数据集的划分
模型的训练主要依赖于数据集,而如何使用数据集则显得尤为重要。通常情况下,数据集可划分为训练集、验证集和测试集三部分。各部分间的集合关系可由如下结构展示:<br /><br /> 此外,可以用一个形象的比喻来描述三者间的关系:训练集如同课上老师讲解的例题,可以通过例题的讲解学到相应的知识;验证集可类比于课后作业,是对课上掌握知识的一种检验;而测试集则是最终的考试,用来考察“举一反三”的能力,可以判断是否真正学会了这些知识。<br /> 由上述结构和类比我们不难发现,测试集的选取相对容易。它只需要从原始数据集中取出一部分即可。而训练集和验证集则需要进一步的划分,具体的划分方式可以考虑下面提出的“交叉验证法”和“留出法”。
交叉验证法与留出法
交叉验证法
下图所展示的是交叉验证法的执行过程,<br />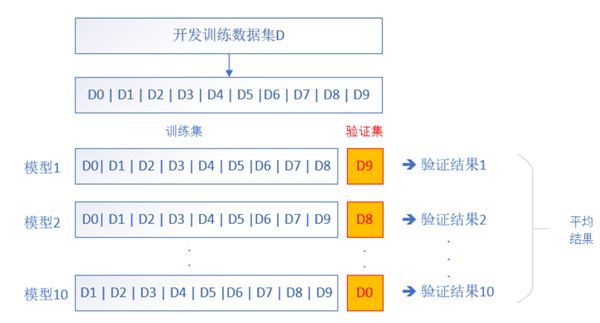<br />具体的执行流程如下:
- 随机将训练数据分成K等份(通常建议K=10),得到D0,D1,……,D10;
- 对于一个模型M,选择D9D_9D9为验证集,其它为训练集,训练若干轮,用D9验证,得到误差E。再训练,再用D9测试,如此N次。对N次的误差做平均,得到平均误差;
- 换一个不同参数的模型的组合,比如神经元数量,或者网络层数,激活函数,重复2,但是这次用D8去得到平均误差;
- 重复步骤2,一共验证10组组合;
- 最后选择具有最小平均误差的模型结构,用所有的D0~D9再次训练,成为最终模型,不用再验证;
用测试集测试。
交叉验证法的主要思想就是:通过划分数据集,让每一部分数据集都有机会成为验证集。通过各自训练的效果,确定出最适合作为验证集的数据部分,并令其成为验证集。
留出法
使用交叉验证的方法虽然比较保险,但是非常耗时,尤其是在大数据量时,训练出一个模型都要很长时间。而在深度学习中,有另外一种方法去选择验证集,该方法被称为留出法。留出法主要是在训练数据集上按照选取测试集的方式,取出部分数据作为验证集,即**从训练数据中保留出验证样本集。**<br />** 该方法主要用于解决过拟合情况,这部分数据不用于训练。如果训练数据的准确度持续增长,但是验证数据的准确度保持不变或者反而下降,说明神经网络亦即过拟合了,此时需要停止训练,用测试集做最终测试。**

若有收获,就点个赞吧
0 人点赞
