当我第一次了解到Rust时,我发现Rust是这样一门略显奇葩的语言,它在设计上遗留着传统静态类型语言的血脉,而语法上则更灵活多变,最后还接纳了函数式编程的模式,但是它没有成为缝合怪,就目前来说,Rust的确实现了它所宣传的feature,然而你懂的,语言不是万灵药,更多的feature意味着Rustaceans需要考虑更多的编程范式,而更多的范式带来的是开发速度和可读性的降低。
我觉得,Rust的可读性会随着你不断地熟悉而逐步提升,而且它的语法不算难理解,尤其是在大部分Rustaceans通常早已学习过其他高级语言的情况下,Rust只是增删了一些特例和语法糖。
更令人欣慰的是,Rust对于依赖管理和自动测试具备良好的集成,而且默认的文档生成工具也是可用性极高。作为对比,下图展示了Rust文档和jdk文档,虽然我平常主要写Java,但是我第一眼就喜欢上了Rust文档Intuitive的风格。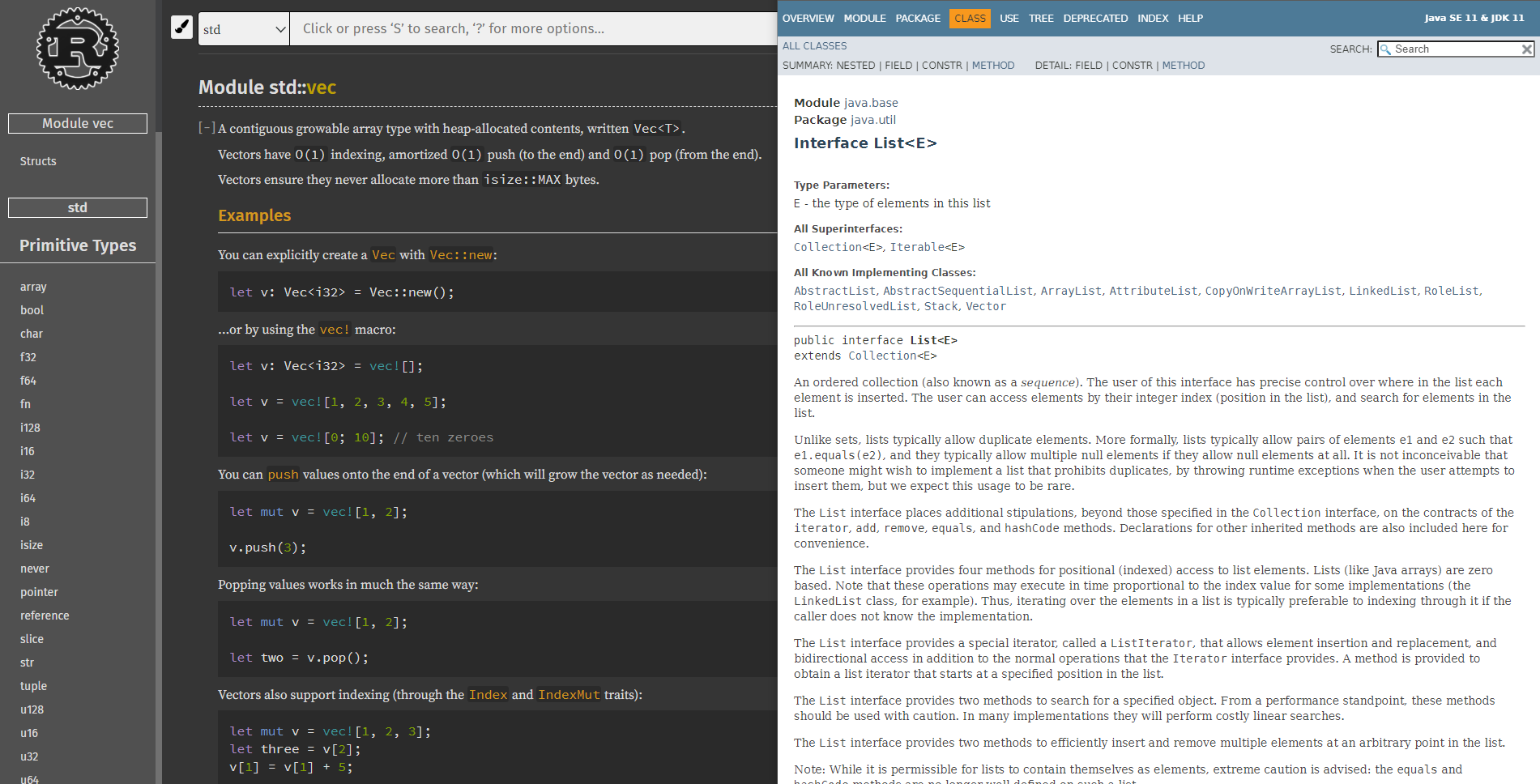
Rust doc和Java(JDK11) doc
不要误会,我知道对于Java来说有很多工具来完成文档生成的任务,其中有一些也集成了自动化测试功能。这里的文档比较并不是说Rust要比Java优越,只是在辅助说明Rust集成了很多新颖的设计理念。
然而Rust的确是没有Garbage Collector的。它更倾向于在编译时发现错误,然后跟你说“哥们你这代码在我这里行不通,你得按我的范式来编程”。接着你可以按照Rust给出的提示来修改,这样你的时间相当于花在修复开发环境下的bug而不是等上线之后再处理可能出现的各种异常。
但是这样无疑对于刚开始入门的开发者是个负担,因此想要成为一位合格的Rustacean,你需要首先在Rust的编程范式中存活。
注意,Rust在很多地方(以及keyword和一些方法名)使用了新鲜的名词来表述,像是mut,borrow,move,ownership,如果你对其他高级语言足够熟悉,你会发现这些大都是“新瓶装旧酒”。我选择按照自己的喜好和理解翻译。
理解“mut”
Rust中的变量默认是不可变的,不管是“标量”(scalar)还是“复合”(compound)类型,他们默认不可变。
你很快就会意识到,“标量”指的就是很多语言中的primitive,它存在栈上。“复合”则是笼统地指一些引用类型,一般分布在堆内存上。
所以,下面的做法是不对的,因为在Rust中,这其实是在告诉编译器我要改变a:
fn main(){let a = 990;a = 991;println!("a={} is immutable, you shouldn't see this line.", a);}
要想改变a,最直接的做法就是向编译器说,我需要a成为可变(mut)的:
fn main(){let mut a = 990;a = 991;a = a + 1;println!("a={} is immutable, you shouldn't see this line.", a);}
