引言
之前在阅读论文:Automatic Exposure Correction of Consumer Photographs时发现有提到过Zone System的理论,为了研究需要,想深刻的理解一下这个理论,以及这个理论在计算机视觉中的应用
分区曝光理论
美国著名摄影家安塞尔·亚当斯的区域曝光理论 ,在《负片与照片》一书中对此曾作了详尽的表述。
黑白照片的色调或灰调可以分为十一个“区域”,由零区域(相纸能够表现出的最黑的部分)至第十区域(相纸的底色——白色)。第五区域是中等的灰度,它可以根据测光表的读数曝光而得出来;第三区域是有细节的明影部分,而第八区域则是有细节的强光部分。
一个简单的例子,就是量度阴影部分的光量,为使这部分能够有更多细节,并将光圈增大两级;然后量度重要强光部分的光量,按照区域系统理论,强光部分比阴影部分亮了五级,如果明影部分是第三区域的话,强光部分便是第八区域。倘若这是摄影者的构思,便可以马上进行拍摄。要是想使强光部分有更多层次,摄影者可以缩短底片的显影时间来减低反差,使第八区域变为第七区域。相反地,如果想使重要阴影部分有更多层次,而这部分又比较明亮部分暗了三级,显影时便可增加时间以增大照片的对比度,从而使强光部分变得更亮。 
官方百科的描述有些粗略和僵硬,这边有个老哥的帖子整理的还是不错的,10年的帖子,这位大佬是真的有自己的理解:
http://cache.baiducontent.com/c?m=LF6naA_KetkJM9Xsg5khinP7wN5dn-eSvSJoVLIBXFIjx6LZbnWCFeNX_j9Km09kg5uzCzlC4HhrJZfWCsrpBtrutEutPnmEdqlCwfxrcDO&p=8b2a970e9e8513e403bd9b7d0c1385&newp=9e49c31b82df12a05abd9b7d0c1382231610db2151d1d2126b82c825d7331b001c3bbfb422201b0ed8ce766007af4c5dedf03075370923a3dda5c91d9fb4c57479&s=cfcd208495d565ef&user=baidu&fm=sc&query=%B7%D6%C7%F8%C6%D8%B9%E2%C0%ED%C2%DB&qid=abb0d08e00516cf1&p1=4
看了他的帖子,我学到的点是:
如果一定要修正,应该是“分区测光及冲印调整法”。说白了,ZS的精髓存在于两个部分,一是测光,二是冲洗。缺一不可。
分区曝光法里 物体所对应的分区,其实是我们所期待的正常曝光下,物体在图像上的亮度的表现情况。
为什么要涉及到冲洗呢?
本质原因:在冲洗时,亮区域 和 暗区域 受冲洗时间变化影响的大小 不相同;暗处影响不大,亮处影响明显
这一点的应用:我们拍摄时往往 根据侧光 和 主要物体区域的选择,来确立了曝光光圈设置,同时尽可能的先去满足暗处区域的分区靠近理想的区域,这样可能会有部分内容,大概率是亮的区域,对于这部分区域,会很白,但是我们可以通过明显缩短的冲洗时间来实现跨度较大的曝光分区调整。从而使我们的摄影师能够拍摄出想要的效果的图片。
那么这个理论在目前数码摄影为主的时代中,是否还有用呢?或者直接的说,在我们的视觉领域,指导相机或者来模拟人对图像的曝光进行细致的评估时,是否还有用呢?
思考我们人对于曝光的评估,和分区曝光理论中保持一致的是,我们的目的不变,对于同样的物体,同样的景物布置,我们所期望的,各物体在图像中最后所表现得到的亮度等级是一致的。
我们是怎么确定一个物体所应该具有的曝光分区等级,这个主要是依据经验主义,一般来说图像中的某个物体,我们见到了之后会和记忆中同类物体进行比对,平常这个物体的亮度水平应该是什么样的,他的在图中的颜色,他的表面和图片中其他物体表现出来的差距,这些信息都会辅助我们对这个物体本身所应该处在的一个分区等级进行判断。
对,所以这个等级还是对我们的结果有指导意义,但是对我们相机参数的调整是否有意义呢?
