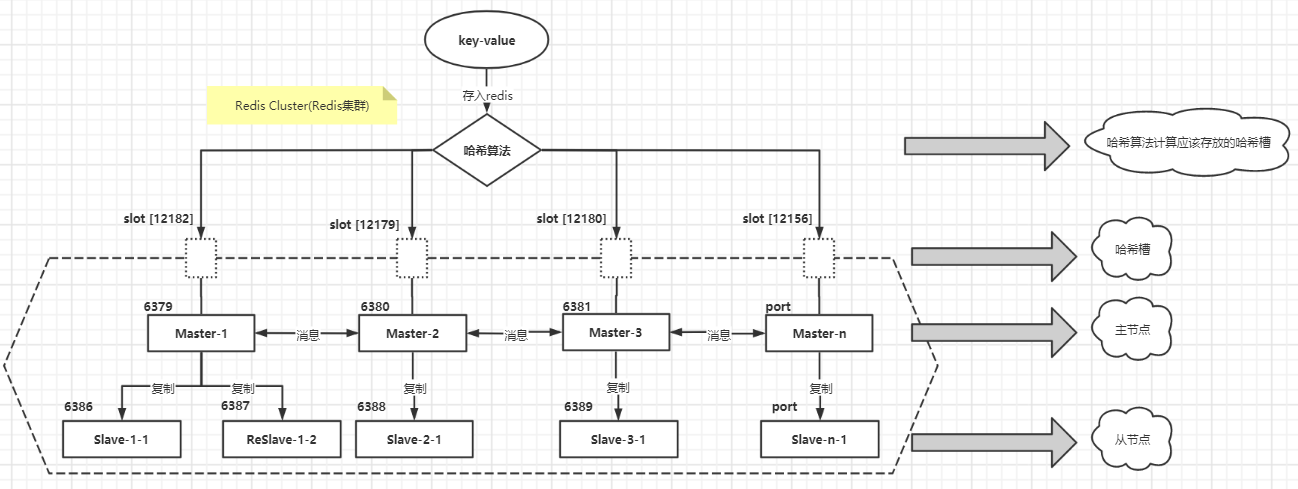
什么是Redis集群?
上一篇文章我们学习了Redis的主从复制和哨兵模式的应用以及原理,我们知道Redis主从复制的主要作用是实现数据热备份以及服务的高可用,利用读写分离实现负载均衡,很大程度上缓解了Redis实例的读写压力。
但是由于主从复制读写分离仅允许存在一个主节点,且主节点可以同时提供读和写的操作,当应用频繁对redis进行写入,且数据量非常大的时候,对于主节点来说数据量以及操作压力都是非常大的,而这也是主从复制无法解决的问题。
Redis3.0之后支持集群部署,**Redis集群是Redis分区的其中一种分布式实现方式,通过部署多个平等的Redis实例**,构建Redis集群,存入的Key-Value数据通过特定哈希算法被存入其中一个Redis实例,每个Redis实例存放的数据是整个Redis集群数据的子集。
Redis集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点,当然,各平等节点可以独立搭建主从复制结构。**
Redis集群内平等节点之间会互相通信,以确认集群节点的状态信息。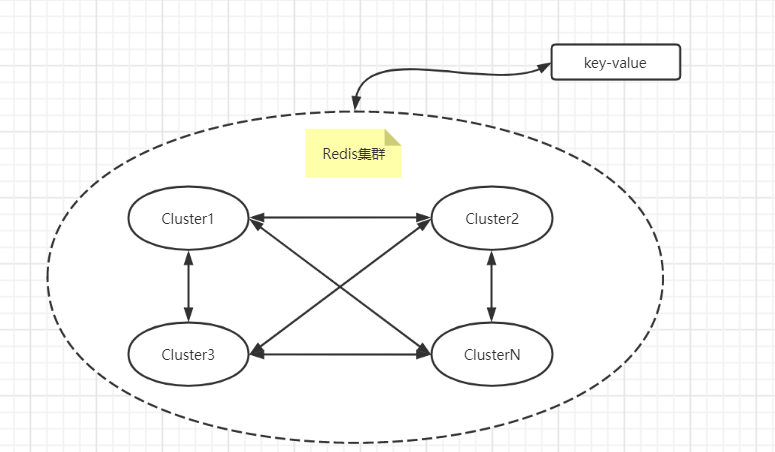 **
**
Redis分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集。
Redis 有两种类型分区:
一种是范围分区:通过范围划分key应该存放到哪个实例中,比如,ID从0到10000的用户会保存到实例R0,ID从10001到 20000的用户会保存到R1,
一种是哈希分区:通过一定的算法(与哈希有关)计算key应该存放到哪个实例中
Redis集群的应用场景
主从复制+哨兵模式:数据量不大,读写不会太频繁,一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,然后自己搭建哨兵,去保证redis主从架构的高可用性
Redis集群:主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster
Redis集群搭建
准备实例并修改配置
