译者我喜欢这篇文章的叙述方式,而跳表这一数据结构也很有价值,因此翻译过来。有些段落标题是我自己加的。 原文出处是Hands On Data Structures and Algorithms with Rust一书,作者是Claus Matzinger。
乘地铁出发
我们都爱纽约,这座城市有着不计其数又难以言明的品质,这是一座狂热而生动的城市,充斥着各种文化、出身、种族、活动和机遇。纽约市同样也存在着像欧洲城市那样的大型公共交通网络。
这一切又与跳表何干呢?地铁可以被表示为站点的简单列表(在美国常用街道号码表示):14 -> 23 -> 28 -> 33 -> 42 ->51 -> 59 -> 68。然而纽约地铁有种特快列车,可以减少经停站数,能快速地到达远距目的地。
假如张三想要从14站前往51站,他乘坐特快列车只用经过三站即可到达,而不是普通车需要经停的五站。实际上这正是纽约人在第14大道(联合广场)到51大道使用的4,5,6列车。在乘客看来,地铁规划差不多如下图所示: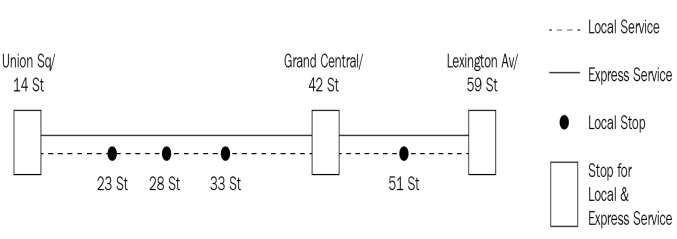
普通车每一站都会停车,而特快车则会跳过小站,仅在共享站点才停车,让乘客有机会进行换乘。特快列车跳过站点的行为只是过而不入,有时候这一点会把游客和土著都迷得团团转。
把上述情况表述为数据结构,就是几组处在不同层级的列表。最低层级的列表包含了所有站点,而高层级则因“特快服务”的跳跃站点行驶得更快。这就形成了多级列表,不同层级仅在特定的节点汇合。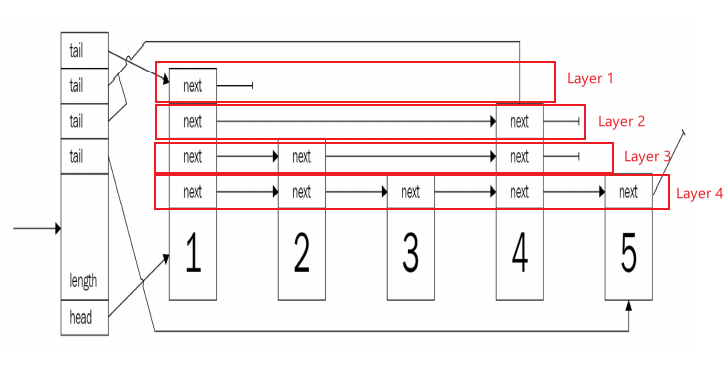
理想情况下,每一层级拥有的节点数量是下一层级节点数量的一半,也就是说需要有一个决策算法来确保列表增长的时候还能维持这种约束。而如果不维持这种约束,搜索时间将会大为逊色,最差情况下就是一个有着巨额开销的普通链表。
节点的级别是使用概率方法确定的:投一枚硬币,如果两次同样的面朝上就增加一个层级。 虽然这会产生我们所需的分布,但这仅在较高级别的节点均匀分布时才有意义。 在深入阅读部分列出了一些改进版的帖子。
除此之外,跳表必须保持有序才能正常工作。毕竟如果列表内的元素顺序是随机的话,跳表又怎么能知道何时去“跳”过呢?不过总的来说,基本跳表的节点差不多长这个样子:
type Link = Option<Rc<RefCell<Node>>>;struct Node{next: Vec<Link>,pub value: u64,}
我们还需要一个列表结构来把节点链接在一起:
struct SkipList {head: Link,tails: Vec<Link>,max_level: usize,pub length: u64,}
这一列表与之前的几种列表(译者指原书中前面章节有关单链表和双链表的内容 )很是相似。有一说一确实,这种关系不可否认,因为它们的属性几乎是一样的。但是也存在着两点不同: tail 是一个 Vec<Link> 而 max_level 则是跳表中的属性。
tail 之所以是一个vector是因为实际上每一层都会有一个尾巴节点,这表明不论何时进行添加节点的行为,所有的尾巴节点都可能要进行更新。此外,开发者负责提供合适的 max_level 值,因为改变 max_level 会产生新的列表。
回到刚才的例子,产品组又来加需求了!用户对列表中清晰的指向不知所谓,而且用户没办法在一开始就快速跳过冗余乏味的环节。
结果就是,产品组想要:
- 一个时间相关的事务日志记录
- 能够快速跳转至给定时间
- 能够从给定时间开始迭代
最佳事务日志
要想提升事务日志到产品组描述的级别,使用跳表最合适不过了。使用 u32 对指令进行排序如何?这个无符号32位整数是从初始时间戳的毫秒偏移值。指令会以字符串来存储,与偏移量相关联。
无论如何,列表和其中的节点是必须要实现的。
相比于先前的实现(单链表更接近一点),这一声明有两点主要不同。首先是 next 是一个数组,因为一个节点在不同层级拥有不同的后继节点。
其次,节点内容先前被命名为 value ,但是为了区别时间戳偏移量和实际内容, value 被 offset 和 command 所取代:
#[derive(Clone)]struct Node {next: Vec<Link>,pub offset: u64,pub command: String,}
这些节点形成了升级版事务日志的根基。而前文中的单链表则是通过创建包含头指针的类型来完成的。
链表
现在的链表最好把长度和元素能拥有的最大层级存储起来,而不是简单放一个头指针了事。这种用户提供的参数是十分关键的,如果最大层级太低,那么搜索性能就和单链表差不多了(O(n))。
而如果最大层级设的太大,节点分布就会不均匀,结果就是在水平和竖直方向上的迭代次数差不多了(O(n+h)),太大太小都不好。
所以就是,参数最好是设置为能体现链表未来大小的值,最高层级最多只包含两到三个节点。
#[derive(Clone)]pub struct BestTransactionLog {head: Link,tails: Vec<Link>,max_level: usize,pub length: u64,}
tail 是指向每一个层级尾巴节点的Vector,当添加新的节点时,这里就是进行更新的主要阵地,这是跳表只能尾部插入的性质决定的。
添加数据
我们需要一个添加数据的方法来使数据结构生效。正如前文所言,跳表只在元素有序的条件下有效,这符合常理:知道去哪才能尽情跳跃!