我个人目前的愚见:是有的,当前智能相机的好处就是ISP模块处理快,结果出的快,确实能包围的动态范围也比之前的强了,我们可以在后期处理,或者评价时依然采用这个作为一个基准进行合理的评价,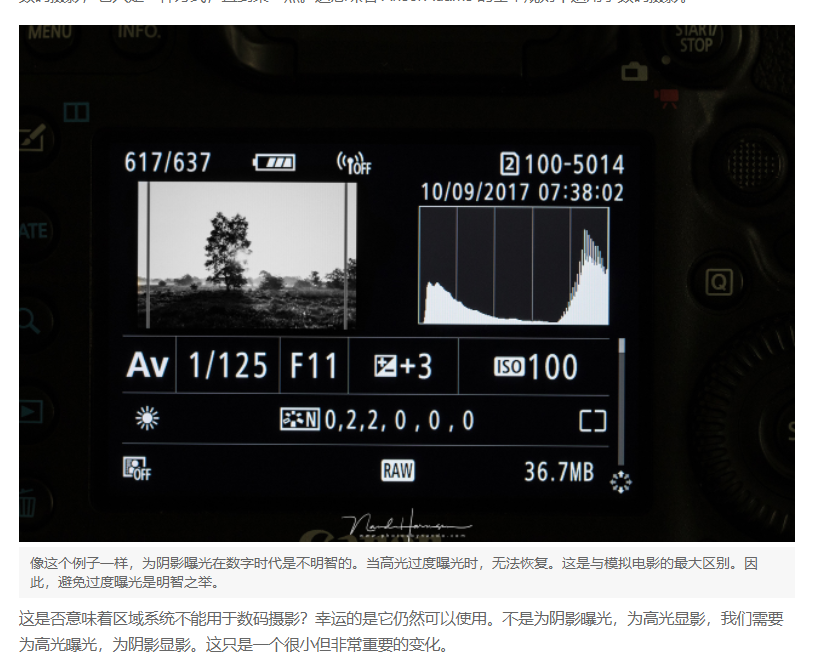
一个是物体本身的反射率的估计,还有一个是环境光源给到物体上的光量的大小,这两个共同决定了相机曝光参数的调整范围。
然后我去谷歌了一下这个理论,发现国外很多摄影学者都对这个理论有着独到的理解,哪怕是在今天数码相机的时代
https://fstoppers.com/education/how-use-ansel-adams-zone-system-digital-world-417047
这个文章的作者就对分区曝光理论在目前的应用有了解释
分区曝光理论-科研应用
在微软亚洲研究院的Automatic Exposure Correction of Consumer Photographs中有采用。
首先按照亮度将图像进行分区处理
在每个区域,平均强度值称为其对应的曝光。(注意,这里将亮度值和曝光进行了一个等号处理)
首先将图像按照形状预先分割,然后合并区域,同时为区域赋予优先级(优先级高的区域优先靠近5,我猜是要这样)
最优区域估计可表示为全局优化问题,需要考虑两个方面:最大化视觉细节和保持相邻区域之间原始的相对对比度。
曝光不足/过度区域的可见细节量可以通过在输入图像I上应用不同的伽马曲线产生的这些图像中检测到的边缘的差异来测量;
利用区域的强度直方图距离来测量区域之间的相对对比度。这个距离被定义为两个直方图的最小移动距离,以最大化它们的交集(如图5所示)。
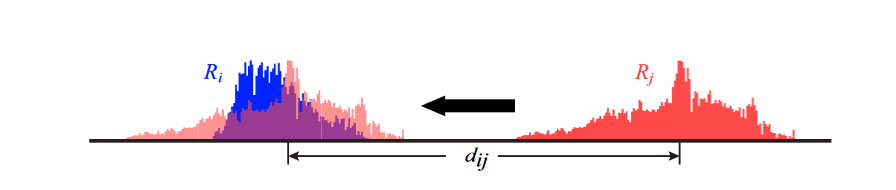
定义完成这两个量后,作者将分区估计问题转变为一个图的标记问题
分区曝光理论-我的理解与应用方式
对于这个理论,目前我感觉科研界对他的应用还只是停留在表面,为什么?
Answer: 1.在应用时,我们看上述论文的核心:首先是.分区,分等级的应用:将亮度划分为区,然后相似的块进行合并;其次是相邻块之间的相邻对比度的设定。这个应用首先很巧妙,但是看过原本理论的可以发现,这个确实只是利用了皮毛,不过创新性也是很不错的了。
那么我会如何将这个理论应用到目前的cv研究中呢?
其实还是得仔细思考人在分区曝光法里评价图像某个区域的曝光的方式:
- 我知道这个是啥
- 我对这个东西本身的表面和所处的环境有个初步的估计
- 我将我的估计和当前的进行比对
- 我得到我的结论
那么我的模型就从模拟这四个步骤出发进行判断
至于后期的调整,可以向专业摄影师学习

若有收获,就点个赞吧
0 人点赞