mut 就是mutatable的缩写。Rust很多地方喜欢用缩写版的关键字,这会降低可读性,提升开发效率。
变量遮盖(Shadowing)
这里讨论的并不是局部变量覆盖全局变量。
“遮盖”是Rust的一个feature,在了解到变量默认是不可修改的时候,有其他高级语言开发经历的人应该意识到,虽然很多语言也表示其变量不可修改,但在使用时却看起来像是可以随意赋值,比如在Java中,你可以很随意地将一个字符串重新赋值:
class ImmutableCase{public static void main(String[] args){String someString = "Rust is bad, Java is good.";someString = "Java is dumb, Rust is neat.";System.out.println(someString);}}
这段代码并不会出错,但Java程序员知道,String虽然是包装类,但他是不可变的, 这里能够赋值成功只是因为,我们新开辟了一块字符串常量池空间并把”Java is dumb, Rust is neat.“放入其中,然后再将someString引用指向这段区域,而原来字串并没有改变。
在Rust中,你真的没有办法改变/重新赋值immutable,但你可以选择遮盖变量,这就像是”身份盗用“,被盗用的变量在盗用行为发生后应该被舍弃。
而盗用的途径,就是使用 let 。
let a = "DUST";let a = "RUST";
请注意,因为是”盗用“,这两个a是李逵和李鬼的关系,在编译时,编译器会提示你前一个变量并未使用:
warning: unused variable: `a`--> src/main.rs:2:9|2 | let a = "BAD";| ^ help: if this is intentional, prefix it with an underscore: `_a`|= note: `#[warn(unused_variables)]` on by defaultwarning: 1 warning emittedFinished dev [unoptimized + debuginfo] target(s) in 0.18sRunning `target/debug/ownership_playground`GOOD
所以第二个a作为盗用者被输出了。
如果你使用 let a = 10; let a = a + 1; 这样的表达,编译器会认为前一个a已被使用,因此不会warn。
变量类型替换
- 使用mut修饰的变量的mutable仅限于同类型的值,因为Rust是静态类型的语言。
- 使用”遮盖/盗用“可以改变变量的类型,因为盗用者可以是任何身份。 ```rust let mut spaces = “ “; spaces = spaces.len(); // Wrong!
let king = 1; let king = “ONE”; // Right!