我们事先准备三个Redis实例(至少三个),作为Redis集群的成员,分别是:
Redis-Master1:6379
Redis-Master2:6383
Redis-Master3:6384**
要搭建Redis集群,只需要修改三个实例中的几个配置:
port 6379 #端口cluster-enabled yes #启用集群模式cluster-config-file nodes_6379.conf # 集群配置文件,启动会自动生成cluster-node-timeout 5000 #超时时间daemonize yes #后台运行pidfile /var/run/redis_6379.pid
启动Redis实例
分别修改完三个Redis对应的端口以及集群配置之后,启动三个Redis实例
./redis-master1/src/redis-server ./redis-master1/redis.conf & # 启动redis-master1节点./redis-master2/src/redis-server ./redis-master2/redis.conf & # 启动redis-master2节点./redis-master3/src/redis-server ./redis-master3/redis.conf & # 启动redis-master3节点

创建集群
在Reids5.0之前,为我们需要使用ruby工具创建集群【本文使用的环境是Redis4.0.11】
我们看到./redis-master1/utils/create-cluster目录下有一个脚本文件create-cluster
该脚本内部有一个语句如下,表明启用redis集群需要使用到redis-trib.rb脚本文件
if [ "$1" == "create" ]thenHOSTS=""while [ $((PORT < ENDPORT)) != "0" ]; doPORT=$((PORT+1))HOSTS="$HOSTS 127.0.0.1:$PORT"done../../src/redis-trib.rb create --replicas $REPLICAS $HOSTSexit 0fi
redis-trib.rb脚本文件位于src目录下:
我们试一下直接执行启动命令:
