缓存雪崩
概念
缓存雪崩指的是同一时间**内缓存数据大面积过期失效**,导致后续请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。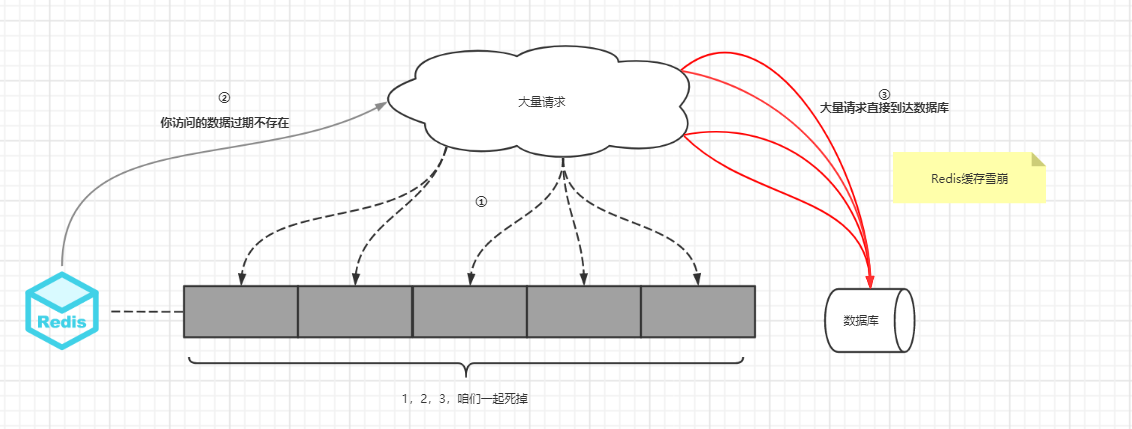
解决方案
1、缓存数据的过期时间设置随机值,降低同一时间大量数据过期的概率
2、如果并发量不是特别多,可以考虑加锁排队
public object getMyBook(){int cacheTime = 30;String cacheKey = "book_list";String lockKey = cacheKey;Object cacheValue = cacheHelper.get(cacheKey);// 如果缓存中的值尚未失效if (cacheValue != null){return cacheValue;}else{// 锁定synchronized (lockKey){// 双重保障cacheValue = cacheHelper.get(cacheKey);if (cacheValue != null){return cacheValue;}else{cacheValue = getBookListFromDB(); //这里一般是 sql查询数据。cacheHelper.add(cacheKey, cacheValue, cacheTime);}}return cacheValue;}}
加锁排队的方式仅仅为了减轻数据库压力(不会同时有大量请求直接到达数据库),但是没能提高系统吞吐量。
高并发场景下,大多数请求被阻塞,用户访问依旧超时,且可能引发分布式环境的分布式锁问题,用户体验不佳,一般不采用
3、添加缓存过期标识,如果缓存过期会触发线程后台查询数据库更新key缓存。另外,设置数据缓存过期时间=缓存标识过期时间2,这样,*当缓存标识过期,实际缓存还能返回旧数据,等待后台线程更新缓存完成后,才返回新缓存。
public object getMyBook(){int cacheTime = 30;String cacheKey = "book_list";//缓存标识,存放于redis中,标识某个key是否过期String cacheSign = cacheKey + "_sign";// 获取缓存标识Object sign = cacheHelper.get(cacheSign);//获取缓存值var cacheValue = cacheHelper.get(cacheKey);// 当缓存标识不为空,则表示目标key未过期if (sign != null){return cacheValue; //未过期,直接返回。}else{// 先将当前key的缓存标识置为非空,即尚未过期,有效时间cacheTimecacheHelper.add(cacheSign, "1", cacheTime);// 后台线程访问数据库并更新缓存ThreadPool.QueueUserWorkItem((arg) =>{cacheValue = getBookListFromDB(); //这里一般是 sql查询数据。cacheHelper.add(cacheKey, cacheValue, cacheTime*2); //日期设缓存时间的2倍,用于脏读。});// 返回缓存值【如果后台线程没有执行完,这里返回的是旧值】return cacheValue;}}
这样去处理,可以一定程度上提高系统吞吐量
缓存击穿
概念
缓存击穿指的是缓存中某个数据没有而数据库中有【一般是缓存过期了】,瞬时所有关于这个数据的请求都落到了数据库上,造成数据库压力过大。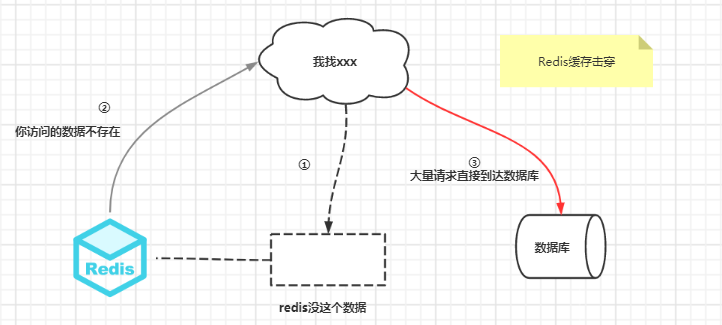
解决方案
1、设置热点数据永不过期
热点数据指的是某一时间会有大并发访问的数据,如电商爆款产品。这些数据设置缓存永不过期
缺点是占用内存,但是安全一些,逻辑上可以做个定时任务定时更新缓存,避免数据库压力过大
2、加互斥锁【**mutex key**】
该方法是比较普遍的做法,即在根据key获得的value值为空时,先锁上,再从数据库加载,加载完毕,释放锁。若其他线程发现获取锁失败,则睡眠50ms后重试。
单机环境用并发包的Lock类型就行,集群环境则使用分布式锁( redis的setnx)
public String get(key) {String value = redis.get(key);if (value == null) { //代表缓存值过期// 调用redis的setnx命令设置一个固定的key_mutex,相当于为key上了锁// 这个方法只有在redis中不存在对应key的时候才会返回true// 否则返回false,从而保证同一时间仅有一个线程在在执行if里面的内容// 设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load dbif (cacheHelper.setNx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功value = getBookListFromDB();cacheHelper.add(key, value, expire_secs);cacheHelper.del(key_mutex); // 删除固定key_mutex,相当于解除对于key的锁} else { // 当目标key已经有线程在占用从数据库获取数据// 当前请求休眠50秒sleep(50);// 重试get(key);}} else {return value;}}