插入排序是构造有序列表的好办法之一。通常需要增加一些复杂的插入逻辑来寻找节点正确的位置。但是由于时间戳可以进行比较而且是自然降序,事务日志可以不做复杂性插入,因而它需要的测试也较少,过段时间去查看它也不会让人觉得头疼。
实际上这意味着我们完全有可能去重用之前的代码:
pub fn append(&mut self, offset: u64, value: String) {let level = 1 + if self.head.is_none() {self.max_level // use the maximum level for the first node} else {self.get_level() // determine the level by coin flips};let new = Node::new(vec![None; level], offset, value);// update the tails for each levelfor i in 0..level {if let Some(old) = self.tails[i].take() {let next = &mut old.borrow_mut().next;next[i] = Some(new.clone());}self.tails[i] = Some(new.clone());}// this is the first node in the listif self.head.is_none() {self.head = Some(new.clone());}self.length += 1;}
然而这里有一处重大变更:确定节点应该处于哪一个级别。即👆代码的2-6行。
这几行代码披露的细节是:
- 首个节点在所有层级都会出现,这会让搜索更加容易,因为这个算法只需要下降级别就可以了。但是这必须让跳表只增不减才可以。
- 每一个节点的
next列表必须在对应层级的下标上存储后继指针,所以列表实际长度是最大层级+1。
不过怎么确定层级呢?这是个好问题,因为这是跳表良好表现的关键。
升级
因为在跳表中进行搜索和在二分搜索树中进行搜索很像,节点必须满足特定的分布。William Pugh的原始文献中使用投硬币法来获得所需的节点层级分布(五五开的升级概率)。
该算法如下所示(William Pugh, Skip Lists: A Probabilistic Alternative to Balanced Trees, Figure 5):
randomLevel()lvl := 1-- random() that returns a random value in [0...1)while random() < p and lvl < MaxLevel dolvl := lvl + 1return lvl
这个实现十分简单又好理解,所以我们在跳表中也去使用它。但是,也有其他更好的手段来生成节点分布,这一点就留给你来探索了。我们需要外部crate rand 来完成这项任务。
rand由Rust项目提供,但是却拥有自己的代码仓库。肯定有人会有讨论为什么它不再标准库里,不过这样你可以选择其他轻量级的库或者在目标平台不支持时有其他选择。
下面的代码可以产生我们所需的级别:
fn get_level(&self) -> usize {let mut n = 0;// bool = p(true) = 0.5while rand::random::<bool>() && n < self.max_level {n += 1; }n }
参照算法你需要记住:层级的大小区间是 [0, max_level] ,是闭区间。每当有值被插入时,这个方法就会被调用以产生目标层级,所以跳跃使得搜索速度更快。
跳跃
跳表模拟的是二分搜索树,但是不用平衡所带来的开销就能带到O(log n) 的时间复杂度。因为跳表可以跳过节点,这样就不用挨个比较是不是搜索的节点了。更少的节点意味着更少的比较次数,从而减少运行时消耗。
跳跃可以用几个循环来轻松实现:
pub fn find(&self, offset: u64) -> Option<String>{match self.head {Some(ref head) => {let mut start_level = self.max_level;let node = head.clone();let mut result = None;loop {if node.borrow().next[start_level].is_some() {break;}start_level -= 1;}let mut n = node;for level in (0..=start_level).rev() {loop {let next = n.clone();match next.borrow().next[level] {// Ugly as fuckSome(ref next) if next.borrow().offset <= offset => n = next.clone(),_ => break,};}if n.borrow().offset == offset {let tmp = n.borrow();result = Some(tmp.command.clone());break;}}result}None => None,}}

若有收获,就点个赞吧
0 人点赞