<a name="VSmMz"></a># 数据类型再次说明,Rust是静态类型的语言,尽管它存在类型推断,但也仅限于此。<br />好的编程范式是在类型推断不确定的时候,手动指明你想要的类型:```rustlet number: u32 = "996".parse().expect("Not a number!");
因为expect有两种情况:
- parse通过返回确定的值(Result
OK) - 返回错误提示(Result
Err,返回字符串”Not a number“)
标量Scalar
对应很多语言中的Primitive Value。
Rust的Integer默认是32-bit,但是也可以使用其他位数。
| Rust-Integer* | |||
|---|---|---|---|
| Length | Signed | Unsigned | |
| 8-bit | i8 | u8 | |
| 16-bit | i16 | u16 | |
| 32-bit | i32 | u32 | |
| 64-bit | i64 | u64 | |
| 128-bit | i128 | u128 | |
| arch* | isize | usize |
arch: 根据平台位数决定。比如在x86-64平台上就是64-bit。 Rust-integer: 对于Signed数据,范围是
, 对于Usigned数据则是

Rust的数字格式规范如下:
- 使用后缀表示数字长度:
128u8或者128i16 - 使用前缀表示数制:
0xff,0o77,0b1100_1100分别是十六进制,八进制,二进制数。十进制是默认。 - 使用
_来提高可读性: 对于Decimal数28701390来说,应写成:28_701_390。这里_的作用和通常货币表示中的,类似。对于二进制数11110000来说,应写成0b1111_0000。位数不足不必附加。
此外,浮点数包括:
f32f64(默认)
布尔类型: bool , 仅含 true 和 false , 他们不与 1 和 0 等价。
字符类型: char ,4-bit数据,可以用来表示Unicode字符。
复合Compound
并不能说复合类型等价于引用类型, 因为”引用“是一个单独的概念,在Rust中最好不要将其随意与复合类型混淆。
复合代表的是一组数据的集中表示。
元组Tuple
类似于Python3中的tuple,它表示了一组数据的集合,这些数据不一定需要是相同的类型。
Tuple本身容量是定长的,定义后就不能改变(你使用 mut 可以改变其内部元素值,但不能增删元素 )。
let mut tup:(i16, f32) = (1, 0.88);let tup_copy = tup;let (x, y) = tup;println!("Direction:({},{})", x, y);println!("Also Direction:({},{})", tup.0, tup.1);println!("Also(cpoy) Direction:({},{})", tup_copy.0, tup_copy.1);tup.0 = 0b1001_0001_1000;tup.1 = 98f32;println!("Also Direction:({},{})", tup.0, tup.1);println!("Also(cpoy) Direction:{:?}", ..tup_copy);println!("So the copy of a tuple is deep copy,and you can assign a mutable tuple to a immutable one!");
数组Array
Rust的数组同样是定长的。数组元素需要保持类型一致。
使用例子如下:
let nums = [9527, 9981, 300000];let days:[&str; 7] = ["Monday", "Tuesday", "Wednessday", "Thursday", "Friday", "Satuarday", "Sunday"];let empty_arr:[u8; 0] = [];let same_character_arr = ["🦀️🐎️"; 3];println!("\nNumber Array: {:?}(length:{})", nums, nums.len());println!("Days: {:?}, the second day is:{}", days, days[1]);println!("Empty Array must announce its element type explicitly!:{:?}", empty_arr);println!("A trick can generate array like this: {:?}", same_character_arr);
注意输出:
Number Array: [9527, 9981, 300000](length:3)Days: ["Monday", "Tuesday", "Wednessday", "Thursday", "Friday", "Satuarday", "Sunday"], the second day is:TuesdayEmpty Array must announce its element type explicitly!:[]A trick can generate array like this: ["🦀\u{fe0f}🐎\u{fe0f}", "🦀\u{fe0f}🐎\u{fe0f}", "🦀\u{fe0f}🐎\u{fe0f}"]
另外,虽然Rust编译器很智能,但是他不会帮你检测数组越界(Index out of bounds)这种问题,这种属于运行时错误,应该由开发者进行妥当处理。
