calculator that takes pre-computed keypoint locations and KNIFT descriptors and performs feature matching between the current frame and multiple template images. The output of this calculator is a list of TimedBoxProto, which contains the unique id and location of each box as a quadrilateral on the image. Aside from the classic homography RANSAC algorithm, we also apply a perspective transform verification step to ensure that the output quadrilateral does not result in too much skew or a weird shape.
- 一个计算器,采用预先计算的关键点位置和KNIFT描述符,并在当前帧和多个模板图像之间执行特征匹配。此计算器的输出是TimedBoxProto的列表,其中包含每个框的唯一ID和位置,作为图像上的四边形。除了经典的单调RANSAC算法外,我们还应用透视变换验证步骤,以确保输出四边形不会导致太多的偏斜或奇怪的形状。

若有收获,就点个赞吧
0 人点赞