./redis-master1/src/redis-trib.rb create 127.0.0.1:6379 127.0.0.1:6383 127.0.0.1:6384
报无ruby工具错误,表明redis-trib.rb脚本文件是需要ruby工具执行
安装ruby工具【Redis4.0.11要求ruby版本>=2.3.0】
yum install ruby
安装完成后测试是否安装成功:
此处看到yum安装ruby默认版本为2.0.0,下面需要升级ruby:
yum install centos-release-scl-rh #安装yum源yum install rh-ruby24 -y # 2后面4的指定要安装的版本号scl enable rh-ruby24 bash # 使当前版本生效
升级完成后查看版本号:
安装rubygems
yum install rubygems
使用gem安装集群依赖
gem install redis
正式创建集群
./redis-master1/src/redis-trib.rb create 127.0.0.1:6379 127.0.0.1:6383 127.0.0.1:6384

如果此时报错误:
[ERR] Node 127.0.0.1:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
这是由于Redis存在快照文件【dump.rdb】或内存持久化文件【appendonly.aof】,由于我没有开启内存持久化,所以删除redis目录下的dump.rdb即可:
如果删除后创建集群还是报错就需要将对应节点的数据清除了:
./redis-master1/src/redis-cli -p 6379flushall

再次创建集群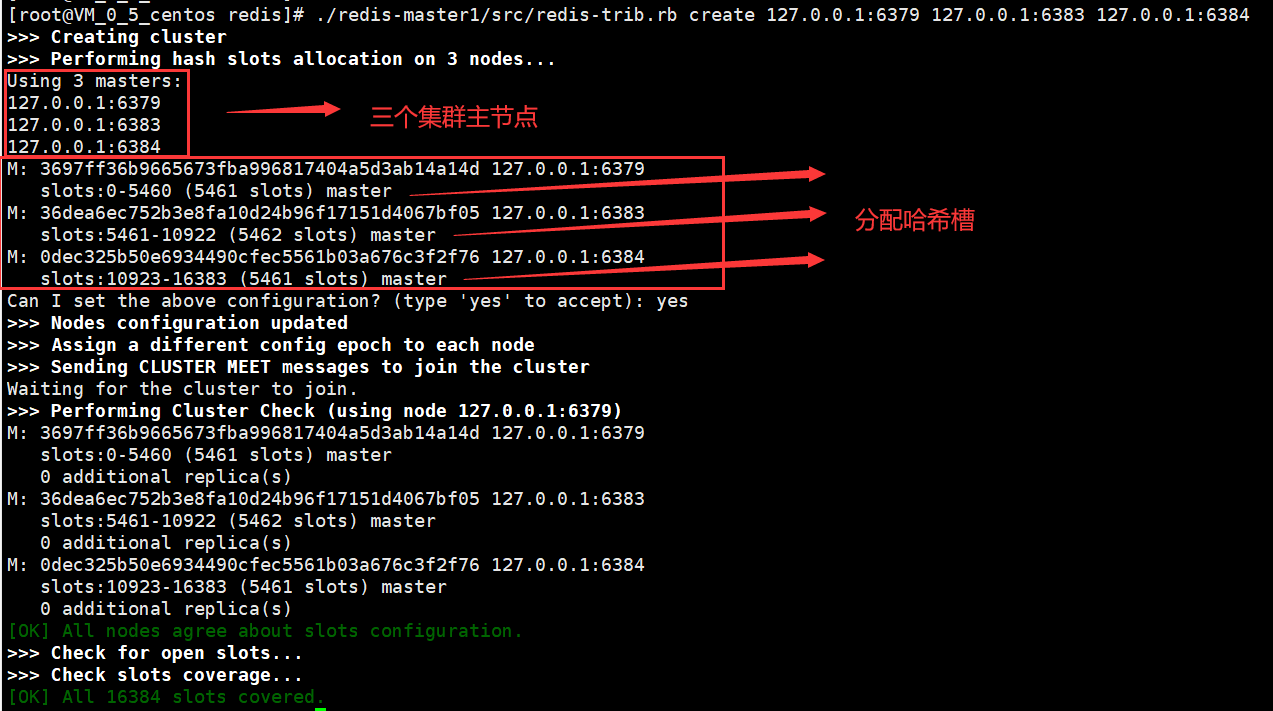
集群创建成功,哈希槽分配到了每个节点上【哈希槽后续文章讲解】
在Redis5.0之后,Redis提供了更为方便的集群启动方式
./redis-master1/src/redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
测试存取数据
向Master1(6379)存入key-value对:**