对于数组的迭代,方式不一,参考分支和循环。
函数Function
首先注意区分函数(Function)和方法(Method):
- 函数是独立的个体,在同一.rs文件中一般能直接以函数名调用。
main是函数,也是程序入口。 - 方法是绑定到结构(Struct)上的,方法的使用离不开结构或结构的实例。
除此之外,还要区分两个概念,Statement和Expression:
- Statement不返回值,Expression返回值。
- 在Rust中,函数是一种Statement。
- 可以使用
{}作为Expression的Wrapper,但其中可以存在Statement。 - Expression可以作为Statement的一部分。
所以, let x = 78; 是一条Statement。fn main() 是一条Statement(指的是函数定义部分)。x+1 是Expression。调用函数是Expression,调用宏(Macro)是Expression。
由于赋值语句是Statement,不返回值,所以像 let x=y=7 这样的写法在Rust中是错误的。
因此,函数如果需要返回内容,它返回的就是其中的一条Expression。
函数的几个形式:
fn foo(){println!("Function with no return value nor any parameters.");}fn bar(num:i32, desc:&str){println!("Function with parameters while without return value.");println!("{},{}",num, desc);}fn foo_v(num:f32) -> f32{let temp:f32 = (num * num) / 2.;println!("Function with parameter and a return value(notice there is no ';' behind temp)");temp}fn main(){let number = foo_v(3.1);let number_processed = {let number = foo_v(number);number + 1};// The new scopes {} means that is a expression}
函数和方法都是snake case的。
分支和循环
IF..ELSE
分支可以通过 if Expression完成。
let cond:bool = false;let number = if cond {31.4} else {3.14};println!("Number is {}", number);if number >= 30. && number <= 40.{println!("Number is between [30., 40.]");}else if cond || number > 0.{println!("Number is smaller than 30. but still positive");}else{println!("Number is negative");}
注意:如果你要使用上面代码中line: 2所示的行内条件判断,务必保证各条件分支返回的类型是一致的,这不仅是类型推断的一部分,更是保证代码确定性的举措。如果你一定要达到根据条件改变类型的“效果”,考虑使用遮盖(Shadowing)。
MATCH
另类的switch…case…
match 可以看作是Rust中的switch,但 match 的特性和switch并不相同。
enum Coin{Penny,Nickel,Dime,Quarter(UsState),}#[derive(Debug)]enum UsState{Alabama,Alaska,// --snip--}fn value_in_cents(coin: Coin) -> u8{match coin{Coin::Penny => 1,Coin:: Nickel => 5,Coin::Dime => 10,Coin::Quarter(state) => {println!("State quarter from {:?}.", state);25}}}fn main(){value_in_cents(Coin::Quarter(UsState::Alaska));}
这是重新组织后的例子,用来判断美分枚举的具体值。
match 的关键:
match一般用于匹配枚举分支,也可以用于match其他类型,但match只能同时匹配一种类型。- 如果枚举中的成员具有类型,
match可以在arm(相当于case)中添加形式参数作为对应的变量 - arm是排他的,满足其中一条arm执行完arm中的表达式后match就会退出。
- 必须要兼顾所有的arm可能性。(Matches are exhaustive)
- 可以使用
_代表任意未被匹配的arm,相当于default,通常以_ => ()的形式出现(()表示返回一个unit,无事发生)。 _会吞没其他arm,因此虽然编译器不会强制你把_放在最后一条arm,但语义上来讲,_代表的arm是默认分支。IF..LET
当你只需要match中的一种情况但不希望使用match冗长的结构的时候,if let是你需要的手段。
比如:
可以写成:let some_u8_val = Some(0u8);println!();match some_u8_val {Some(999) => println!("I only want 999!"),_ => println!("Not 999!"),}