这种方式优点是思路简单,保证数据一致性,缺点是代码复杂,可能导致死锁
缓存穿透
概念
缓存穿透指的是访问**缓存和数据库中都没有的数据**,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
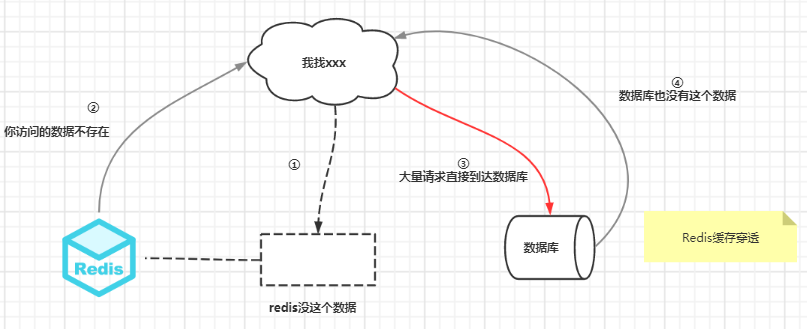
解决方案
1、如果数据库中不存在则短时间缓存一个空值,下次请求就会走缓存
public object getMyBook() {int cacheTime = 30;String cacheKey = "book_list";Object cacheValue = cacheHelper.get(cacheKey);if (cacheValue != null){return cacheValue;}else{cacheValue = getBookListFromDB(); //数据库查询不到,为空。if (cacheValue == null){cacheValue = String.Empty; //如果发现为空,设置个默认值,也缓存起来。}cacheHelper.add(cacheKey, cacheValue, cacheTime);return cacheValue;}}
2、布隆过滤器:将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
**
我们也可以自己设计布隆过滤器,将必定不存在的数据存入单独的缓存,在请求到达的时候首先校验要查询的key,然后再放行给后面的正常缓存处理逻辑。
总结区别与解决方案
| 问题 | 维度 | 原因 | 解决方案 |
|---|---|---|---|
| 缓存雪崩 | 大面积数据 | 同一时间内缓存数据大面积过期失效,导致后续请求都落到数据库上 | 1、过期时间设置随机值 2、加锁排队 3、添加缓存过期标识 |
| 缓存击穿 | 单个数据 | 缓存中某个数据没有而数据库中有,瞬时所有关于这个数据的请求都落到了数据库上 | 1、热点数据永不过期 2、**互斥锁** |
| 缓存穿透 | 单个数据 | 访问缓存和数据库中都没有的数据,导致所有的请求都落到数据库上 | 1、短时间缓存空值 2、布隆过滤器 |
相关概念
缓存预热
缓存预热就是系统上线后,事先将相关的缓存数据直接加载到缓存系统。这样避免,用户请求的时候,再去数据库加载相关的数据。
实现方案:
1、直接写个缓存刷新页面,上线服务时手动调用即可【建议】
2、项目启动自动加载【数据量不大的时候可以】
3、定时任务刷新缓存
热点数据和冷数据
热点数据:指**在redis数据库中修改频率不高,但读取频率很高的数据
冷数据:指的是大部分还没有被再次访问就已经无用的数据,不仅占用内存,且价值不大
一般数据更新前至少读取两次,缓存才有意义。这个是最基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。
比如:商城爆款推荐数据、论坛点赞数、评论数、分享数就属于热点数据,每个用户打开都需要去访问,且频率极高
而其他比如特别偏门的数据比如业务数据【积分细则等】就属于冷数据,不会怎么访问
热点key
缓存中的某些Key(可能对应用某个促销商品)对应的value存储在集群中一台机器,使得所有流量涌向同一机器,成为系统的瓶颈,该问题的挑战在于它无法通过增加机器容量来解决。就拿Redis-cluster集群方案来说,它可能会导致整个集群流量不均衡,个别节点访问量极大,甚至超出承受能力。
产生原因:
1、突发事件导致某个数据被大量访问,如双十一活动抢购
2、Redis分区过于集中,导致热点数据集中在某个Server上,人为加重负载压力
危害:
1、流量过于集中,超出主机网卡上限,可能导致Redis服务器宕机
2、可能导致缓存雪崩和缓存穿透问题【热点key失效导致请求同步】
解决方案:
1、拆分数据结构:将复杂的数据结构比如哈希类型,当哈希集合元素个数较多的时候,可以考虑将当前结构进行拆分,这样热点数据可以拆分成若干个不同的key分不到不同的Redis节点,减轻压力
2、多点备份热key:把热点key在多个redis上都存一份,有热key请求进来的时候,我们就在有备份的redis上随机选取一台
3、将热点key存放在本地缓存,针对这种热点key从本地JVM取出比Redis更快

若有收获,就点个赞吧
0 人点赞