./redis-master1/src/redis-cli -c -p 6379 # -c表示启动集群模式,如果不使用该参数,会导致写数据报错127.0.0.1:6379> set halo xiaoming-> Redirected to slot [9028] located at 127.0.0.1:6383 # 根据计算得出的哈希槽重定向到6383节点OK # 存入成功127.0.0.1:6383> get halo # 自动重定向到了6383节点,进行查询"xiaoming"

前往Master3(6384)查询数据:
./redis-master1/src/redis-cli -c -p 6384127.0.0.1:6384> get halo-> Redirected to slot [9028] located at 127.0.0.1:6383 # # 根据计算得出的哈希槽重定向到6383节点"xiaoming" # 结果获取成功127.0.0.1:6383> # 自动重定向到了6383节点

Redis集群原理
如何实现数据分区?
从实践测试中,我们看到,每个Redis存放总数据的其中一部分数据,那么怎么确定存入的数据应该放在哪个Redis节点呢?
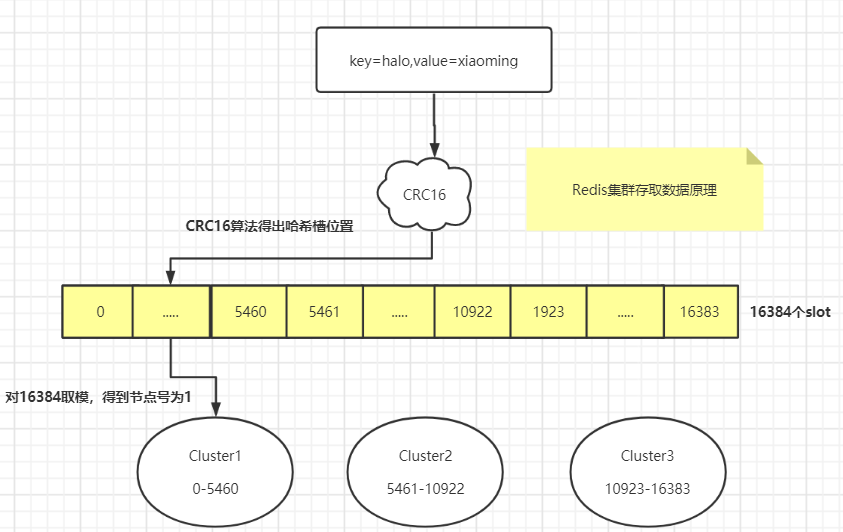
Redis3.0之后支持集群,同时提出了哈希槽(hash slot)的概念,整个Redis集群总共有16384个哈希槽,集群搭建的时候,为每个Redis主节点都分配了不同范围的哈希槽。
如下图中,6379节点对应的哈希槽范围为0-5460,共5461个哈希槽
6383节点对应的哈希槽范围为5461-10922,共5462个哈希槽
6384节点对应的哈希槽范围为10923-16383,共5461个哈希槽
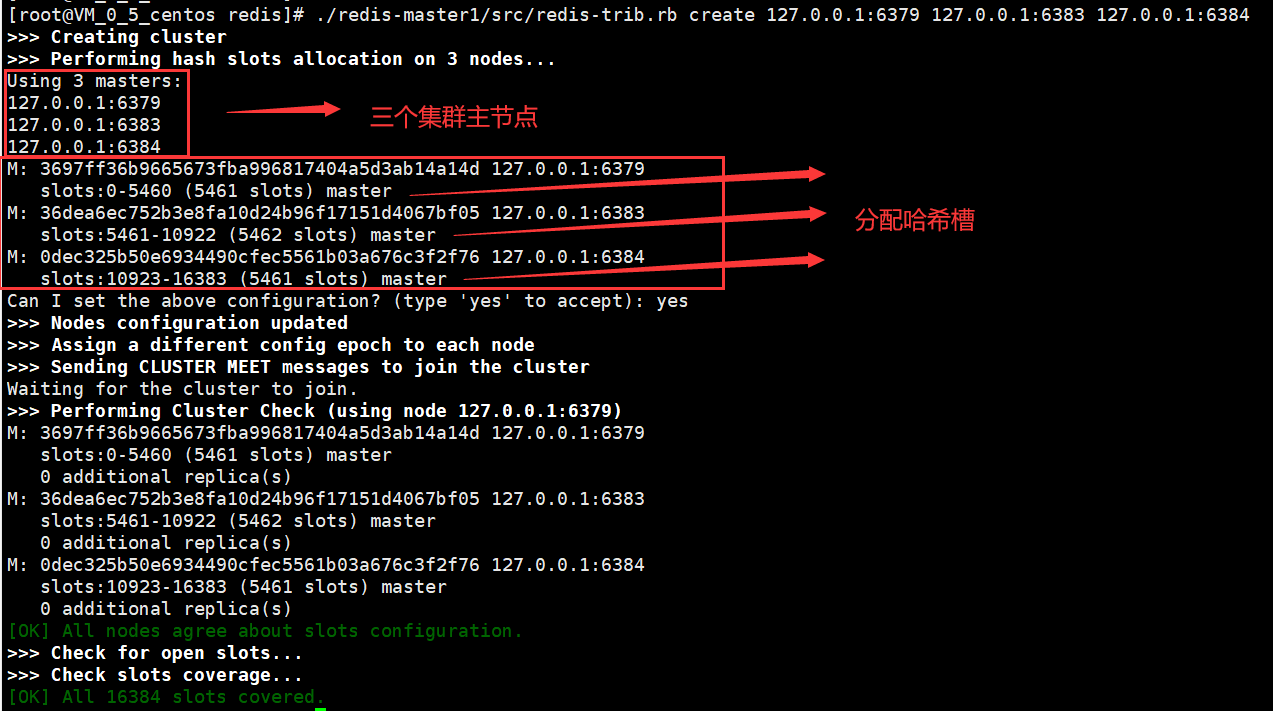
当我们的存取的key到达的时候,Redis会根据CRC16哈希算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
节点之间如何通信?
Redis集群之间是会互相通信以确保整个集群状态的可用,也就是说,每个Redis主节点都会知道其余任意一个Redis主节点的状态和信息,这个过程是怎样的呢?