if let Some(999) = some_u8_val{println!("I only want 999!");}else{println!("Not 999!");}
虽然官方教程说
if let更简洁,但在由else的情况下,相比match并未减少书写量,反而还降低了可读性。 因为 if let 后的分支需要=来说明变量,这种用法我觉得实在是一种足够奇葩的语法糖了。
LOOP
创造一个无限的循环…
let mut number = 0;loop{number = number + 1;if number % 1000 == 0{println!("{}", number);}}println!("Looped {} times", number);
Rust会表示你在运行时出现Integer Overflow:
2147480000214748100021474820002147483000thread 'main' panicked at 'attempt to add with overflow', src/main.rs:85:18note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
此处并不是调用栈溢出,而是i32溢出。因为
添加 break 可以进行提前退出。
WHILE
带条件的 loop 。
let mut number = 20;while number >= 0{number -= 1;}println!("Number now: {}", number);
FOR
增强版的Iteration,对于容器和数组都很实用。
let arr = [number; 8];for item in arr.iter() {print!("{} ", item);}println!();let arr = [1, 9, 7, 4, 0, 8, 1, 3];for (index, item) in arr.iter().enumerate(){println!("Item {} in {}", item, index);}println!();// [0, n)区间的连续数字,跨度为1, rev()表示逆序区间,如果不掉用rev(),可以直接使用0..arr.len()for index in (0..arr.len()).rev(){print!("{} ", arr[index]);}// Output:// -1 -1 -1 -1 -1 -1 -1 -1// Item 1 in 0// Item 9 in 1// Item 7 in 2// Item 4 in 3// Item 0 in 4// Item 8 in 5// Item 1 in 6// Item 3 in 7// 1 9 7 4 0 8 1 3
for一般需要配合迭代器使用,数组可以迭代,提供了多种迭代方式。这里只是基本用法。
结构体Struct
此处仅为介绍和浅析
结构体相当于C++和Java中的“类”,但他具有独特的书写格式和继承特性。
本质上,结构体是为了玩面向接口编程那一套。
结构体的使用还需要结合所有权Ownership来讨论,但这里先不介绍所有权(实际上所有权应该单独列出一节)。
定义一个结构体只需要使用 struct 关键字,为结构体添加方法只需要在定义完结构体后增加 impl 关键字。
结构体的定义和结构体方法的定义可以是分开的。
实际例子(这个例子使用到了下面枚举的知识):
#[derive(Debug)]enum Race{WHITE(u8),BLACK(u8),YELLOW(u8),UNKNOWN(String),}#[derive(Debug)]enum Gender{DUDE,GAL,WHATEVER,}#[derive(Debug)]struct Person{race: Race,name: String,age: u8,gender: Gender,}impl Person{fn reveal_gender(&self){self.gender.reveal();}fn reveal_race(&self){self.race.reval();}}impl Gender{fn reveal(&self){println!("I am {:?}", self);}}impl Race{fn reval(&self){println!("I am {:?}", self);}}let someone = Person{race: Race::WHITE(0),name: String::from("Karen"),age: 37,gender: Gender::WHATEVER,};println!();println!("{:?}", someone);someone.reveal_gender();someone.reveal_race();
你会得到下面的输出(注意类型的输出是在Debug控制的):
Person { race: WHITE(0), name: "Karen", age: 37, gender: WHATEVER }I am WHATEVERI am WHITE(0)
枚举Enum
我并没有把Enum列到数据类型的子目录下,它是一类特殊的结构体。同时这样也和“The Book”的编排方式呼应。
枚举的作用十分重要,当你需要一些同类却不同形的数据时,使用枚举要比使用继承更好。
枚举是一种高层次的抽象。
Rust的enum使用起来总算不怎么奇葩了:
enum Gender{DUDE,GAL,WHATEVER(String), // 可选的类型注解}
枚举可以制定的类型可以是其他枚举,或者匿名的结构体,或是基本的标量或者复合类型。
枚举可以实现方法。就像结构体一样。