Redis集群采用P2P的Gossip协议,节点之间不断地通信交换信息,而这个过程中发送的消息和回应类型如下:
1、**ping消息**:集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节 点,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。除此之外,如果节点A最后一次收到节点B发送的PONG消息的时 间,距离当前时间已经超过了节点A的cluster-node-timeout选项设置时长的一半,那么节点A 也会向节点B发送PING消息,这可以防止节点A因为长时间没有随机选中节点B作为PING消 息的发送对象而导致对节点B的信息更新滞后
2、pong消息:当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者确认这条MEET消息或者PING消息已到达,接收者会向发送者返回一条PONG消息,pong消息内部封装了自身状态数据。另外,一个节点也可以通过向集群广播自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识,例如当一次故障转移操作成功执行之后,新的主节点会向集群广播一条PONG 消息,以此来让集群中的其他节点立即知道这个节点已经变成了主节点,并且接管了已下线 节点负责的槽(如果部署了主从复制的话)
3、**meet消息**:当发送者接到客户端发送的CLUSTER MEET命令时,发送者会向接收者 发送MEET消息,请求接收者加入到发送者当前所处的集群里面
4、fail消息:当一个主节点A判断另一个主节点B已经进入FAIL状态时,节点A会向集群 广播一条关于节点B的FAIL消息,所有收到这条消息的节点都会立即将节点B标记为已下线
5、forget消息:忘记节点消息,使一个节点下线。这个命令必须在60秒内在所有节点执行,否则超过60秒后该节点重新参与消息交换。实践中不建议直接使用forget命令来操作节点下线。
节点故障如何处理?
我们从上面看到了主节点之间是在不断通信中的,那就意味着每个主节点都充当了哨兵的一个角色,那处理故障之前我们需要知道,怎么判断节点故障了呢?
判断节点宕机
类似于哨兵模式,Redis集群中如果一个主节点A认为另外一个主节点B宕机,也就是说,当在cluster-node-timeout内,B节点一直没有返回pong,那么就被认为该节点pfail,主观宕机
接着A会在gossip ping消息中,将这个信息ping给其他节点
如果超过一半主节点认为另外一个主节点pfail了,那么认为该节点就是ofail,客观宕机
从节点过滤
当一个主节点B被判定为客观宕机时,**如果配置了从节点【本文实例中没有配置主从复制】,由Redis集群从从节点选择一个升级为主节点,类似于哨兵模式,进行自动故障转移
检查B主节点下的每个从节点与B断开连接的时间,如果超过了cluster-node-timeout cluster-slave-validity-factor,那么就没有资格升级为master*
从节点选举
**
集群里面的所有主节点都充当了哨兵的身份,那就需要由除了宕机节点之外的所有主节点在宕机主节点的从节点中选举一个从节点进行升级。
选举规则:
每个从节点,都根据自己对master复制数据的偏移量【即复制数据的完整性】,来设置一个选举时间,偏移量越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举
所有主节点开始选举投票,给要进行选举的从节点进行投票,如果超过半数主节点都投票给了某个从节点,那么选举通过,那个从节点与所属主节点进行主从切换
集群故障如何处理?
上面从节点层面讲了一个主节点如果故障了,Redis集群的处理机制
那什么情况下,Redis集群的层面会发生故障【即集群进入fail状态】呢?
1、某个主节点和所有从节点全部挂掉,我们集群就进入faill状态。
2、如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
3、如果集群任意master挂掉,且当前master没有slave.集群进入fail状态
也就是说,Redis集群需要保障任何一个哈希槽分配范围都是可用的,当某个主节点宕机,如果有从节点可以保证服务,那就不会导致集群故障。
Redis集群相关配置
cluster-enabled yes #启用集群模式cluster-config-file nodes_6379.conf # 集群配置文件,启动会自动生成cluster-node-timeout 5000 # 判断节点失效(fail)之前,允许不可用的最大时长(毫秒),如果master不可用时长超过此值,则会被failover。cluster-slave-validity-factor 0 # 如果要最大的可用性,值设置为0。定义slave和master失联时长的倍数,如果值为0,则只要失联slave总是尝试failover,而不管与master失联多久。失联最大时长:(cluster-slave-validity-factor*cluster-node-timeout)
redis-trib相关命令
# 普通创建集群,不分配从节点redis-trib.rb create 127.0.0.1:6379 127.0.0.1:6383 127.0.0.1:6384# 创建集群,并为每一个主节点分配一个从节点【replicase 1指定从节点个数为1】redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6380 127.0.0.1:63881 127.0.0.1:6382# 添加主节点,7006是新增节点,6379是集群任一老节点,配置用于通知加入集群redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:6379# 添加从节点,--master-id指定主节点id,7007是新增从节点,7006是主节点redis-trib.rb add-node --slave --master-id 2b7bb3be16460f2e0848c69cef3acc68f655a041 xxx:7007 xxx:7006# 为新增的主节点分配哈希槽,如果不分配,则不会被选择存取数据redis-trib.rb reshard xxx:7006
注:本文仅搭建了最简单的Redis集群,主从复制没有搭建,各位有兴趣可以自行搭建学习,多多指教

若有收获,就点个赞吧
0 人点赞