impl Gender{fn reveal(&self){println!("Revealing me...");}}let someone = Gender::WHATEVER(String::from("Lesbian"))
枚举的内部成员是Camle Case的。
枚举案例: Option
Option 可以看作是一个枚举+泛型,它能表示一个值的存在性。
在Rust中,没有null的概念,但存在名为
None的枚举值。Option出现时,意味着有可能存在None,需要对此进行控制。使用match是一个很好的选择。
enum Option<T>{Some(T),None,}
也就是说,Option是对普通变量的一层封装,因为如果直接使用到某个变量,Rust会保证其不为空/空指针,而如果开发者需要一个表示未定的值,就需要使用Option。这实际上是和程序的逻辑相绑定的。
使用Option中的值需要解包装(unwrap),实际上 Option 提供了 unwrap() 方法,来快速地获得 Some 或 None 。此外需要注意的是,由于 Option 被定义为泛型的格式,你可以对任何 Option 进行嵌套,比如使用 Some(Some(34u8)) 这样的值是完全合理的。
关于Option的更多用法,你可以在它的文档里找到。
对Some封装后的变量进行比较
因为 Some 是一层封装,方便起见,你可以直接使用 Some(3) == Some(3) 这样的表达式。也就是说, Some 需要封装一个变量的引用,它也直接可以比较引用的值:
#![allow(unused)]fn main() {let a = ['a', 'b', 'c', 'a'];let res: bool = Some(&a[0]) == Some(&'a');println!("1) Is Some(&a[0]) == Some(&'a') : {}", res);let res = Some(&a[0]) == Some(&a[3]);println!("2) Is Some(&a[0]) == Some(&a[3]) : {}", res);let res = Some(2) == Some(2);println!("3) Is Some(2) == Some(2) : {}", res);}
上面的输出会是:
1) Is Some(&a[0]) == Some(&'a') : true2) Is Some(&a[0]) == Some(&a[3]) : true3) Is Some(2) == Some(2) : true
然而并不是所有类型都可以直接这样进行比较,只有支持使用运算符 == 的类型,或者说实现了比较的Trait的类型才能享受这种便利。比如,在下面的例子中,使用自定义的元组Struct的Option会产生panic:
#![allow(unused)]fn main() {let st1 = SimpleStruct(5, 2, String::from("1"));let st2 = SimpleStruct(5, 2, String::from("1"));let res = Some(&st1) == Some(&st2);println!("4) Is Some(&st1) == Some(&st2) : {}", res);}struct SimpleStruct(u16, i32, String);
输出将会是类似下面这样的内容:
error[E0369]: binary operation `==` cannot be applied to type `Option<&SimpleStruct>`--> src/main.rs:16:26|16 | let res = Some(&st1) == Some(&st2);| ---------- ^^ ---------- Option<&SimpleStruct>| || Option<&SimpleStruct>error: aborting due to previous errorFor more information about this error, try `rustc --explain E0369`.error: could not compile `playground`To learn more, run the command again with --verbose.
要像解决这一问题,我们可以试着实现比较的Trait:std::cmp::PartialEq
impl PartialEq for SimpleStruct{fn eq(&self, other: &Self) -> bool {self.0 == other.0&& self.1 == self.1&& self.2 == self.2}}// 实现此Trait后,上面的代码输出:// 4) Is Some(&st1) == Some(&st2) : true
如果你只是想要比较各个字段值相不相等的话,你可以直接使用更方便的 #[derive] (前提是字段也是实现了 PartialEq 的):
#[derive(PartialEq)]struct SimpleStruct(u16, i32, String);
输出和上面的手动实现是一样的。如果你还需要比较大小,请尝试用相似的方式实现 std::cmp::PartialOrd 。
如果你熟悉Java的话,你会发现这和Java中的
equals有点像。为什么是
PatialEq? 实际上,Eq也是std::cmp下的一个Trait,很显然,它用于判断 相等关系 而不是 部分相等关系。在这里展开来讲就有点跑题了,你可以参考这两的Trait的文档来获得第一手的理解:上面的代码你可以在Playground中随意摆弄:

若有收获,就点个赞吧
0 人点赞
